





Integrate
Automate
Orchestrate


Trusted by leading companies across the globe
Integrate the easy way, with generative AI
SnapLogic’s breakthrough generative AI solution, SnapGPT brings self-service and unparalleled speed to not only data and application integrations, but also workflow automation, using simple natural language prompts.

Automated workflow solutions for every team and workplace
Human Resources
Automate and streamline HR workflows for a modern, seamless employee experience.




Sales
Automate and streamline sales workflows to drive pipeline and boost revenue for your enterprise.




IT
Empower the business to automate while maintaining governance.




Marketing
Automate and streamline Marketing workflows to drive your pipeline.




Finance & Accounting
Automate workflows, trigger key actions, and gain critical insights in minutes, not days.



All the tools you love, integrated in a Snap
Snaps are pre-built connections that make code-free integrations possible.
With over 700 Snaps to choose from, SnapLogic makes it easy to create simple workflows or complex business processes between cross-functional work groups. Enable your organization to automate entire ecosystems of applications, databases, APIs, data warehouses, devices, and more.
It takes us minutes to deploy integrations across 1,800 applications with SnapLogic. We’ve also been able to reduce support overhead and costs by over 25%.
Swati Oza
Director of IT Emerging Technology, Data Integration, and ML at HPE
CASE STUDY
How Global Payments Company Vitesse Banked On SnapLogic To Turn a Complex Integration Process Into Success
“We’re looking at developing different kinds of Snaps for different kinds of processes, allowing for different options for clients to utilise in their transfer journey. Flexibility is core to our game plan, and SnapLogic offers just that.”
Craig Walter
Principal Solutions Manager at Vitesse
CASE STUDY
Guild Streamlines Customer Onboarding Process with SnapLogic
Highlights
- Reduced customer onboarding time for engineers by 70%
- Consolidated 1,000+ lines of code, 5 projects and 2 teams to a single configuration file
- Expanded a multimillion-dollar partnership with API-based sources
CASE STUDY
Transforming the Way Employees Work at Schneider Electric
Highlights
- Nearly 150 citizen developers empowered to build their own applications
- More than 100 applications integrated across the company
- Autonomy and productivity increased for business teams
Why SnapLogic?
Don’t just take our word for it. See what our trusted customers and partners have to say.
SnapLogic named the winner in two categories: Best Big Data Product – Data Fabric/Data Mesh and Top 3 Big Data and AI Vendors to Watch.
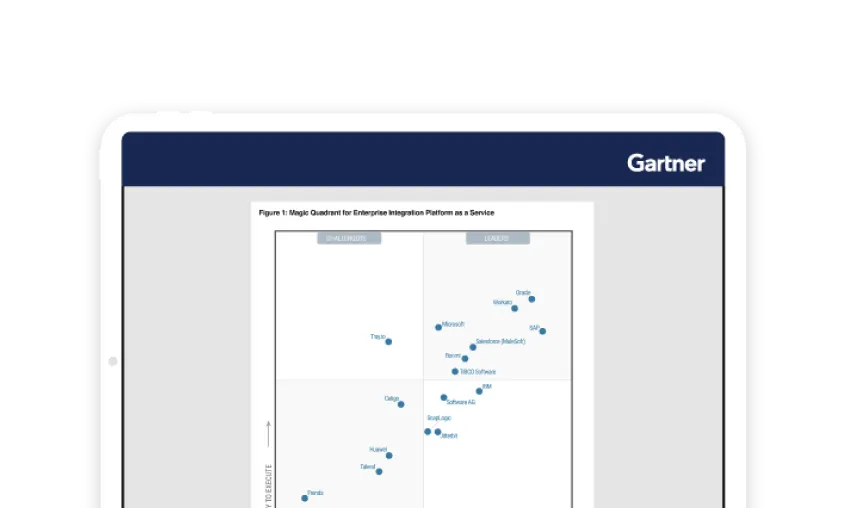
Gartner® Positions SnapLogic a Visionary in 2024 Magic Quadrant for iPaaS
G2 Recognizes SnapLogic as a Leader

SnapLogic Leads in Aragon Research’s tPaaS Globe Report with the Most Advanced Business Process

TrustRadius Recognizes SnapLogic with Three “Top Rated” Awards

Skidmore College & SnapLogic Win the Data Category of the Ventana Research Digital Leadership Awards
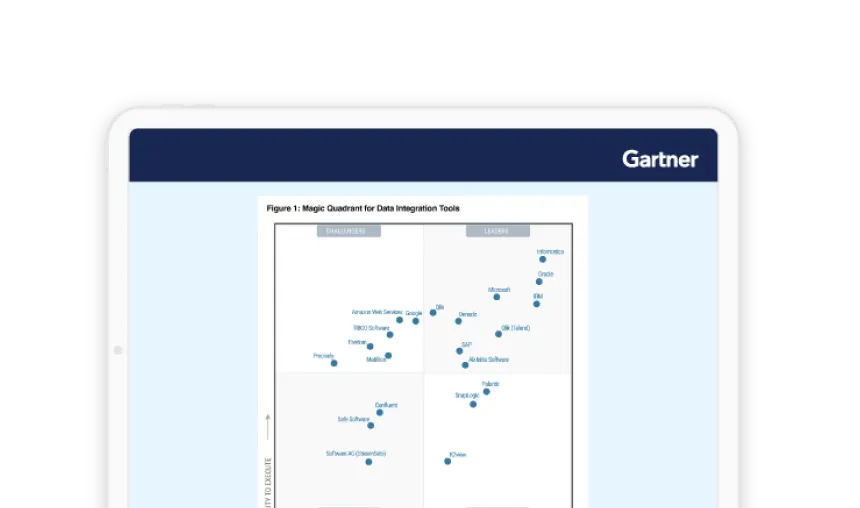
Gartner® Positions SnapLogic a Visionary in 2023 Magic Quadrant for Data Integration Tools
Forrester reveals a customer ROI of 498% and total benefits of over $3.9 million over three years for the SnapLogic platform. Get Forrester’s Total Economic Impact™ Study of SnapLogic.
ROI with a payback
period of <6 months
improvement
in productivity


