






Es ist viel darüber diskutiert worden, dass Daten die neue Währung sind. So schrieb Rob Versaw, Mitglied des Forbes Technology Council, in seinem Blogbeitrag "Wie man die neue Währung einführt: Daten," "Unternehmen mit dem größten Potenzial für Wachstum und Marktanteile nutzen Daten effizienter als ihre Konkurrenten.." Das Potenzial, aus Daten einen geschäftlichen Nutzen zu ziehen, ist durchaus vorhanden, aber der Schlüssel zur Ausschöpfung des Potenzials liegt darin, die Daten zur richtigen Zeit am richtigen Ort und im richtigen Format bereitzustellen. Es hat sich gezeigt, dass es nicht von Erfolg gekrönt ist, einfach alle verfügbaren Daten zu nehmen und in einem Data Lake zu speichern.1 Die Verlagerung von Anwendungen und Daten in die Cloud ist bereits im Gange und wird sich weiter entwickeln. Die Speicherung und Verarbeitung von Big Data wird mit Sicherheit einem ähnlichen Trend folgen. Wie können sich Unternehmen für eine erfolgreiche Datenhydrierung rüsten?
Es liegt auf der Hand, dass Unternehmen heute die Cloud für sich entdeckt haben und eine breite Palette von SaaS-Anwendungen in vielen Geschäftsbereichen (LoBs) vollständig nutzen. Anwendungen wie Salesforce, Workday und Zendesk enthalten wichtige Informationen, wenn es darum geht, geschäftliche Erkenntnisse zu gewinnen. Streaming-Daten von IoT-Sensoren liefern wertvolle Informationen über den Zustand von Geräten. Streaming-Daten aus sozialen Medien liefern Echtzeitinformationen darüber, wie Kunden Ihr Angebot wahrnehmen. Um jedoch den größtmöglichen geschäftlichen Nutzen aus Daten zu ziehen, müssen Sie Daten aus vielen Quellen aufnehmen und kombinieren, sei es über die oben erwähnten SaaS-Anbieter und Streaming-Quellen oder über traditionellere Quellen wie Geschäftsdaten vor Ort (DBMS). Durch die Ergänzung primärer Datenquellen mit zusätzlichen internen und externen Datenquellen können Unternehmen das Potenzial für neue Erkenntnisse freisetzen.
Die Wolke anzapfen
Zusammen mit der SaaS-Bewegung ist die Datenspeicherung in der Cloud jetzt die neue Norm - ob Sie nun DBMS in der Cloud wie Snowflake, Amazon Redshift, Microsoft Azure SQL Data Warehouse oder Objektspeicher in Diensten wie Amazon S3, Microsoft WASB usw. verwenden. Durch Cloud-Speicher entfällt für die IT-Abteilung die Notwendigkeit, Backups und Datenreplikationen zu erstellen, da diese Aufgaben Teil des Cloud-Service-Angebots sind, wodurch die Kosten und die Komplexität der Verwaltung von IT-Ressourcen reduziert werden. Die Cloud-Speicherung bietet auch eine kostengünstige Möglichkeit, Unternehmensdaten zu speichern und zu verwalten, wodurch die IT-Abteilung des Unternehmens flexibler werden kann.
Verarbeitung komplexer Datensätze
Hadoop und HDFS haben Unternehmen zwar die Technologie zur Verfügung gestellt, mit der sie große, komplexe Datensätze speichern und verarbeiten können, doch diese Umgebung erfordert spezielle Fähigkeiten. Darüber hinaus waren diese Hadoop-Cluster in der Vergangenheit lokale Systeme, die eine hohe Anfangsinvestition erforderten, um loszulegen. Data Lakes und Big Data-Verarbeitung folgen der Cloud-Bewegung, indem sie in die Cloud verlagert werden. Die erste Phase wird als "Lift and Shift" bezeichnet, bei der Unternehmen den lokalen Hadoop-Cluster einfach zu einem Cloud-Anbieter verlagern, der in einem virtuellen Netzwerk läuft, und dabei die Vorteile von IaaS wie Kosten und einfache Skalierung nutzen. In dieser Phase werden die Cluster jedoch immer noch vom Unternehmen verwaltet, ohne dass die Qualifikationslücke geschlossen wird.
Die nächste Phase der Big-Data-Verarbeitung bedeutet die Verlagerung der Verarbeitung in eine verwaltete Hadoop-as-a-Service-Umgebung (HaaS) wie Amazon EMR, Microsoft HDInsight, Cloudera Altus, Hortonworks Data Cloud usw. Diese verwalteten Dienste haben den Vorteil, dass sie die Unternehmen von der Komplexität der Verwaltung und Wartung von Hadoop-Umgebungen befreien. Diese verwalteten Hadoop-Dienste können auch die zugrundeliegenden Cloud-Speichersysteme wie Amazon S3 und Microsoft ADLS nutzen, was die Aufnahme und Bereitstellung der Daten erleichtert, ohne dass die Daten in HDFS verschoben/kopiert werden müssen.
Vereinfachung der Hydratisierung und Verarbeitung von Datenseen
Die hybride Integrationsplattform von SnapLogic bietet die Möglichkeit, die Datenhydrierung von einem umfassenden Satz von Endpunkten aus zu realisieren, sei es in der Cloud oder vor Ort. Unsere einzigartige Snaplex-Architektur ist darauf ausgelegt, Daten über komplexe und sich entwickelnde hybride Unternehmenslandschaften hinweg auszutauschen.
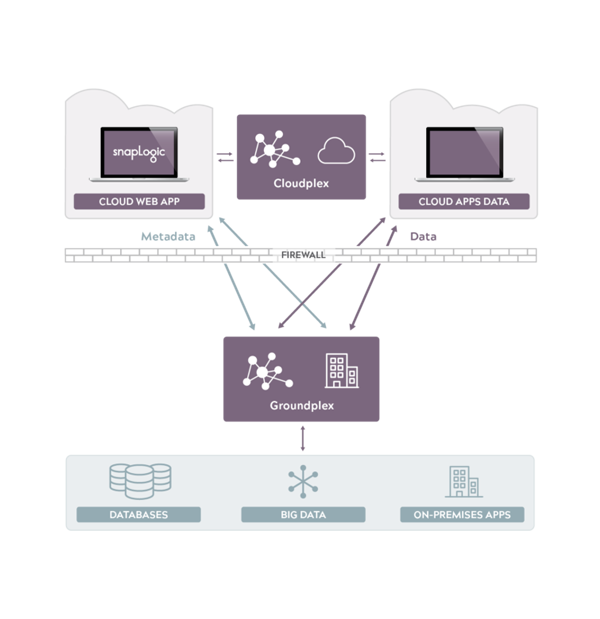
Um die Qualifikationslücke bei der Arbeit mit Big Data durch Datenhydrierung zu schließen, ist die Verbindung zu den Endpunkten so einfach wie Ziehen und Ablegen. Wir verbinden uns mit den Endpunkten durch die Verwendung von Konnektoren namens Snaps. Wir verfügen über mehr als 400 Snaps, die eine Verbindung zu ERP, CRM, HCM, Hadoop, Spark, Analysen, Identitätsmanagement, sozialen Medien, Online-Speicher, relationalen, säulenförmigen und Key-Value-Datenbanken und Technologien wie XML, JSON, OAuth, SOAP und REST herstellen, um nur einige zu nennen. Mit einem umfassenden Satz von Endpunkten kann SnapLogic den Wert der Big Data-Verarbeitung durch Einbeziehung einer größeren Vielfalt von Daten erhöhen.
SnapLogic erweitert die Integration von Ihren traditionellen IT-Integratoren auf die LoB-Ad-hoc-Integratoren durch seine visuelle Programmierschnittstelle. Der visuelle Designer von SnapLogic macht es LoB-Benutzern, Integrationsspezialisten und der IT-Abteilung leicht, Integrationen innerhalb von Stunden, nicht von Tagen oder Wochen, zu erstellen - ohne Programmieraufwand.
Da Daten zur neuen Währung werden, werden Unternehmen, die wirklich datengesteuert sind, einen Wettbewerbsvorteil erlangen. Wir haben gesehen, wie Daten und Anwendungen in die Cloud verlagert wurden, und jetzt erleben wir, wie die Big-Data-Verarbeitung in die Cloud verlagert wird. Ihre Big-Data-Verarbeitungslösungen werden sich genauso weiterentwickeln wie Ihre SaaS und Daten zuvor. Sind Sie darauf vorbereitet? SnapLogic unterstützt Sie bei Ihrer Migration zur Big Data-Verarbeitung in der Cloud.
1. [Quelle: Gartner: Derive Value From Data Lakes Using Analytics Design Patterns Sept 2017]




