





A common pattern that a lot of companies use to populate a Hadoop-based data lake is to get data from pre-existing relational databases and data warehouses. When planning to ingest data into the data lake, one of the key considerations is to determine how to organize a data ingestion pipeline and enable consumers to access the data. Hive and Impala provide a data infrastructure on top of Hadoop – commonly referred to as SQL on Hadoop – that provide a structure to the data and the ability to query the data using a SQL-like language.
Before you start to populate data into say Hive databases/schema and tables, the two key aspects one would need to consider are:
- Which data storage formats to use when storing data? (HDFS supports a number of data formats for files such as SequenceFile, RCFile, ORCFile, AVRO, Parquet, and others.)
- What are the optimal compression options for files stored on HDFS? (Examples include gzip, LZO, Snappy and others.)
Next, when designing the Hive database schemas, typically you are faced with the following:
- Create the Hive database schema the same as the relational database schema. This enables one to quickly ingest data into Hive with minimal effort for mapping and transformations as part of your ingest data flow pipelines.
- Create a new database schema that is different from the relational database schema. This enables one to redesign the Hive database schema and eliminate some of the shortcomings of your current relational database schema. This also increases the effort for mapping and transformation of data as part of your ingest data flow pipelines.
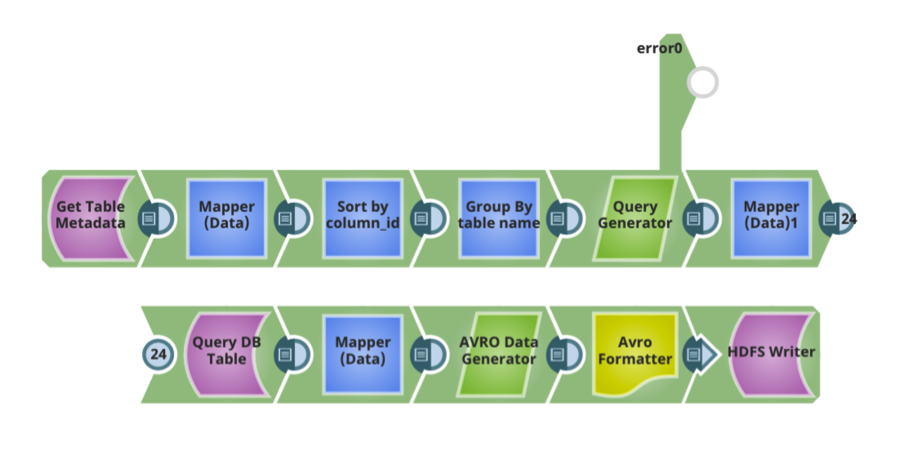 Typically we have seen that Hive schema being created similar to the relational database schema. Once the Hive schema, data format and compression options are in place, there are additional design configurations for moving data into the data lake via a data ingestion pipeline:
Typically we have seen that Hive schema being created similar to the relational database schema. Once the Hive schema, data format and compression options are in place, there are additional design configurations for moving data into the data lake via a data ingestion pipeline:
- The ability to analyze the relational database metadata like tables, columns for a table, data types for each column, primary/foreign keys, indexes, etc. Every relational database provides a mechanism to query for this information. This information enables designing efficient ingest data flow pipelines.
- Data formats used typically have a schema associated with them. For example, if using AVRO, one would need to define an AVRO schema. A key consideration would be the ability to automatically generate the schema based on the relational database’s metadata, or AVRO schema for Hive tables based on the relational database table schema.
- The ability to automatically generate Hive tables for the source relational databased tables.
- When designing your ingest data flow pipelines, consider the following:
- The ability to automatically perform all the mappings and transformations required for moving data from the source relational database to the target Hive tables.
- Ability to automatically share the data to efficiently move large amounts of data.
- The ability to parallelize the execution, across multiple execution nodes.
The above tasks are data engineering patterns, which encapsulate best practices for handling the volume, variety and velocity of that data.
In my next post, I will write about a practical approach on how to utilize these patterns with SnapLogic’s big data integration platform as a service without the need to write code. In the meantime, you can learn more about big data integration here and be sure to check back for more posts about data ingestion pipelines.
Prasad Kona is a Big Data Enterprise Architect and part of the big data integration team at SnapLogic.

