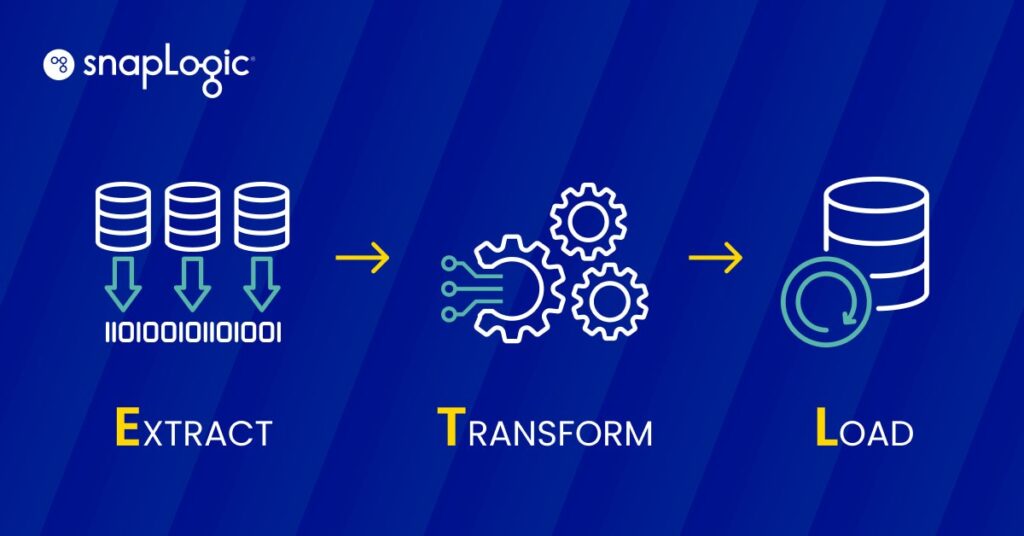
What is ETL?
To answer the question “What is ETL?” you must first know “What does ETL stand for?”
ETL stands for “Extract, Transform, and Load.”
Now knowing what ETL stands for, we can now better define “What is ETL?”
In its most basic form,
ETL is a combination of SQL statements and other programming languages (such as Python or Java) put together to form a data integration process for moving and manipulating data.
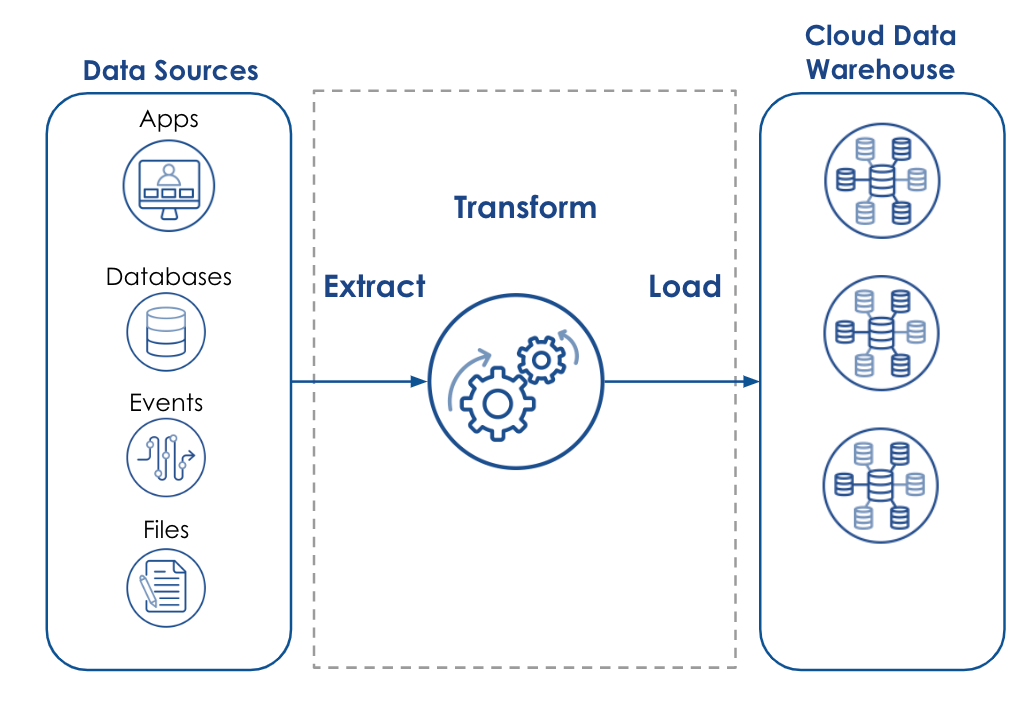
ETL forms the foundation for the most common method of data integration. Extract data from a data source, transform data to improve data quality, and finally, load data into a data warehouse, data lake, or business intelligence tool for easy analysis.
As the practice of ETL became more and more critical to the success of an organization, dedicated ETL tools grew in popularity, providing pre-built connectors to many popular data sources and applications, functionality to standardize data formats and simplify data transformation, and flexibility to solve the latest business challenges. Even as the demands for data integration have evolved over the years, the basic concepts of ETL have remained constant – extract data, transform data, and load data.
The difference between ETL and ELT
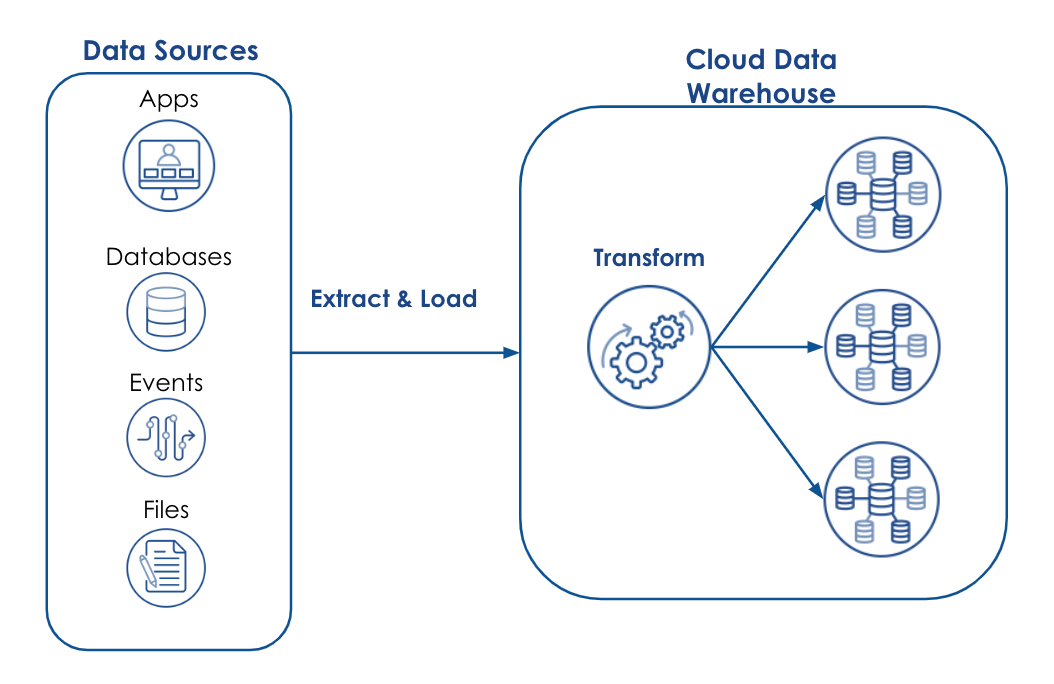
Now you might be asking, “If ETL stands for Extract, Transform, and Load, then what is ELT and how is it different?”. Similar to ETL, ELT stands for Extract, Load, and Transform. The same basic data integration steps are identified, just in a slightly different order. With ETL, the data transformation is done outside the data warehouse, before it is loaded into a staging table. This method allows the on-premises data warehouse to be optimized for read/write operations rather than complex calculations and data manipulations. ELT, on the other hand, leverages the scalability of the cloud data warehouse to transform data on the spot, eliminating the need for separate servers or runtime environments dedicated specifically to data processing.
To be clear, ELT is not a replacement for ETL.
Each has its benefits and use cases as identified below:
Benefits and Use Cases for ETL Tools
The Benefits of ETL Tools:
Full data management capabilities – Some of the best ETL tools are part of an overall data management platform. These platforms provide comprehensive functionality to manage the full lifecycle of ETL processes and data flows, including design, code, test, and deployment.
Advanced data quality – ETL tools are well suited for complete data profiling capabilities and provide extensive data transformations, manipulation, and cleansing functionality, including general standardization, data type conversion, deduplication, validation, and enrichment.
Compliance – ETL tools have comprehensive data masking and encryption functionality that make them better suited for compliance with many regulatory standards such as HIPAA, GDPR, and CCPA.
Graphical user interface – Modern ETL tools have easy-to-use interfaces, providing a low-code / no-code approach to building ETL pipelines. More advanced ETL tools offer comprehensive dashboards for greater insights into data flows, execution times, and utilization.
Common Use Cases for ELT Tools
- Complex data integration workflows
- Data quality and data governance requirements
- Relational and structured data formats
- On-premises data warehousing
- Data migration
Benefits and Use Cases of ELT Tools
The Benefits of ELT Tools
Quick access to raw data – ELT delivers high performance by eliminating the transformation of data prior to loading, moving raw data into the data warehouse much quicker. Additionally, having direct access to the raw data provides greater flexibility for analytics.
Process non-relational, unstructured data – ELT is ideal for the analysis of non-relational and unstructured data sets.
Low cost and low maintenance – ELT tools are inherently cloud-based and target the cloud data warehouse. Most cloud data warehouses are enabled with pushdown optimization capabilities, thus ensuring optimal pricing with no maintenance costs and minimal operational costs.
Use Cases of ELT Tools
- Data Lake, Lakehouse, and Delta Lake implementations
- Large data volumes
- Need for better query performance
- Need for faster access to insights
The role of ETL Software in Data Integration
ETL software and Data Integration are nearly synonymous. You can’t have one without the other. ETL software (often referred to as a Data Integration tool) was introduced to simplify the transformation and loading of data into structured or relational data warehouses. However, today, these traditional ETL approaches and legacy tools are simply unable to meet the data integration demands of modern, data-driven organizations. Based on point-to-point, row-and-column architectures, traditional ETL tools struggle with huge volumes of real-time, unstructured, and hierarchical data. Further, traditional ETL solutions are just too expensive, don’t scale, are too rigid, and require too much maintenance. We need a new approach to ETL and data integration.
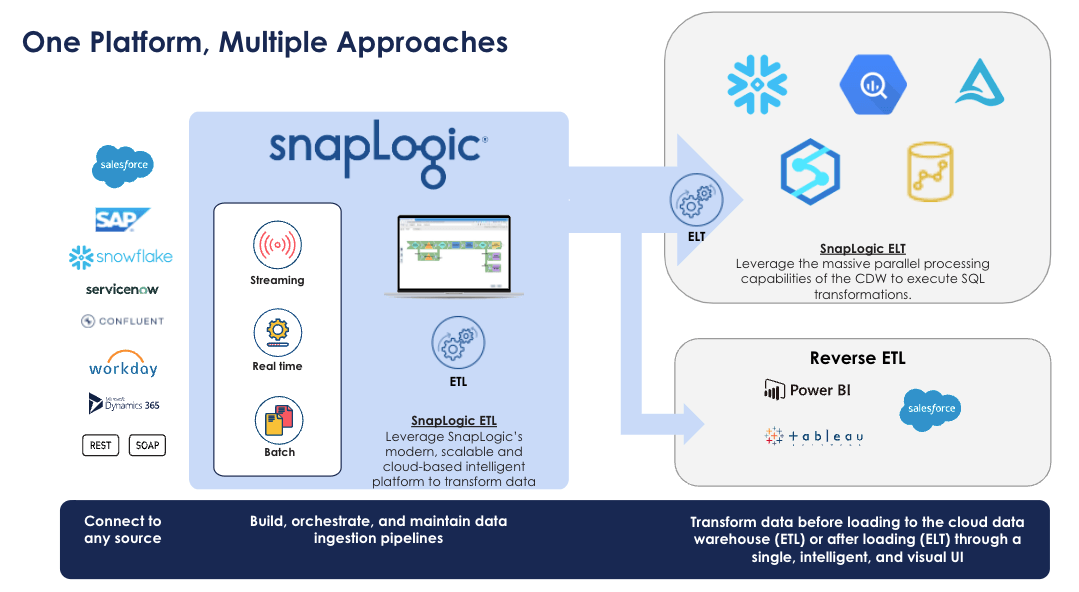
SnapLogic’s Modern Approach to ETL and Data Integration
SnapLogic takes a truly innovative approach to data integration with the SnapLogic Intelligent Integration Platform (IIP). More than just an ETL tool, the SnapLogic IIP is a multi-tenant cloud service with a hybrid data processing engine that provides enterprise scalability and powerful parallel processing, full data management capabilities, and an easy-to-use, drag-and-drop designer with over 600 pre-built connectors (called Snaps) in a single, unified platform. Unlike competitors such as Talend, IBM Datastage, and Informatica PowerCenter, SnapLogic IIP is cloud-native, making it ideal for today’s cloud platforms like Amazon AWS, Microsoft Azure, Google Cloud, and others. Powered by SnapLogic Iris, our AI-powered integration assistant that is pervasive throughout the platform, The SnapLogic IIP Designer enables technical and non-technical data consumers to build data pipelines in a graphical, low-code / no-code environment, giving everyone access to the data they need, when and where they need it.
And best of all, the SnapLogic iPaaS solution is 100% Rest-based, giving users extreme flexibility to connect to different sources and build ETL pipelines then abstract them as addressable, usable, consumable, trigger-able, and schedule-able REST API calls. This flexibility delivers considerable advantages over traditional static integrations. Whether one-to-one, one-to-many, many-to-one, or many-to-many, the challenges of managing these orchestration scenarios through a traditional ETL approach disappear because SnapLogic IIP delivers enterprise-grade scalability, simplicity, and reliability that promotes fast implementations while dramatically lowering costs.
ETL for Enterprise Automation
As organizations strive to become more data-driven, Enterprise Automation has become critical to their success. Enterprise Automation is the sharing of data between multiple applications and systems to automate complete business processes. ETL plays a critical role in an organization’s ability to achieve this by providing the necessary data pipelines that connect apps for event-driven automation. SnapLogic literally wrote the book on Enterprise Automation and delivers a single platform that is capable of both data and application integration with full Data Management and API Management capabilities for app-to-app integration, real-time data delivery, and event-driven automation in a no-code / low-code environment.
ELT for Cloud Data Warehouses
The emergence of cloud computing and the cloud data warehouse has brought with it a much-needed revision of traditional ETL. That is, load the data into the cloud data warehouse first, then focus on data transformation. SnapLogic is able to handle both traditional ETL and the more modern ELT approaches in a single platform with drag-and-drop ease. Our user-friendly “Snap” together design approach addresses the most challenging aspect of ELT – complex SQL queries – with no-code, pre-built connectors, and Snaps that make it easier than ever to modernize your data landscape. This visual approach breaks the mold of typical ELT tools that require manual hand-coding of SQL and a deep understanding of SQL to optimize query performance. SnapLogic gives full transparency to the exact SQL statement that is automatically generated, so users have the utmost confidence in the transformations before the data is modified. Best of all, SnapLogic has partnered with the Top 5 cloud platforms (including Microsoft Azure, AWS Redshift, Snowflake, and Google BigQuery) to deliver streamlined solutions to your digital transformation challenges.
With our innovative ETL and ELT approaches in mind, companies finally have access to the data they need to compete in a fast-moving market.
Your One Platform for the Future
SnapLogic delivers a single platform capable of solving the most complex business challenges. No matter what your organization is trying to achieve, SnapLogic makes it possible with our core differentiators aimed at driving your business to success now and in the future.
Modern
The SnapLogic Intelligent Integration Platform (IIP) separates the integration control plane from the data execution plane, delivering a low-latency, streaming-based architecture that supports all your modern integration requirements: real-time, event-based, and batch.
Cloud-born
SnapLogic was purpose-built for the cloud before the cloud was cool. SnapLogic promotes elastic operation and enables you to mobilize data when and where it is needed most: publicly or privately, in the cloud or behind a firewall, on-premises, or in hybrid data centers and infrastructure anywhere in the world.
Intelligent
SnapLogic Iris, the pioneering technology for AI-powered integration assistance, is now driven by over a decade of data pipeline and data usage analysis and delivers expert guidance to improve the ease of use and speed of building both data and application integrations. Our browser-based cloud service is powerful enough for developers, yet easy enough for non-developer citizen integrators.
Scalable
The SnapLogic Intelligent Integration Platform (IIP) is capable of operating at a massive scale to meet your performance demands. From CPU-based, computational scaling that delivers peak performance to user scaling that enables as many individuals, of all personas, across the organization to access the platform, SnapLogic eliminates performance bottlenecks, drives process efficiencies, and promotes end-user adoption.
Contact us or request a demo to learn more about SnapLogic and our innovative approach to ETL and Data Integration.