Letzte Woche war ein Teil des SnapLogic-Teams in New York City auf der Strata/Hadoop World-Konferenz. Es handelt sich um eine der größten Big-Data-Veranstaltungen in den USA, die in den letzten Jahren immer größer geworden ist. Auch die Tagesordnung hat sich ein wenig verändert - von weitgehend akademischen Diskussionen und How-to-Präsentationen von Open-Source-Committern zu realen Fallstudien von Nicht-ISV-Unternehmen.
In diesem Sinne möchte ich Ihnen eine Geschichte von einem unserer Unternehmenskunden erzählen. Bei diesem Kunden handelt es sich um ein über 100 Jahre altes Finanzinstitut. Vielleicht nicht gerade ein Unternehmen, das man mit den modernsten Datenmanagement-Technologien in Verbindung bringen würde... Aufgrund der Natur ihrer Branche kann ich ihren Namen nicht nennen.
Wie bei vielen etablierten Unternehmen wurden die Datenverarbeitungs- und -speichersysteme dieser Bank im Laufe der Jahre je nach den dringendsten Bedürfnissen und den jeweiligen Compliance-Anforderungen erworben oder hinzugefügt. Am Ende stand man vor der Aufgabe, einen unübersichtlichen Mix aus über 240 Schnittstellen und Anwendungen zu verwalten.
Wie Sie sich vorstellen können, kamen die Daten in einer Vielzahl von Formaten, z. B. Excel-Dateien, Textdateien mit Trennzeichen (csv), Copybooks mit fester und variabler Länge und gezippte Dateien. Außerdem gab es eine Vielzahl von Datenquellen, wie ftb/sftp, QlikView Business Intelligence und SQL Server-, Oracle- und Sybase-Datenbanken. Die Verwaltung dieser Umgebung war nicht nur schwierig, sondern auch zeitaufwändig und belastete die Ressourcen der IT-Mitarbeiter und die Budgets erheblich.
Die Aufbewahrung von Daten für einen bestimmten Zeitraum ist im Bankensektor gesetzlich vorgeschrieben. Daher war die Suche nach einer kostengünstigen und effizienten Speicherlösung der dringlichste Anwendungsfall, aber das Unternehmen wollte auch seine Kundendaten effektiver nutzen.
Auf der Suche nach einem modernen Ansatz für die Datenverwaltung und -speicherung und letztlich nach einem optimierten und verbesserten Kundenservice beschloss das Unternehmen, eine Reihe von Altdatenbanken und Mainframe-Anwendungen abzuschaffen, den Ansatz für die Datenspeicherung zu modernisieren und die Geschäftsanalysen mit Hadoop und einem Data Lake zu beschleunigen.
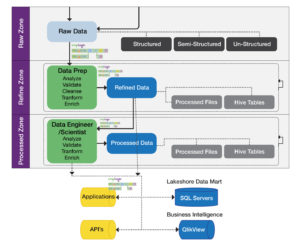
Nach Überlegungen, wie man dies intern umsetzen könnte, und nach Sondierung von Optionen auf dem Markt, einschließlich Open-Source-Tools, entschied man sich für den Einsatz der SnapLogic Elastic Integration Platform in Verbindung mit einer Cloudera-basierten Hadoop-Umgebung. SnapLogic ermöglichte die Aufnahme, Aufbereitung und Bereitstellung von Daten in einem einzigen Data Hub und unterstützte damit die Ausmusterung älterer Datenbanken und Mainframe-Anwendungen sowie die Konsolidierung von Daten aus verschiedenen Quellen in einem Data Lake. In der nächsten Phase des Projekts wird SnapLogic auch die Vision eines "Self-Service Data Lake" für zukünftige Berichtsanforderungen ermöglichen.
Nach dem Einsatz von SnapLogic zur Konsolidierung interner Datenquellen und der Abschaffung vieler bestehender Datenbanken und Mainframe-Anwendungen, die interne Geschäftsdaten unterstützen, wurden dem Data Hub externe Daten von Drittanbietern von Finanzdaten hinzugefügt. Nach Abschluss der Arbeiten wird das Unternehmen über einen umfassenden Satz integrierter Daten in einem Cloudera Data Hub verfügen, der eine effiziente und kostengünstige Datenspeicherung ermöglicht. Dies wird auch die Grundlage für das nächste Projekt bilden, das den Data Hub für eine 360-Grad-Sicht auf den Kunden und damit für eine bessere Kundenbetreuung nutzen wird.
Statt Daten nur als Aufbewahrungsproblem für die Einhaltung von Branchenvorschriften zu betrachten, wird der Data Hub oder Data Lake dieser Bank als strategisches Asset angesehen. Der Hadoop-basierte Data Lake ist mehr als nur ein "billiger verteilter Speicher", er ist eine zentrale Ressource für Datenanalysen und Erkenntnisse. Mit diesen konsolidierten Geschäftsdaten kann das Unternehmen alle Daten nach Kunden und Kundenbeziehungen aufschlüsseln und so unschätzbare Informationen zur Verbesserung des gesamten Kundenservices liefern. Wir bei SnapLogic sind stolz darauf, eine wichtige Rolle bei der Verwirklichung der Data Lake-Vision zu spielen.
Wie uns unser Kundenbeauftragter mitteilte: "Die ursprüngliche Herausforderung war die Einhaltung von Vorschriften und gesetzlichen Bestimmungen in der Finanzbranche. Als wir über innovative Möglichkeiten nachdachten, wie wir das besser in den Griff bekommen könnten, kamen wir auf die Idee, sozusagen zwei Fliegen mit einer Klappe zu schlagen. Wie wäre es mit einem Datenarchivierungs- und -aufbewahrungssystem, das gleichzeitig als Datendrehscheibe fungiert und Einblicke gewährt?
Die Lösung war klar, aber die Aufgabe war entmutigend und mit vielen Herausforderungen verbunden. Also machten wir uns mutig auf den Weg, mit nicht viel, einem Junior-DBA zur Unterstützung und der Anleitung von Cloudera und SnapLogic, die uns bei der Entwicklung und Umsetzung unserer Vision halfen.