






In diesem Blog werden Data Warehouse-, Data Lake- und Data Lakehouse-Konzepte sowie deren Vergleich und Kontrast und die Vorteile der einzelnen Ansätze erläutert. Dieser Blog soll einen Überblick über die Architektur auf hoher Ebene geben.
Klassische Data Warehouses
Als langjähriges Arbeitspferd der Welt der Business Intelligence und Datenanalyse existiert das klassische Data-Warehouse-Konzept seit den 1980er Jahren, und die Popularität des Data-Warehouse als Geschäftsinstrument ist weitgehend dem amerikanischen Informatiker Bill Inmon zu verdanken. Inmon, der oft als "Vater" des Data Warehousing angesehen wird, definierte das Data Warehouse ursprünglich als "eine subjektorientierte, nicht flüchtige, integrierte, zeitvariante Sammlung von Daten zur Unterstützung der Entscheidungen des Managements".
Data Warehouses sind und bleiben beliebte Werkzeuge für Unternehmen in aller Welt, da sie ihnen die Möglichkeit bieten, Daten und Veränderungen im Laufe der Zeit zu analysieren, Einblicke zu gewinnen und Schlussfolgerungen zu ziehen, die bei Geschäftsentscheidungen helfen.
Klassische Data Warehouses [Abbildung 1] fungieren in der Regel als zentrale Repositories, in denen Informationen, d. h. Daten, von internen Geschäftseinheiten, externen Geschäftspartnern, Vertriebs- und Produktionsbetrieben und einer Vielzahl anderer Quellen eingehen. Das Ziel und der Nutzen von Data Warehousing besteht darin, all diese Informationen zu sammeln, zu speichern, zu aggregieren und eine ganzheitliche Sicht auf ein Unternehmen zu erhalten, um so vollständigere und umfassendere Informationen über das Unternehmen zu erhalten. Je schneller ein Data Warehouse Benutzern und Führungskräften helfen kann, Informationen zu erstellen oder darüber zu berichten, desto besser.
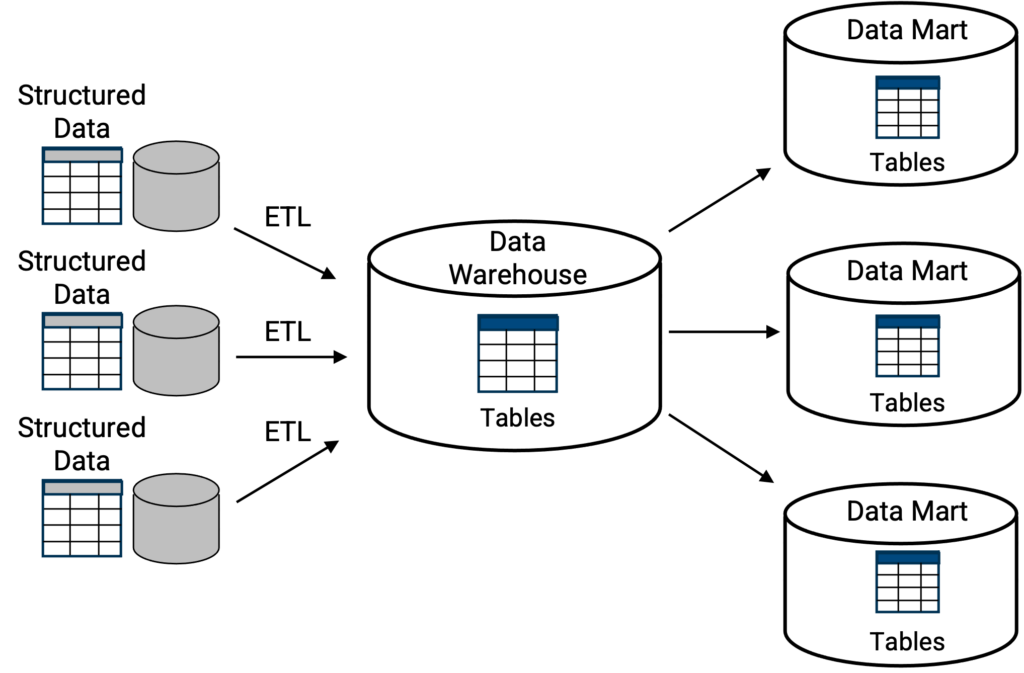
Oben: die klassische Data-Warehouse-Topologie, bei der eine primäre Speicherstruktur ein zentraler Ort für eine Sammlung von Tabellen oder Datenbanken ist. Abfragefunktionen, in der Regel SQL, sind von Haus aus in das Data Warehouse integriert. Wie gezeigt, können Datenbanken oder Tabellen in kleinere Data Marts als Teilmenge des Data Warehouse repliziert werden, wobei jeder Data Mart eine bestimmte Funktion erfüllt, z. B. ein Data Mart für das Finanzwesen oder ein Data Mart für die Fertigung usw.
Beispiele für klassische Data Warehouses sind Oracle, Teradata, Amazon Redshift, Azure Synapse - wobei sich die Implementierung darin unterscheiden kann, ob das klassische Data Warehouse vor Ort oder in der Cloud bereitgestellt wird.
Datenspeicher
Der Hauptvorteil einer Data-Lake-Architektur (aus dem Jahr 2010) besteht darin, dass sie eine flexiblere Option darstellt, die als zentraler Speicher für mehr Datentypen dienen kann [Abbildung 2]. Alle Arten von Daten, von denen viele zu sperrig, zu groß in Bezug auf das Gesamtvolumen oder zu vielfältig sind, als dass ein klassisches Data Warehouse sie effektiv handhaben könnte, wobei effektiv handhaben [wenn überhaupt] der entscheidende Punkt ist.
Mit den entsprechenden Zugriffsrechten müssen alle Gemeinschaften von Datenexperten (Geschäftsanalysten, Datenwissenschaftler, Dateningenieure usw.) innerhalb eines Unternehmens, die mit den Daten arbeiten und sie analysieren müssen, eine Vielzahl von Abfragemethoden verwenden, die vom Format und der Struktur der abgefragten Daten abhängen.
Dies hat jedoch seinen Preis - und dieser Preis ist traditionell die Komplexität. Denn die Herausforderung bei Data Lakes besteht darin, dass es besonderer Fähigkeiten oder einer kompletten IT-Abteilung bedarf, um nicht nur all die verschiedenen Arten von Datendateien zu verwalten, die in einem Data Lake landen, und die verschiedenen Abfragetools zu unterstützen, sondern auch um abfragefähige Datensätze in Form einer Tabelle aus Rohdateien zu erstellen. Während der Zugriff und das Lesen oder die Vorschau von Daten in einem Data Lake relativ einfach sein mag, ist der Versuch, einen Datensatz abzufragen, um daraus Erkenntnisse zu gewinnen, eine andere Sache und hängt von der Struktur der Daten ab.
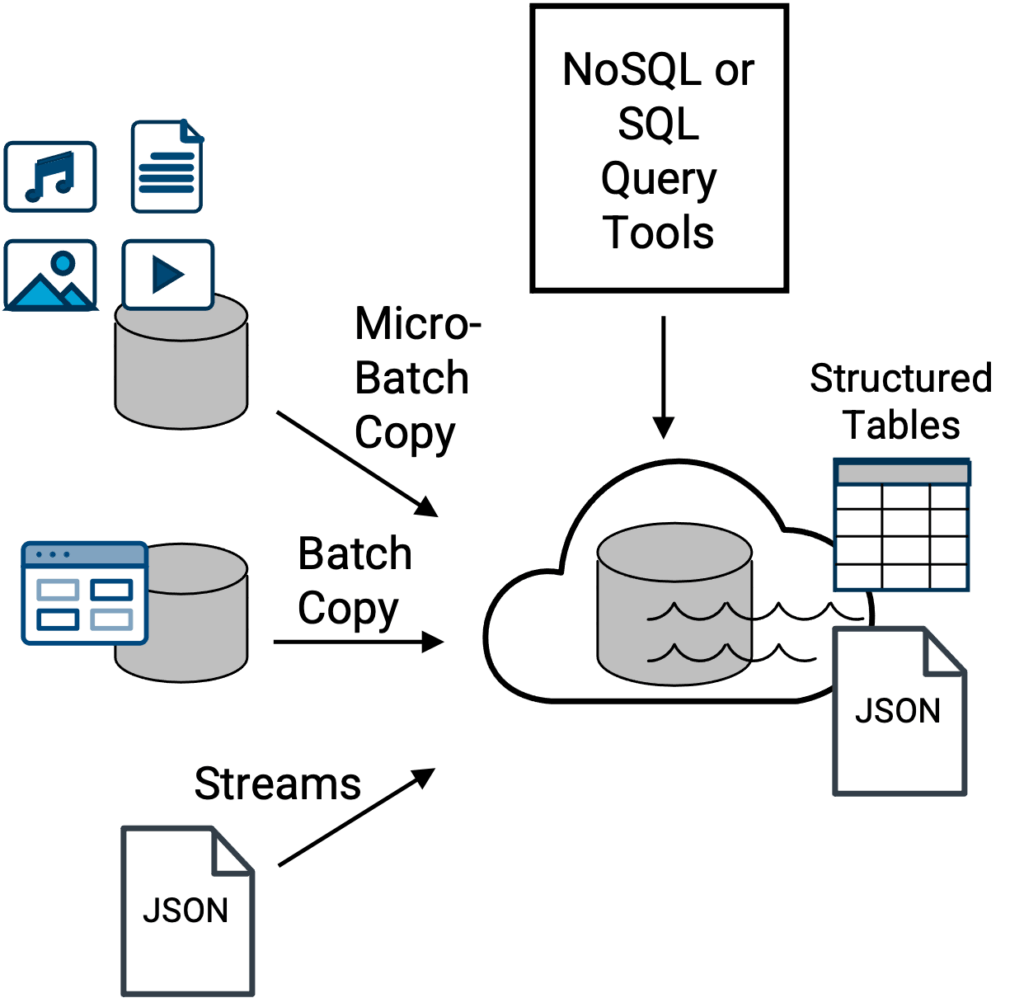
Oben: Traditionelle Data-Lake-Topologie, bei der Dateien und Daten aus einer Vielzahl von Quellen in den Data Lake eingespeist werden, um sie zentral zu speichern, darauf zuzugreifen und möglicherweise anschließend über SQL- oder NoSQL-Abfragetools und -engines abzufragen. SQL-Abfragetools arbeiten mit strukturierten Tabellen, während NoSQL-Abfragetools mit nativen JSON-Dokumentdateien arbeiten. Beispiele für einen Data Lake sind Amazon S3, Apache Iceberg, Azure Data Lake Storage (ADLS), Google Cloud-Speicher, und Hadoop HDFS-basierter Speicher.
Völlig unstrukturierte Daten wie Video-, Audio- oder Bilddateien lassen sich beispielsweise leicht abrufen, in der Vorschau anzeigen und als einzelne Dateien aus einem Data Lake untersuchen. Aber wie können Sie auf einfache Weise Erkenntnisse aus 1.000 Bildern gewinnen, und welche Art von Abfragetool würden Sie verwenden?
Wenn Sie in der Lage sind, diese Frage schnell zu beantworten und sie umzusetzen, gehören Sie zu dem kleinen Prozentsatz von Personen, die über die entsprechenden Fähigkeiten verfügen. [Die Antwort ist, dass in den meisten Fällen Metadaten über die unstrukturierten Daten erstellt werden, die dann mit Standard-SQL-Tools nach Erkenntnissen gescannt werden. Die eigentlichen unstrukturierten Dateien können in ein Datenstring-Äquivalent konvertiert werden oder auch nicht, je nach dem spezifischen Anwendungsfall für die unstrukturierten Daten].
Am anderen Ende des Spektrums stehen vollständig strukturierte Daten mit Zeilen und Spalten, d. h. eine Tabelle. So gut wie jeder Datenanalyst mit einem Abfragetool, insbesondere einem SQL-Abfragetool, kann relativ leicht 1.000 Zeilen oder Spalten von Daten abfragen und Erkenntnisse gewinnen. In der Mitte des Spektrums liegen halbstrukturierte Daten oder Dokumentendateien, wie z. B. JSON-Dateien. Heutzutage sind JSON-Dateien leicht zu erforschen, und obwohl die Abfrage von JSON-Daten nicht so einfach und unkompliziert ist wie die einer strukturierten Tabelle in einer vollständig relationalen Weise, können JSON-Daten mit NoSQL-Tools abgefragt werden, und es gibt viele beliebte Tools, die seit 2010 enorm gereift sind.
Datenexperten, darunter auch Data Scientists, geben an, dass sie die Flexibilität genießen, einzelne Dateien oder Datensätze zu erkunden oder in der Vorschau anzuzeigen. Wenn es jedoch an der Zeit ist, Daten abzufragen und Erkenntnisse und Beziehungen zwischen den Daten aufzudecken, ziehen es die meisten Datenexperten vor, mit Datenbanken und strukturierten Tabellendaten zu arbeiten (um eine ähnliche Erfahrung wie in einem klassischen Data Warehouse zu machen), anstatt zu versuchen, eine Abfrage über einzelne Rohdateien zu erstellen.
Aus diesem Grund muss die Erstellung eines Datensatzes aus Rohdateien von einer technischen Person innerhalb der IT-Abteilung übernommen werden, die über die notwendigen Fähigkeiten für eine solche Aufgabe verfügt. Dies führt zu zeitlichen Verzögerungen bei der Wertschöpfung aus den Daten und zu Belastungen (und Engpässen) für die IT. Darüber hinaus können Data Lakes ohne angemessene Governance und Katalogisierung zu einer Müllhalde für Daten werden - dem sprichwörtlichen Datensumpf. Im Laufe der Jahre hat sich der Data-Lake-Ansatz ohne geeignete Tools den Ruf erworben, übermäßig komplex in der Implementierung und Verwaltung zu sein.
Klassisches Data Warehouse auf einem Data Lake
In den meisten Unternehmen existieren traditionelle Data Lakes und klassische Data Warehouses normalerweise nicht völlig getrennt voneinander. Daten aus einem Data Lake können in ein Data Warehouse geladen oder übertragen werden (Abbildung 3). Dies ist kein neues Konzept, da sich Data Warehousing und Data Lakes seit 2010 überschneiden.
Die Anforderungen an die Unternehmensdaten und die Anwendungsfälle sowie die spezifischen Funktionen und Möglichkeiten des klassischen Data Warehouse bestimmen jedoch, in welchem Umfang eine Übertragung stattfindet. Dazu gehört, ob es sich bei den Daten um strukturierte Daten oder halbstrukturierte Daten handelt, wie z. B. gestreamte JSON-Daten, für die das Data Warehouse über eine interne Funktion verfügen muss, um die JSON-Datei aus ihrem nativen und manchmal hierarchischen Dokumentenformat in ein strukturiertes Datentabellenformat umzuwandeln, wie es vom klassischen Data Warehouse erwartet wird. Wenn das Data Warehouse nicht über diese Fähigkeit verfügt, sind externe Tools oder Prozesse erforderlich.
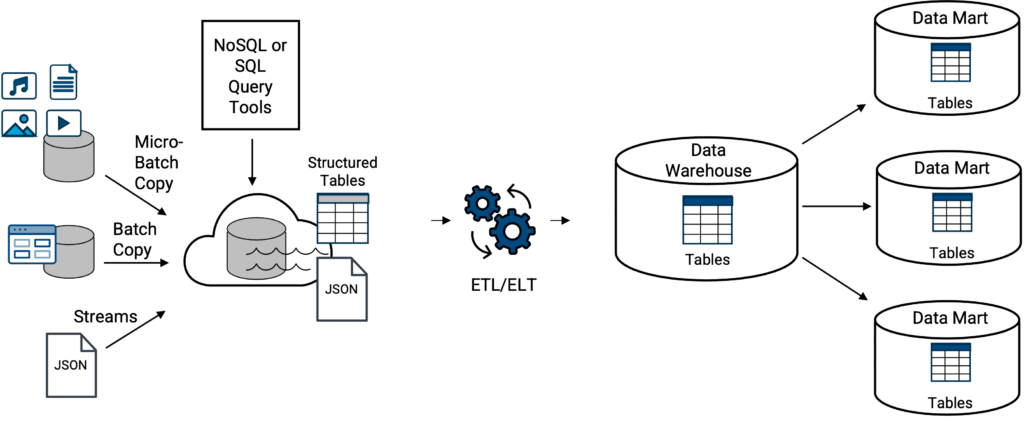
Zu den oben genannten Beispielen für ein klassisches Data Warehouse auf einem Data Lake gehören alle oben genannten klassischen Data Warehouse-Typen, die lose mit einem der oben genannten Data Lakes gekoppelt (integriert) sind, Amazon Redshift auf S3 (auch bekannt als Amazon Spectrum), Azure Synapse auf ADLS, Google Big Query auf Google Cloud Storage und Snowflake auf externem S3 (lesen Sie weiter).
Angesichts des Spektrums zwischen unstrukturierten und strukturierten Daten geben Datenexperten, einschließlich Datenwissenschaftler, an, dass sie die Flexibilität genießen, einzelne Dateien oder Datensätze zu untersuchen. Wenn es jedoch an der Zeit ist, Daten abzufragen und Erkenntnisse und Beziehungen zwischen den Daten aufzudecken, ziehen es die meisten Datenexperten vor, mit Datenbanken und strukturierten Daten (wie bei einem klassischen Data Warehouse) zu arbeiten, anstatt zu versuchen, eine Abfrage über einzelne Rohdateien zu erstellen.
Aus diesem Grund müssen die Erstellung eines Datensatzes aus Rohdateien und die Übertragung von Daten aus einem Data Lake in ein klassisches Data Warehouse von einer technischen Person innerhalb der IT-Abteilung durchgeführt werden, die über die entsprechenden Fähigkeiten verfügt. Da ein Teil der Attraktivität eines Data Lakes darin besteht, Daten direkt im See abzufragen, ist es ein Irrglaube, dass die Erstellung von abfragbaren Datensätzen nicht erforderlich ist, dass dies keine Duplizierung von Daten erfordert und dass dies nur eine Sache des Data Warehouse ist. Strukturierte, abfragbare Datensätze sind in einem Data Lake genauso wichtig.
Insgesamt führt dies zu Verzögerungen bei der Wertschöpfung aus den Daten und zu Belastungen (und Engpässen) für die IT.
Cloud-Data-Warehouses der neuen Generation: Data Lakehouses
Die Rettung sind Cloud-Data-Warehouses der neuen Generation, die seit 2015 auf dem Markt sind. Cloud-Data-Warehouses der neuen Generation unterstützen nicht nur gängige CSV-Dateien und andere Formate, sondern können auch JSON-Dateien (semi-strukturiert) in ihrem nativen Format akzeptieren und laden (Abbildung 4). Von hier aus kann ein Data Warehouse der neuen Generation über integrierte Werkzeuge verfügen, um die JSON-Daten automatisch zu analysieren, alle Array-Strukturen zu reduzieren und eine spaltenorientierte Tabellenversion der JSON-Daten zu präsentieren, die mit Standard-SQL auf relationale Weise abgefragt werden kann, wodurch eine kritische Herausforderung bei Data Lakes und klassischen Data Warehouses auf einem Data Lake gelöst wird. Die besten und funktionsreichsten sowie skalierbaren und wendigen Plattformoptionen (eines Anbieters) für dieses Konzept werden cloudbasierte Lösungen sein.
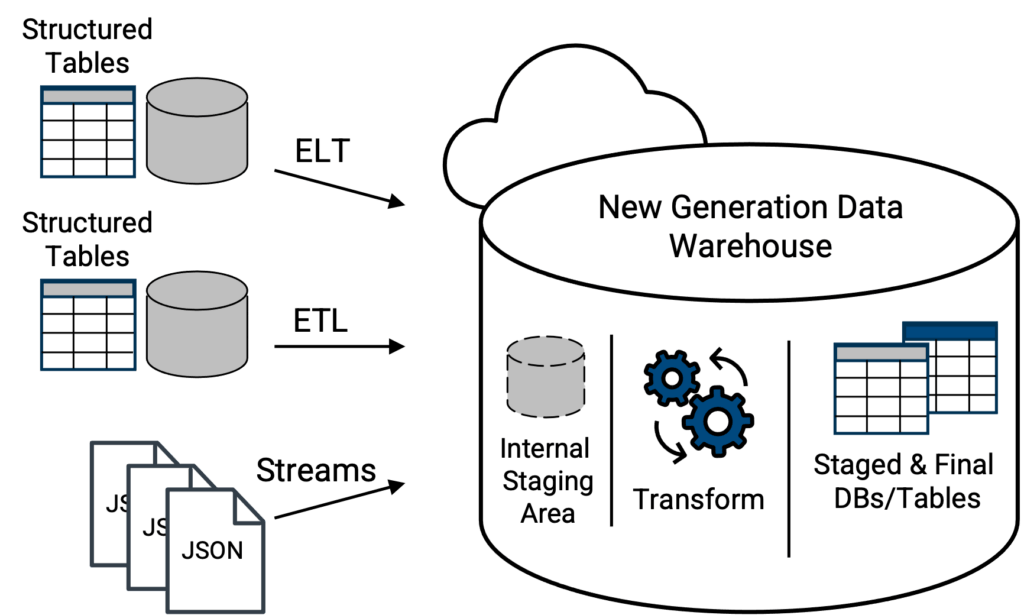
Oben: moderne Topologie, bei der Datentabellen und native JSON-Dateien direkt in ein Data Warehouse der neuen Generation geladen werden. Die Fähigkeiten des Datenintegrationstools zur Mobilisierung von Daten in das Data Warehouse bestimmen, ob die Datentabellen zunächst transformiert werden müssen, damit sie mit der Schemastruktur der Zieltabelle im Data Warehouse übereinstimmen. Ein wirklich modernes Data Warehouse der neuen Generation ist in der Lage, die native JSON-Datei beim Laden zu scannen und in eine abfragefähige Tabellenform umzuwandeln. Die JSON-Datei liegt also nicht mehr in ihrem wörtlichen nativen Format vor, sondern ihre Daten liegen in einer Form vor, die vom Data Warehouse der neuen Generation mit Standard-SQL abgefragt werden kann.
Da die Speicherebene häufig von der Datenverarbeitungsebene getrennt ist, können neue Generationen von Cloud Data Warehouses (oder Datenplattformen, wie sie manchmal genannt werden) im Wesentlichen ein integriertes Data Lake- und Data Warehouse-Komplettpaket anbieten - das Data Lakehouse-Konzept entsteht. Dieses Konzept beseitigt einen Teil der Komplexität typischer Data-Lake-Ansätze. Beispiele hierfür sind Snowflake und Databricks Delta.
Darüber hinaus ermöglicht die Trennung von Rechen- und Speicherebenen diesen beiden Ressourcengruppen eine unabhängige Skalierung und die Nutzung kostengünstiger Speicherelemente, wodurch die Speicherkosten pro Terabyte im Vergleich zu klassischen Data-Warehouse-Ansätzen, die Daten- und Rechenressourcen bei der Skalierung sperren, gesenkt werden.
Da die Data-Warehousing-Technologie der neuen Generation alle schweren Arbeiten zur Umwandlung nicht-relationaler Datendateien in eine relationale Struktur übernimmt, können Business-Analysten, Data Scientists und Data Engineers viel schneller und mit Self-Service einen Mehrwert aus diesen Daten ziehen. Darüber hinaus liefern spaltenformatierte Tabellen für JSON-Daten in der Regel schnellere Analysen, wenn komplexe relationale Abfragen erforderlich sind, verglichen mit der Verwendung von NoSQL-Abfragetools mit JSON in nativer Dokumentenform.
Darüber hinaus bieten einige Data Warehouses der neuen Generation oder Data Lakehouses einen internen Staging-Bereich (Holding), in den JSON-Dateien übertragen werden und in ihrer ursprünglichen Form bleiben können. Snowflake beispielsweise verfügt über einen internen S3-Speicherbereich, der von der Objektspeicherinfrastruktur für seine virtuellen Data Warehouses getrennt ist. Die JSON-Daten können jedoch erst abgefragt werden, wenn sie in das Lakehouse geladen und transformiert wurden. Vorsicht, nicht alle Lakehouses bieten diese Staging-Fähigkeit innerhalb der gleichen physischen Struktur.
Insgesamt beseitigt der Lakehouse-Design-Ansatz einen Großteil der Komplexität typischer Data-Lake-Ansätze, aber auch er hat Nachteile.
Erstens: Je größer das Unternehmen und je mehr Datenexperten es gibt, desto wahrscheinlicher ist es, dass die einzelnen Gruppen nicht alle mit derselben Data Warehouse- oder Data Lakehouse-Lösung arbeiten möchten. Zweitens neigen führende Lakehouse-Anbieter dazu, verbrauchsabhängige Preise zu verwenden, was bedeutet, dass der Zähler immer mit der Nutzung des Lakehouse läuft.
Wenn alle Mitarbeiter in einem Lakehouse/einem Data Warehouse der neuen Generation mit Verbrauchspreisen untergebracht sind, müssen die Ressourcen sorgfältig überwacht und bei Nichtgebrauch abgeschaltet werden. Außerdem sollten Sie Warnmeldungen einrichten, wenn Verbrauchs- oder Kostenschwellenwerte erreicht werden.
Folglich stellen Unternehmen fest, dass die flexibelste Lösung darin besteht, einen Cloud-basierten Data Lake und ein Cloud-Data-Warehouse der neuen Generation, das Lakehouse, nebeneinander zu betreiben, anstatt ein klassisches Data-Warehouse nebeneinander zu betreiben. Dieser Ansatz ermöglicht es dem Data Lake, der primäre Speicher für alle Daten zu sein und gleichzeitig alle Communities zu bedienen und die Flexibilität zu maximieren.
Worauf Sie bei einem Datenintegrationstool achten sollten
Moderne Datenintegrationstools können die Mobilisierung großer Datenmengen in oder aus einem der Konzepte Data Warehouse, Data Lake oder Data Lakehouse erleichtern und automatisieren. Mit diesen Tools können Sie Daten aus einer Vielzahl von Quellen abrufen. Dies spart Zeit und Aufwand bei der Aufbereitung der Daten für die Analyse, so dass Sie Ihre Analyseprojekte beschleunigen können.
Moderne Datenintegrationstools stellen auch sicher, dass die Daten im richtigen Format und in der richtigen Struktur vorliegen, was die Abfrage und Analyse erleichtert. Außerdem verfügen diese Tools häufig über Funktionen, die die Sicherheit der Daten und die Einhaltung von Vorschriften gewährleisten.
Wenn Sie zum ersten Mal eine Unternehmensdatenplattform einrichten, sollten Sie sich für ein Datenintegrationstool entscheiden, das einfach und intuitiv zu bedienen ist. Idealerweise entscheiden Sie sich für ein Tool mit Drag-and-Drop-Funktionalität und der Möglichkeit, Daten innerhalb der Datenplattform visuell umzuwandeln, so dass die Arbeit mit Daten für verschiedene Qualifikationsniveaus einfach ist. Erfahren Sie mehr darüber, wie Sie Daten in Ihrem Unternehmen integrieren und automatisieren können.




