In this final post in this series from Mark Madsen’s whitepaper: Will the Data Lake Drown the Data Warehouse?, I’ll summarize SnapLogic’s role in the enterprise data lake.
SnapLogic is the only unified data and application integration platform as a service (iPaaS). The SnapLogic Elastic Integration Platform has 350+ pre-built intelligent connectors – called Snaps – to connect everything from AWS Redshift to Zuora and a streaming architecture that supports real-time, event-based and low latency enterprise integration requirements plus the high volume, variety and velocity of big data integration in the same easy-to-use, self service interface.
SnapLogic’s distributed, web-oriented architecture is a natural fit for consuming and moving large data sets residing on premises, in the cloud, or both and delivering them to and from the data lake. The SnapLogic Elastic Integration Platform provides many of the core services of a data lake, including workflow management, dataflow, data movement, and metadata.
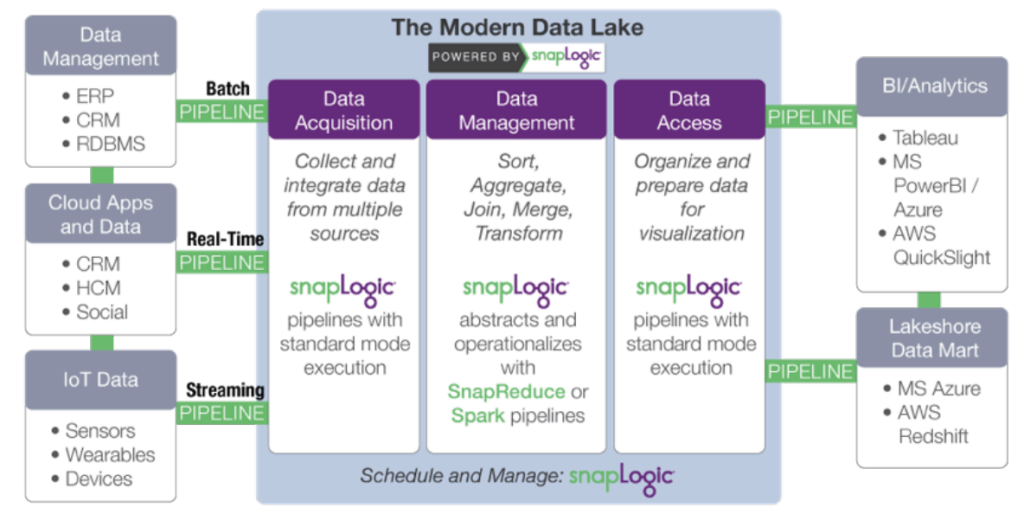
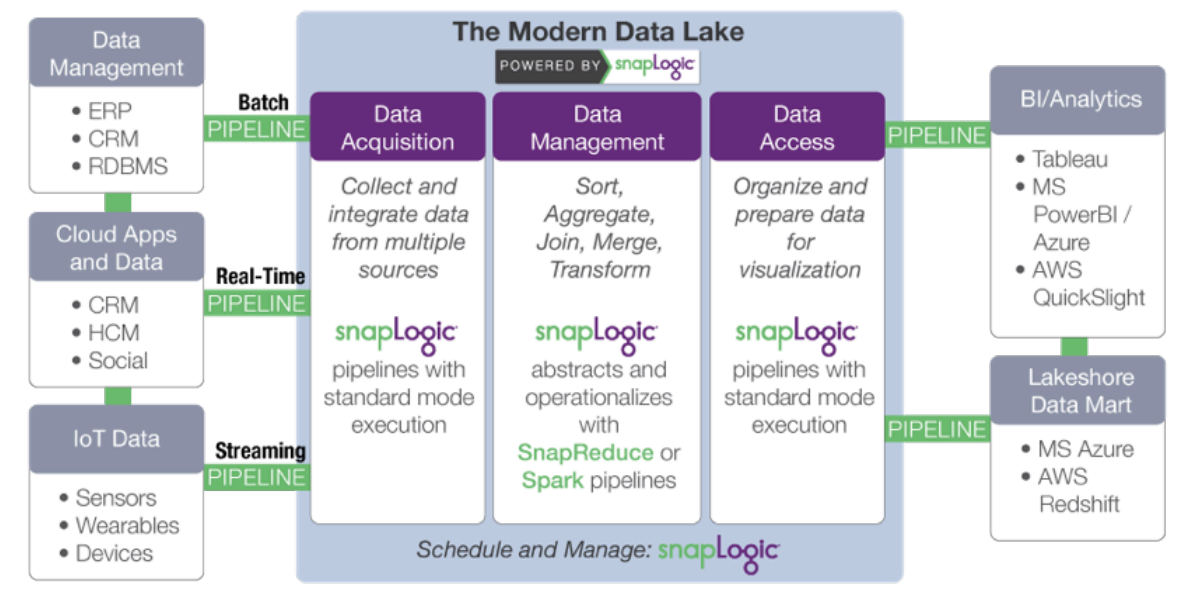
More specifically, SnapLogic accelerates development of a modern data lake through:
- Data acquisition: collecting and integrating data from multiple sources. SnapLogic goes beyond developer tools such as Sqoop and Flume with a cloud-based visual pipeline designer, and pre-built connectors for 350+ structured and unstructured data sources, enterprise applications and APIs.
- Data transformation: adding information and transforming data. Minimize the manual tasks associated with
data shaping and make data scientists and analysts more efficient. SnapLogic includes Snaps for tasks such as transformations, joins and unions without scripting. - Data access: organizing and preparing data for delivery and visualization. Make data processed on Hadoop
or Spark easily available to off-cluster applications and data stores such as statistical packages and business intelligence tools.
SnapLogic’s platform-agnostic approach decouples data processing specification from execution. As data volume or latency requirements change, the same pipeline can be used just by changing the target data platform. SnapLogic’s SnapReduce enables SnapLogic to run natively on Hadoop as a YARN-managed resource that elastically scales out to power big data analytics, while the Spark Snap helps users create Spark-based data pipelines ideally suited for memory-intensive, iterative processes. Whether MapReduce, Spark or other big data processing framework, SnapLogic allows customers to adapt to evolving data lake requirements without locking into a specific framework.
We call it “Hadoop for Humans.”
Next Steps:
- Download the whitepaper: How to Build an Enterprise Data Lake: Important Considerations Before You Jump In. You can also watch the recorded webinar and check out the slides on the SnapLogic blog.
- Download the whitepaper: Will the Data Lake Drown the Data Warehouse?
- Check out this demonstration of SnapReduce and the SnapLogic Hadooplex to learn about our “Hadoop for Humans” approach to big data integration.