





In my previous post, I described the various approaches and patterns to consider when ingesting data from a relational data sources into a Hadoop-based hive data lake. In this post I’ll describe a practical approach on how to utilize these patterns with the SnapLogic Elastic Integration Platform without the need to write code. The big data ingestion layer patterns described here take into account all the design considerations and best practices for effective ingestion of data into the Hadoop hive data lake. These patterns are being used by many enterprise organizations today to move large amounts of data, particularly as they accelerate their digital transformation initiatives and work towards understanding what customers need.
Let’s consider a scenario in which you want to ingest data from a relational database (like Oracle, mySQl, SQl Server, etc.) into Hive. Let’s say we want to use AVRO as the data format for the Hive tables. Let’s now look at how this pattern enables you to automatically generate all the required AVRO schemas and the Hive tables.
The key steps associated with this pattern are as follows:
- Provide the ability to select a database type like Oracle, mySQl, SQlServer, etc. Then configure the appropriate database connection information (such as username, password, host, port, database name, etc.)
- Provide the ability to select a table, a set of tables or all tables from the source database. For example, we want to move all tables that start with or contain “orders” in the table name.
- For each table selected from the source relational database:
- Query the source relational database metadata for information on table columns, column data types, column order, and primary/foreign keys.
- Generate the AVRO schema for a table. Automatically handle all the required mapping and transformations for the column (column names, primary keys and data types) and generate the AVRO schema.
- Generate DDL required for the Hive table. Automatically handle all the required mapping and transformations for the columns and generate the DDL for the equivalent Hive table.
- Save the AVRO schemas and Hive DDL to HDFS and other target repositories.
- Create the Hive table using the DDL
The SnapLogic pattern to automatically generate the schema and Hive DDL is below. It can be used as part of your Ingest data flow pipeline to move data from a relation data source to Hive.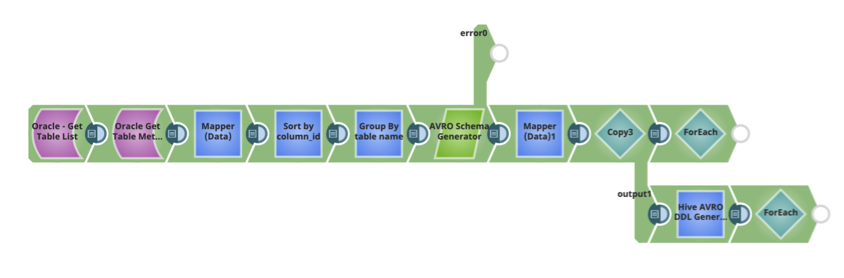
For each table, Avro schemas and Hive table DDLs are also stored in HDFS. 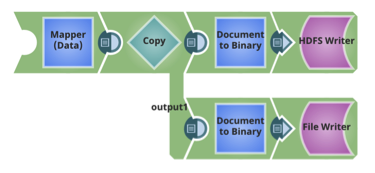
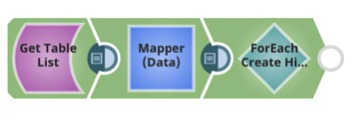
For each table, create the Hive table, using the Hive DDL and AVRO schema.
 The SnapLogic integration Patterns catalog provides prebuilt, reusable integration data flow pipelines that enable reusability and improve productivity.
The SnapLogic integration Patterns catalog provides prebuilt, reusable integration data flow pipelines that enable reusability and improve productivity.
In my next post I will write about another practical data integration pattern for big data ingestion with SnapLogic without the need to do any coding.
Next steps:
- Download the whitepaper: How to Build an Enterprise Data Lake: Important Considerations Before You Jump In. You can also watch the recorded webinar and check out the slides on the SnapLogic blog.
- Download the whitepaper: Will the Data Lake Drown the Data Warehouse?
- Check out this demonstration of SnapReduce and the SnapLogic Hadooplex to learn about our “Hadoop for Humans” approach to big data integration.


