Einführung
Viele SnapLogic-Kunden kombinieren die SnapLogic Intelligent Integration-Plattform mit einer Vielzahl von Tools, um eine End-to-End-Kontrolle des Lebenszyklus von Pipelines und anderen Assets zu erreichen. Solche Prozesse können die automatische Generierung von Helpdesk-Tickets bei Fehlern, manuelle und automatisierte Überprüfungsprozesse durch Versionskontrollsysteme, kontinuierliche Integration und kontinuierliche Bereitstellungspipelines sowie Einheitstests und Compliance- und Qualitätsprüfungen des Unternehmens umfassen.
Da Unternehmen unterschiedliche Richtlinien, Anforderungen, Prozesse und Toolchains haben, gibt es keine einheitliche Empfehlung oder Lösung für eine durchgängige Lebenszyklusverwaltung und Automatisierung, die für alle gilt.
In dieser Blogpost-Reihe möchten wir Ihnen eine Reihe von Herausforderungen vorstellen, mit denen Unternehmen im Zusammenhang mit der modernen Integrationsentwicklung konfrontiert sind, und wie Sie diese Herausforderungen mit SnapLogic problemlos bewältigen können. Insbesondere werden in dieser Serie auch typische Benutzer-Personas beschrieben, die mit oder um Ihre Integrationen herum involviert sind, und wie die Kombination von SnapLogic und anderen Tools helfen kann, den Lebenszyklus dieser Integrationen zu automatisieren und zu steuern.
In Teil 1 erfahren Sie, wie die SnapLogic-Plattform
- Fehler automatisch erfassen,
- übernimmt die Fehlerberichterstattung, indem es automatisch Tickets mit detaillierten Fehlerinformationen erstellt und
- Integratoren und Testteams bei der Lösung von Problemen zu unterstützen, wobei der Schwerpunkt auf Wiederverwendung und Benutzerfreundlichkeit liegt.
Persönlichkeiten
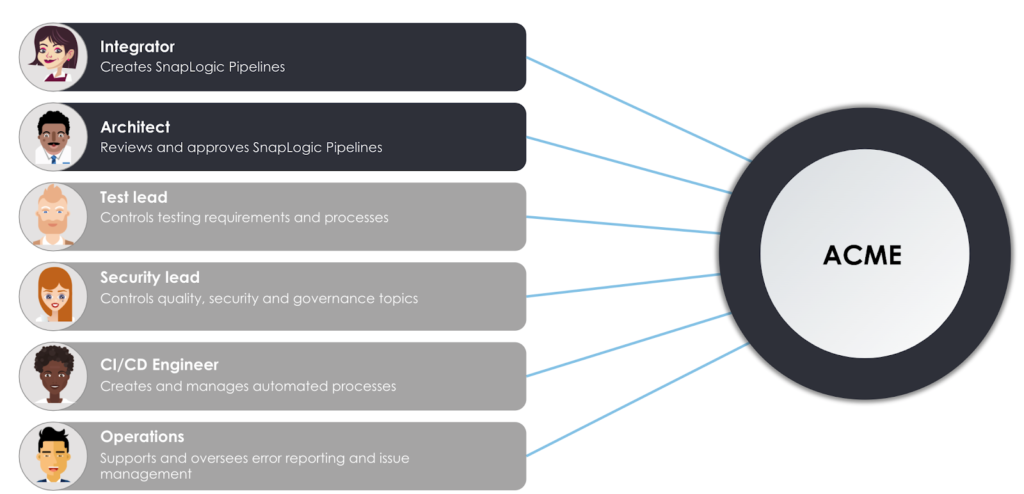
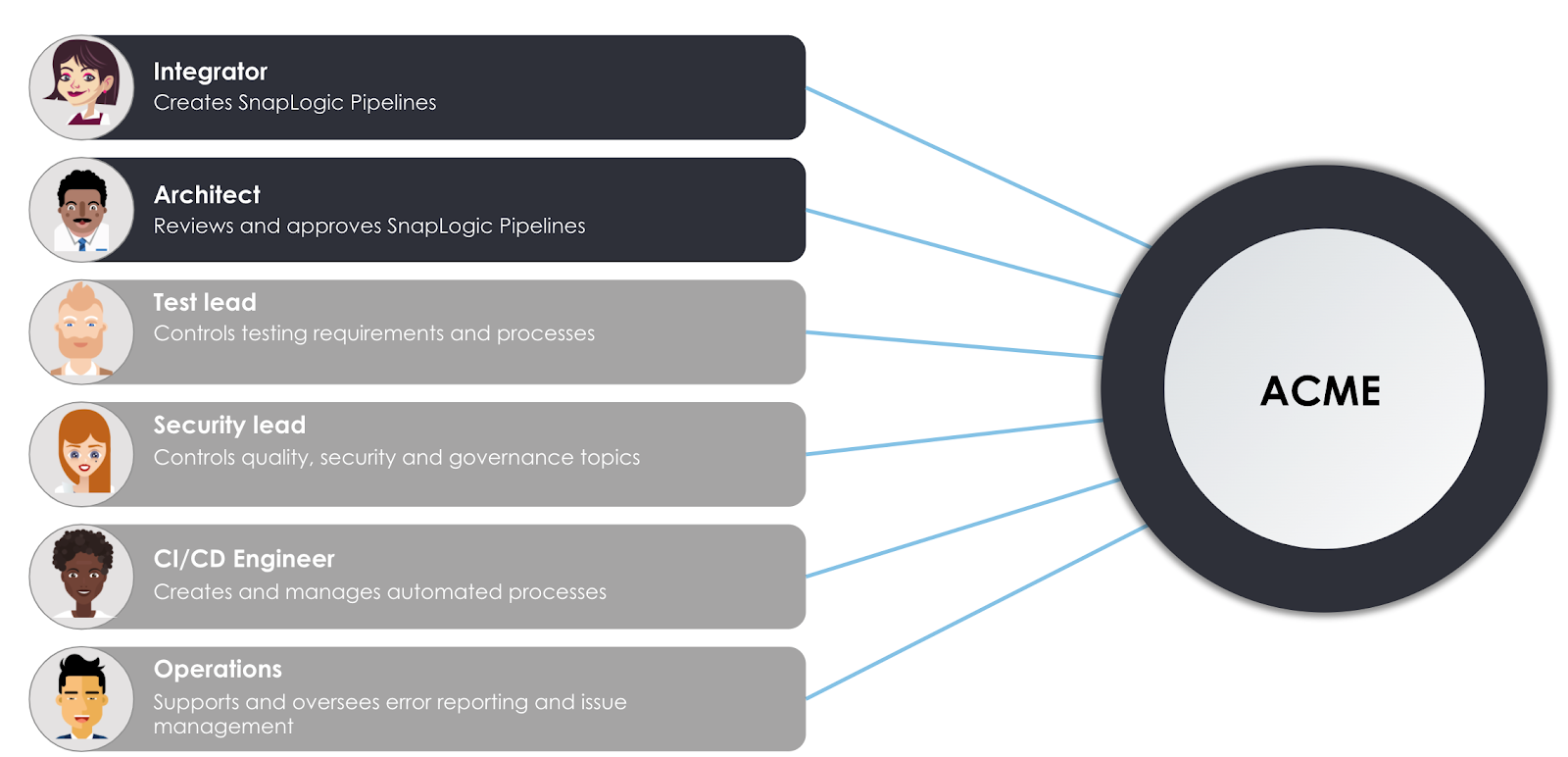
Betrachten Sie die oben genannten Benutzer-Personas, die in das fiktive Unternehmen ACME involviert sind.
- Die Integrator ist für die Arbeit mit der SnapLogic Intelligent Integration Plattform verantwortlich, um Pipelines zu entwerfen und zu erstellen, die die Geschäftsanforderungen des Unternehmens unterstützen. Sie ist auch an der Überprüfung der Pipelines ihrer Kollegen beteiligt und bittet ihre Kollegen, ihre Arbeit zu überprüfen, während sie zwischen Entwicklung und Produktion Umgebungen
- Ihr Kollege, der Architektist eine erfahrene Rolle, die für die Überprüfung von Pipelines und anderen Änderungen an Assets verantwortlich ist, die zwischen den Organisationen verschoben werden. Sie werden sehen, dass der Integrator und Architekt eine Schlüsselrolle bei der Bereitstellung der Integrationen für das Unternehmen spielen. Es gibt jedoch noch weitere Rollen, die dafür sorgen, dass die Integrationen reibungslos, automatisiert, geregelt und getestet werden.
- Die Testleiter wendet die allgemeinen Testrichtlinien und -verfahren des Unternehmens auf das SnapLogic-Tool und die Prozesse an. Insbesondere wird er sicherstellen, dass Integratoren die Testabdeckung in Form von Unit-Tests zusammen mit den erstellten Pipelines bereitstellen.
- Ähnlich verhält es sich mit dem Leitung Sicherheit für die Datensicherheit und die Qualitätskontrollen des Unternehmens zuständig. In unserem Szenario gibt sie eine Reihe von Richtlinien vor, an die sich die Pipelines halten müssen.
- Um die Prozesse zu automatisieren, muss der CI/CD-Ingenieur eine Reihe von Tools und Diensten, um automatisierte Pipelines auf der Grundlage von Schritten im Lebenszyklus zu erstellen. Insbesondere erstellt er Prozesse zur Automatisierung von Unit-Test-Prüfungen, Qualitätsprüfungen und Pipeline-Promotionen zwischen der Entwicklung und Produktion Umgebungen.
- Schließlich bietet SnapLogic zwar eine Live-Schema-Introspektion und -Validierung zur Unterstützung von Integratoren zu helfen, stabile und vorhersehbare Pipelines zu erstellen, muss ein Fehler in einer Produktionspipeline erkannt und eine Warnung generiert werden. Die Betrieb Rolle reagiert auf Fehler in der Produktion und überwacht den Lebenszyklus von Helpdesk-Tickets - von der Erstellung bis zur Lösung.
Hinweis: Die oben genannten Rollen und Verantwortlichkeiten dienen als Richtlinie und sind nicht unbedingt auf alle SnapLogic-Kunden anwendbar. Beispielsweise werden nur wenige der oben genannten Rollen von ein und derselben Person in einer Organisation wahrgenommen.
SnapLogic Pipeline-Lebenszyklus-Automatisierung
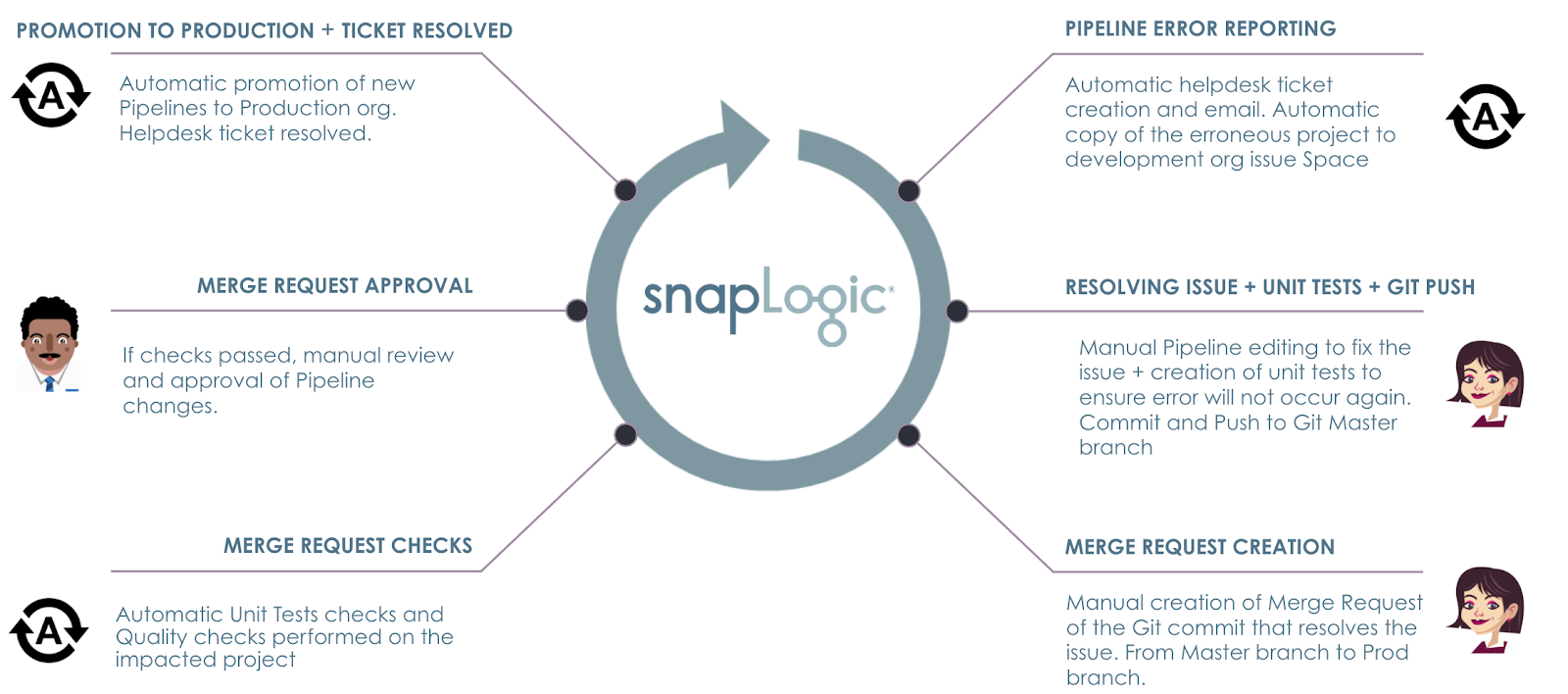
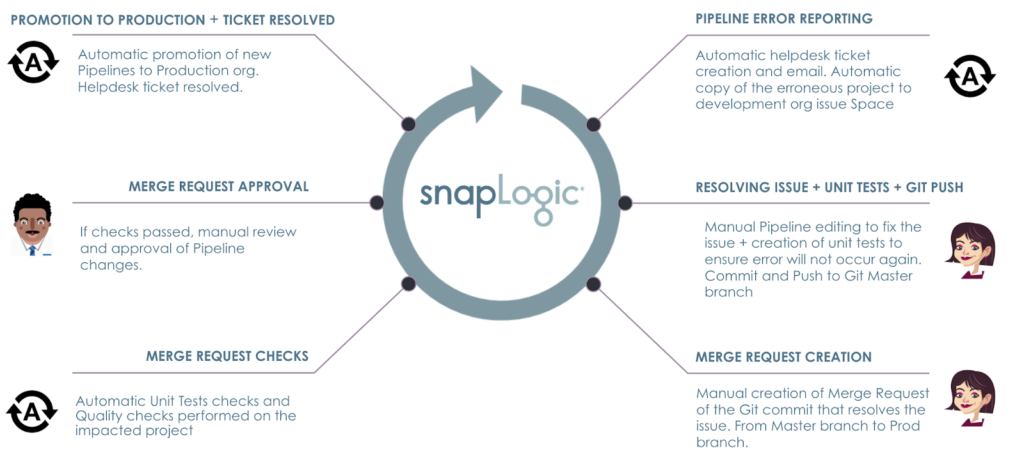
Stellen Sie sich folgendes Szenario vor: Ein Fehler tritt in einem der Produktion Pipelines. Das Ziel ist es, automatisierte Prozesse einzurichten, die sicherstellen, dass
- Der Fehler wird mit Hilfe des Helpdesk-Tools und des Warnsystems von ACME erfasst und gemeldet, das von Betrieb.
- Eine Kopie des Pipeline-Projekts kann sofort die Aufmerksamkeit des Integrator um mit der Behebung des Problems in der Entwicklung org.
- Unit-Tests und Qualitätsprüfungen werden vor der Architekt die Änderungen freigibt.
- Nach der Genehmigung werden die Pipelines automatisch in die Produktion org befördert, wodurch der Fehler effektiv behoben wird.
- Helpdesk-Ticket wird bei Beförderung automatisch geschlossen und eine Aktualisierung an die Betrieb.
Die Schritte des ACME-Szenarios sind im Folgenden dargestellt.
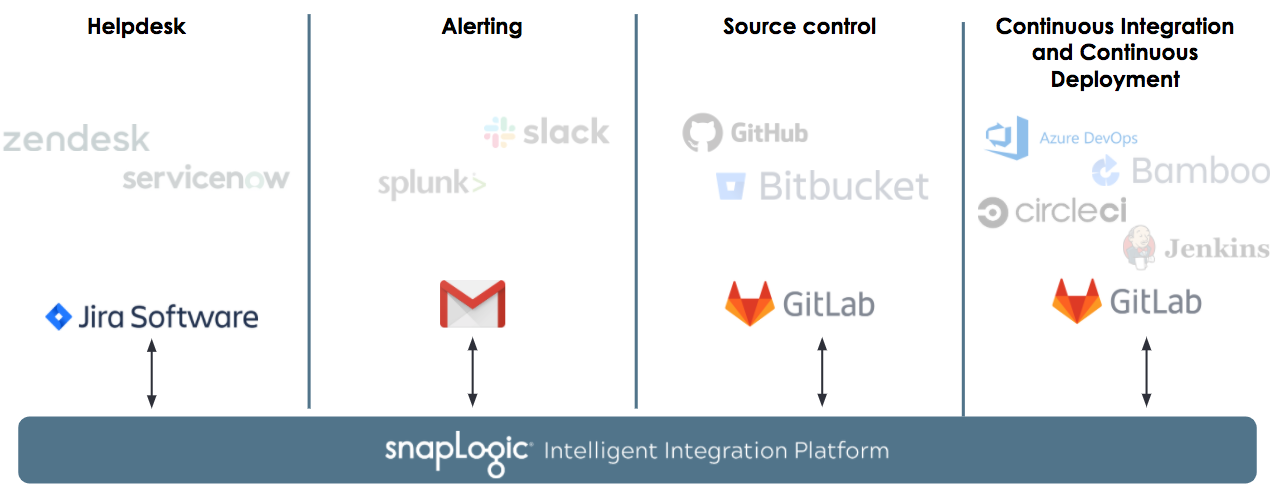
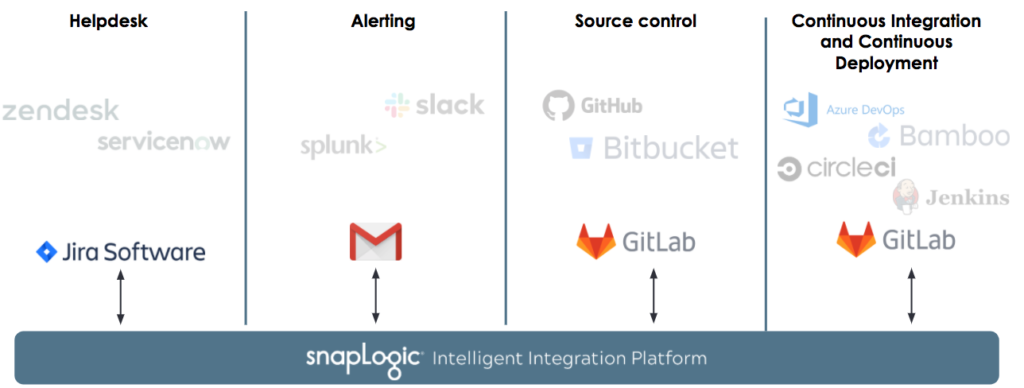
Wie bereits zu Beginn dieses Beitrags erwähnt, können die Helpdesk-Systeme, Fehler- und Alarmierungs-Tools, Versionskontrollsysteme und Tools für die kontinuierliche Integration bei den Kunden unterschiedlich sein. SnapLogic funktioniert nahtlos, unabhängig von dem von Ihnen gewählten Tool und wir haben keine empfohlene oder Standard-Toolchain für diesen Prozess. Für diesen Blogbeitrag hat das fiktive Unternehmen ACME die folgenden Tools ausgewählt.
Pipeline-Fehlerberichte
ACME hat die geschäftliche Anforderung, sein altes CRM auf Salesforce zu migrieren. Zu diesem Zweck erhält CustomerToSalesforce, eine SnapLogic-Pipeline, bestehende Kundendatensätze aus dem alten CRM über einen Ausgelöste Aufgabe der eine REST-API offenlegt.
- Die Assets für diese Integration befinden sich in einem Projekt namens CRM_MIGRATION im Verzeichnis Produktion Organisation.
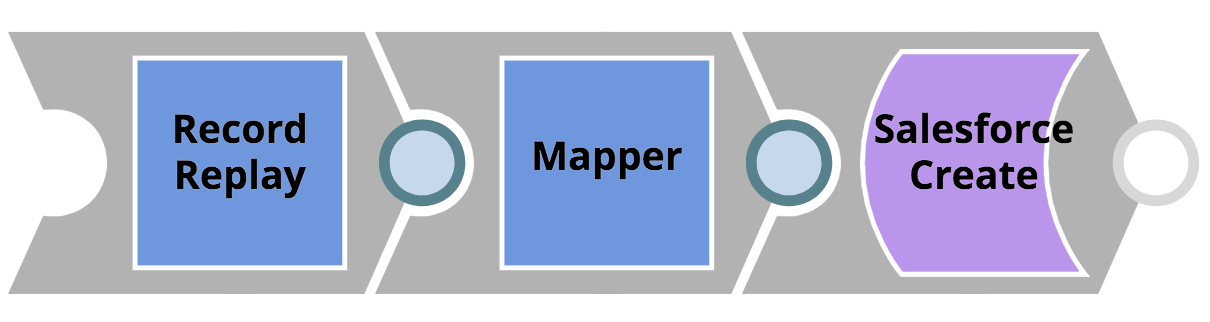
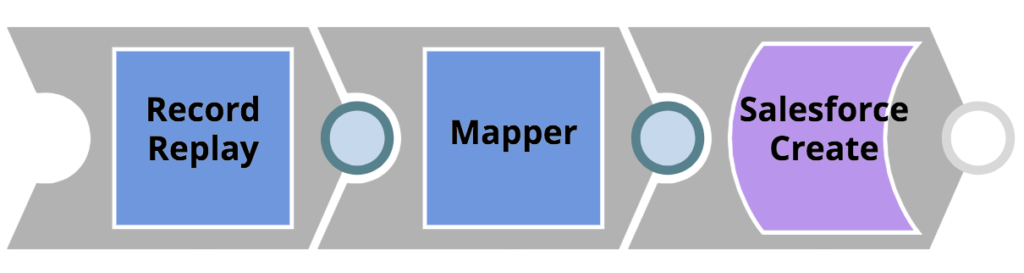
- Die im REST-Aufruf übergebenen Kundendatensätze werden auf ein Salesforce-Objekt abgebildet. Bevor der Mapper-Snap das Mapping anwendet, wird ein Datensatz-Wiedergabe-Snap verwendet, um das eingehende Objekt im Dateisystem zu speichern - so können die Kundendaten im Falle eines möglichen Problems nachträglich untersucht werden. Diese sehr einfache Pipeline ist unten dargestellt.
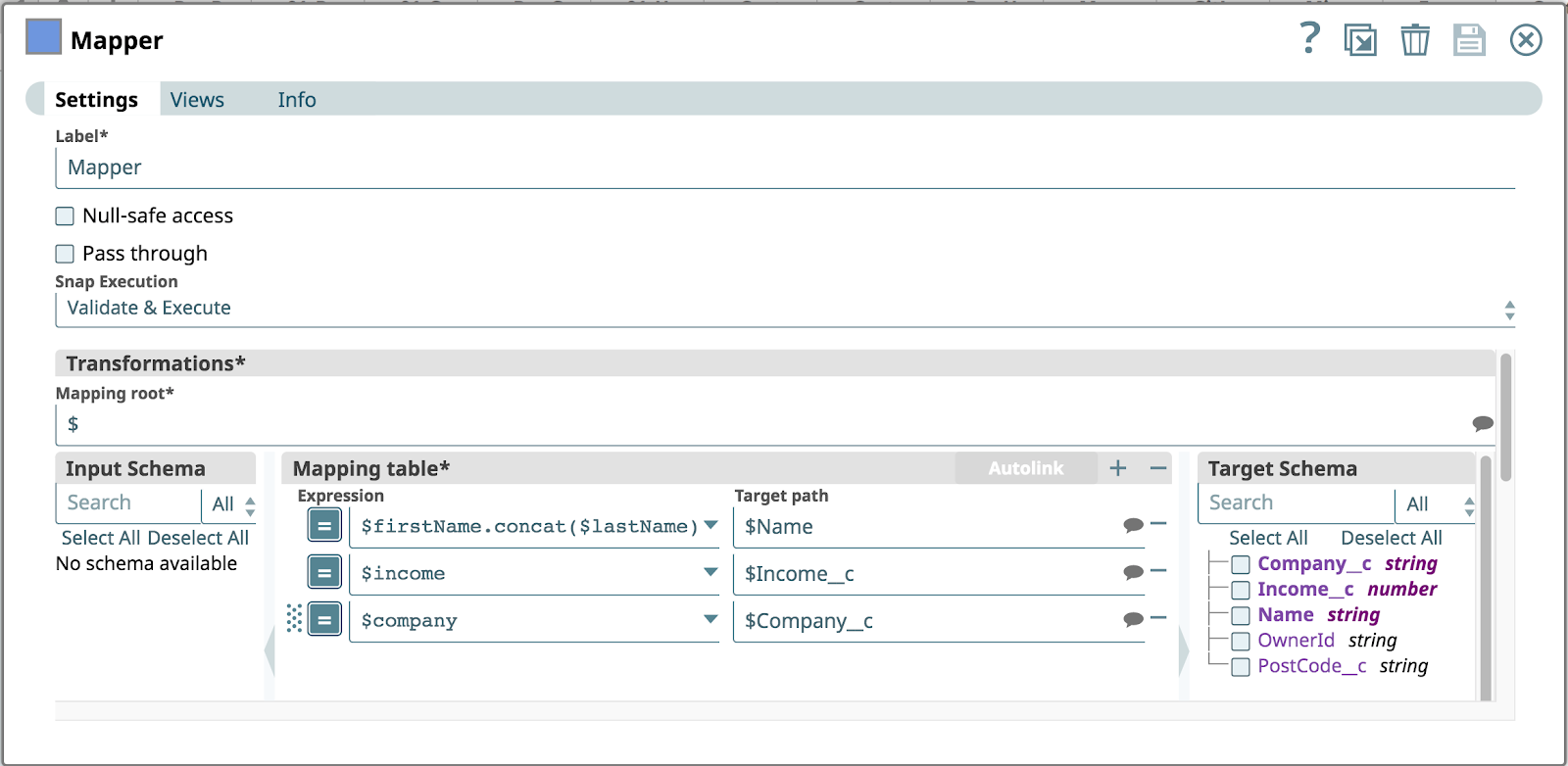
Die folgende Abbildung zeigt die Konfiguration des Mapper Snap. Es wird davon ausgegangen, dass der eingehende REST-Aufruf die folgenden Objekte im JSON-Body enthält: firstName, Nachname, Unternehmen und Einkommen. Das Salesforce-Objekt verfügt nicht über einen Vornamen oder Nachnamestattdessen wird eine Zuordnung erstellt, um den Vornamen mit Nachname zu einem einzigen Name Eigenschaft.
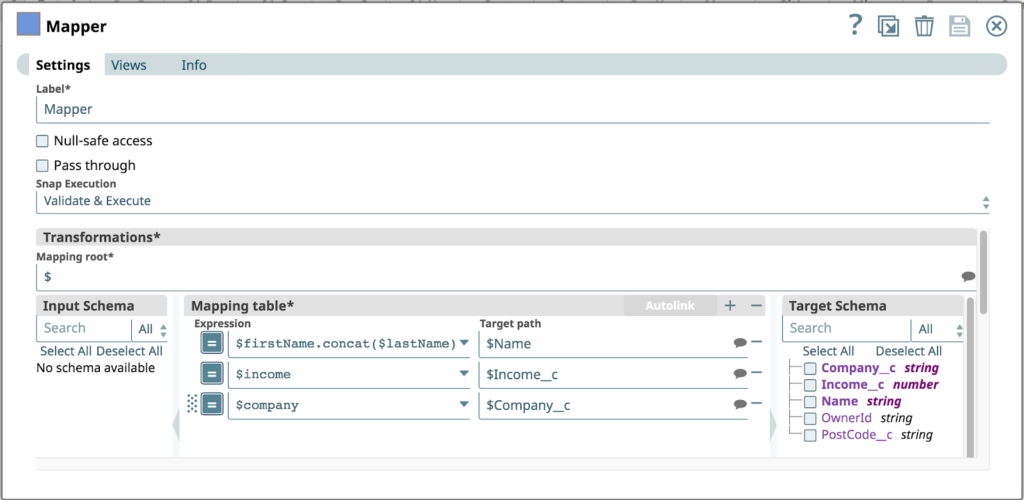
Können Sie bereits die potenziellen Design- und Datenfehler dieser Pipeline erkennen?
Ja, Sie haben es erfasst! Die Pipeline geht davon aus, dass Legacy-CRM alle erforderlichen Eingaben liefert. Da ACME seine Prozesse und Kontrollen nicht rechtzeitig eingerichtet hat, gelangte diese Pipeline ohne Einheitstests oder Qualitätsprüfungen in die Produktion.
Leider übergibt das Legacy-CRM, das die REST-API aufruft, ein Kundenobjekt, in dem der Vorname Parameter fehlt. Infolgedessen wird der erste Ausdruck in der Mapping-Tabelle zu einem Fehler, da die Verknüpfungsoperation fehlschlägt.
Die SnapLogic-Plattform bietet Fehler-Pipelines für jeden Snap, um solche Fehlerfälle zu behandeln. Die folgenden Ereignisse finden nun statt.
- Der Fehler wird von einer Fehlerpipeline abgefangen.
- Die Fehlerpipeline erstellt ein JIRA-Ticket und alarmiert Betrieb durch Versenden einer E-Mail
- Die Fehlerpipeline kopiert das betroffene Projekt aus der Produktion Umgebung in einen Issue Space in der Entwicklung Umgebung
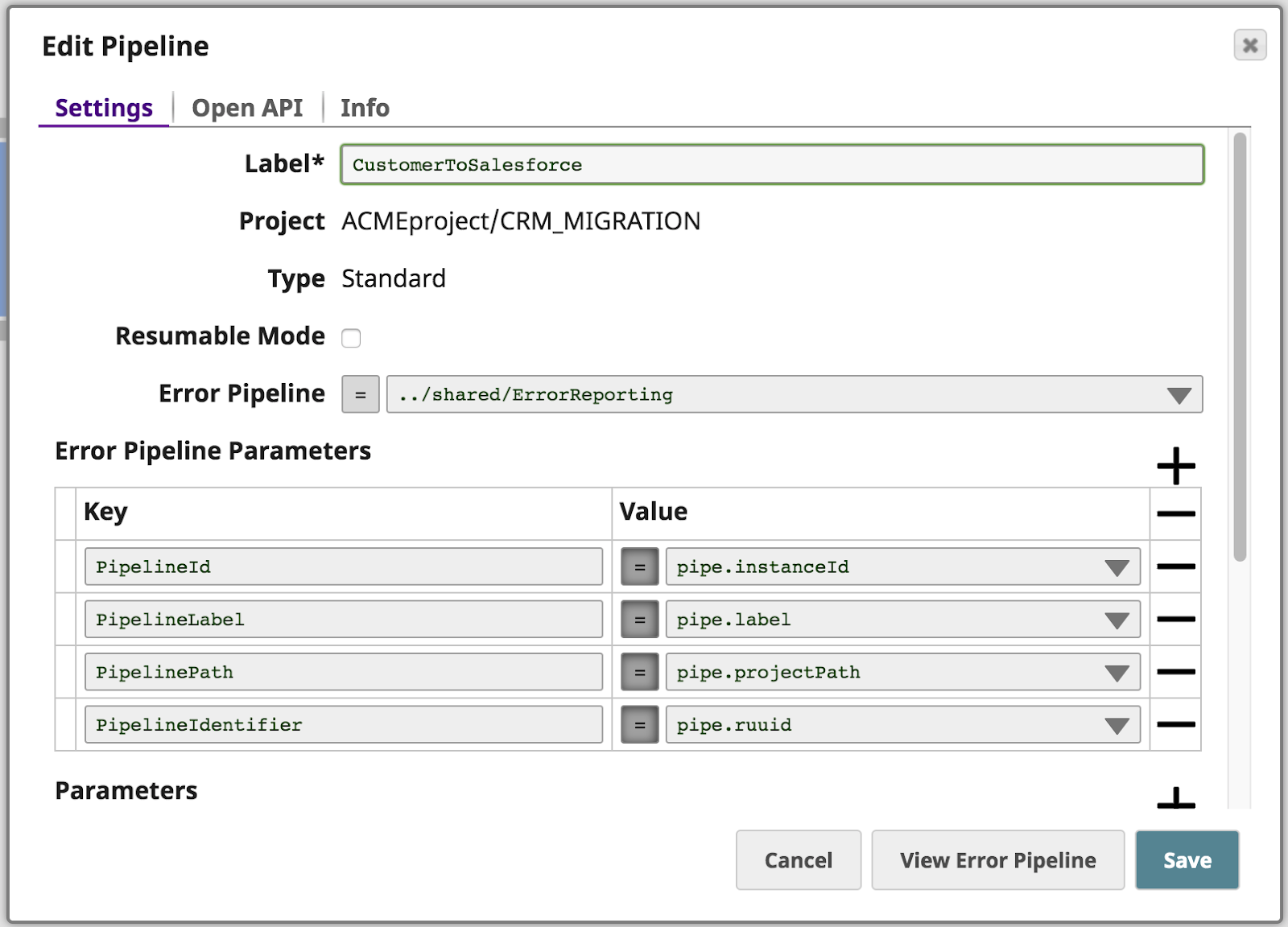
Zusätzlich zur Weiterleitung des Fehlers, der aufgrund der fehlenden Vornamen Parameter aufgetreten ist, übergibt die Pipeline ein paar Pipeline-Eigenschaften als Parameter an die Fehlerpipeline namens ErrorReporting.
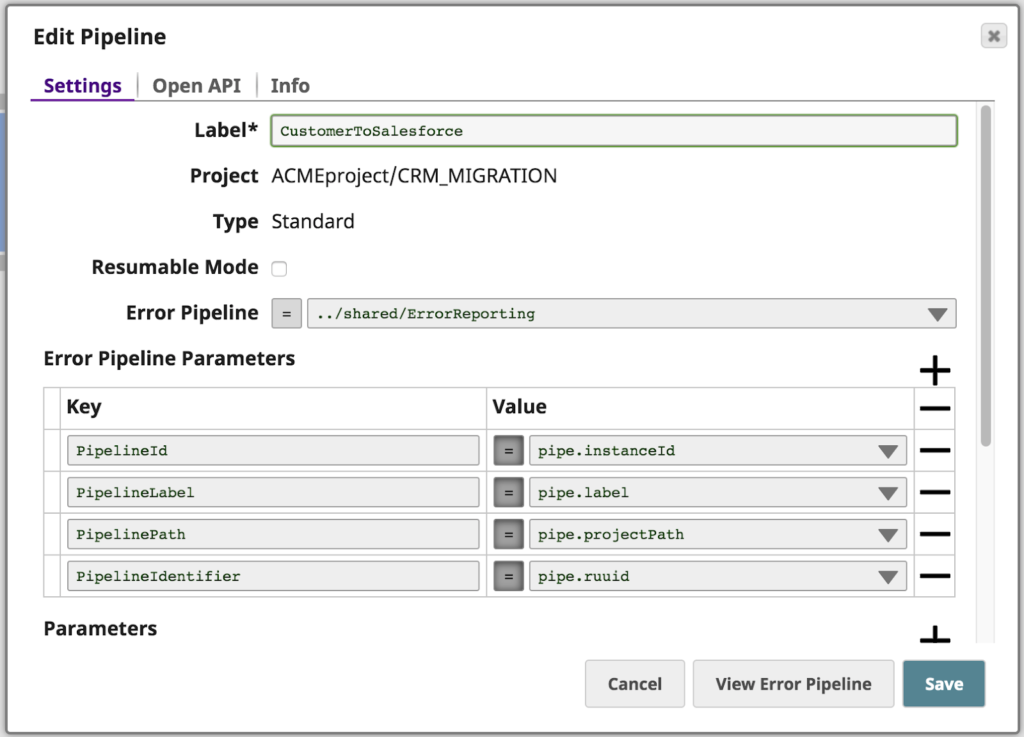
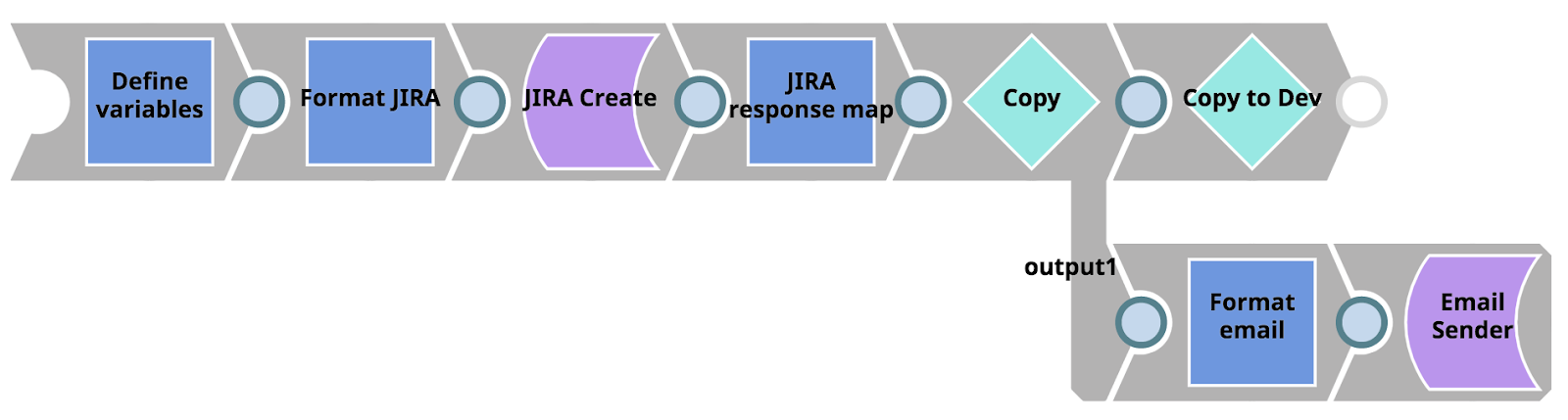
Die Fehlerpipeline ist im Folgenden dargestellt. Zunächst nimmt sie Fehlerinformationen und Pipeline-Parameter auf und ordnet sie dem JIRA-Snap erstellen. Dann nimmt sie die Antwort von JIRA (insbesondere die resultierende JIRA-Ticket-URL) und übergibt das Dokument über den Copy Snap an zwei Zweige. Der obere Zweig übergibt das Dokument an eine andere Pipeline mit dem Pipeline Ausführen Snap. Die untere Verzweigung formatiert die Informationen zu einer HTML-E-Mail, die an folgende Empfänger gesendet wird Vorgänge unter Verwendung des E-Mail-Absender-Snap.
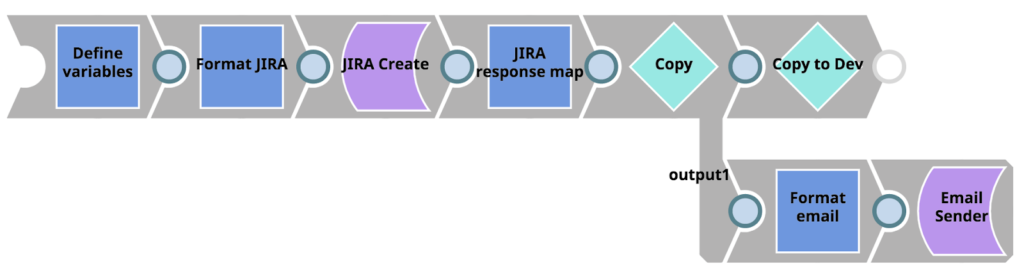
Konzentrieren wir uns zunächst auf die untergeordnete Pipeline, die von unserer Fehler-Pipeline über den Pipeline-Ausführungs-Snap aufgerufen wird (mit der Bezeichnung "Copy to Dev"). Diese Pipeline nutzt einfach die Vorteile des Metadaten-Snap-Paket um Assets aufzulisten, abzurufen, zuzuordnen und zu aktualisieren zwischen dem Projekt in der Produktion Umgebung und dem Issue Space in der Entwicklungsumgebung Umgebung. Wenn die Pipeline abgeschlossen ist, stehen exakte Kopien der Projekt-Assets, bei denen der Fehler aufgetreten ist, für den Integrator mit der Arbeit in der Entwicklung org.
Es ist wichtig, dass Sie nicht versuchen, das Problem in der Produktion org zu lösen - unter Umgehung bestehender Prozesse und Kontrollen.

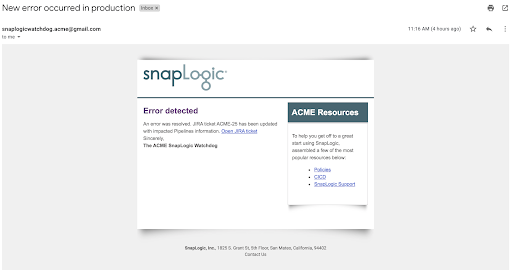
Zweitens: Sehen wir uns das Ergebnis der anderen Aktionen an, die von der Fehler-Pipeline durchgeführt werden. Das folgende Bild zeigt die E-Mail, die automatisch an folgende Adresse gesendet wurde Vorgänge. Sie enthält einige relevante Links, vor allem aber verweist sie auf das automatisch erstellte JIRA-Ticket.
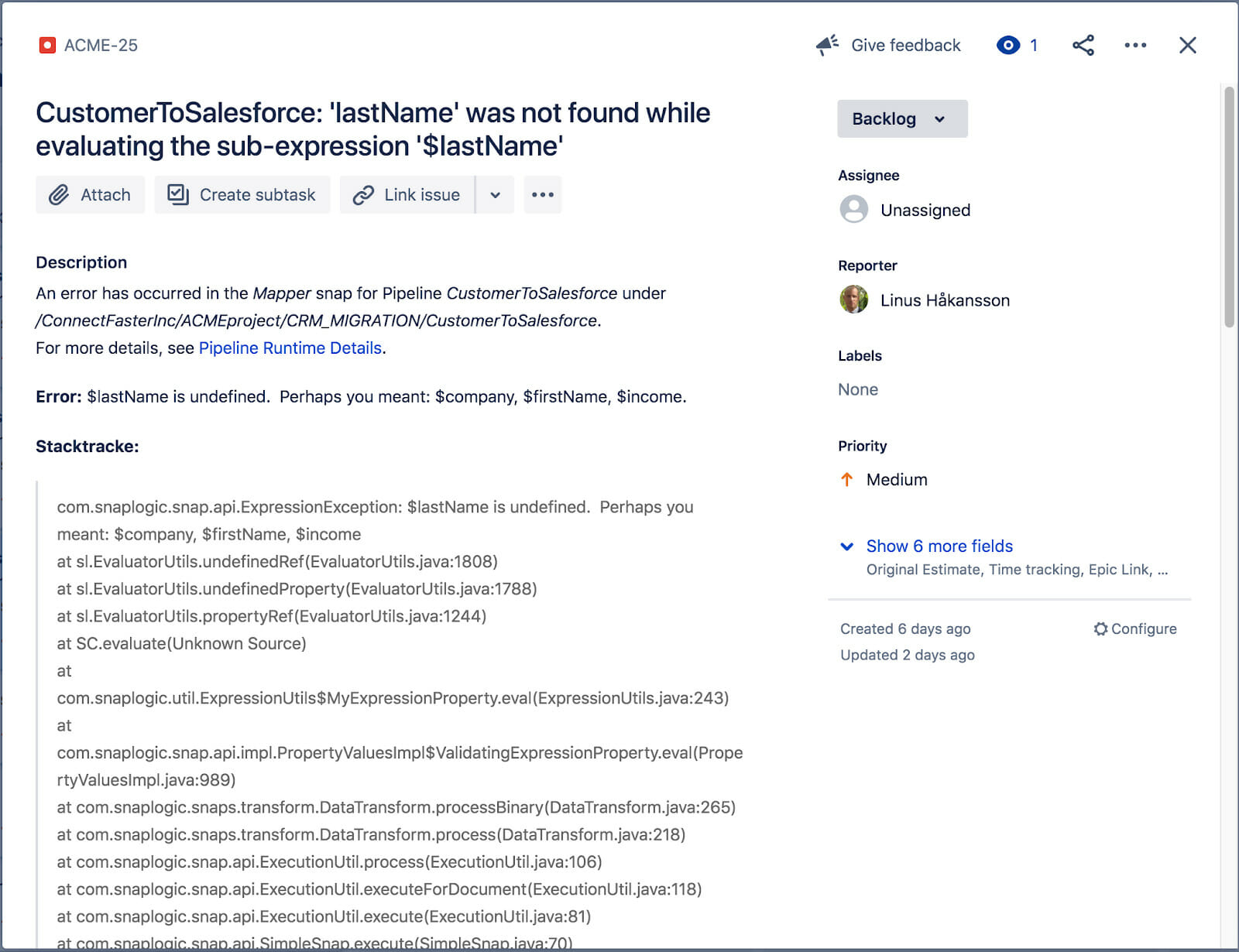
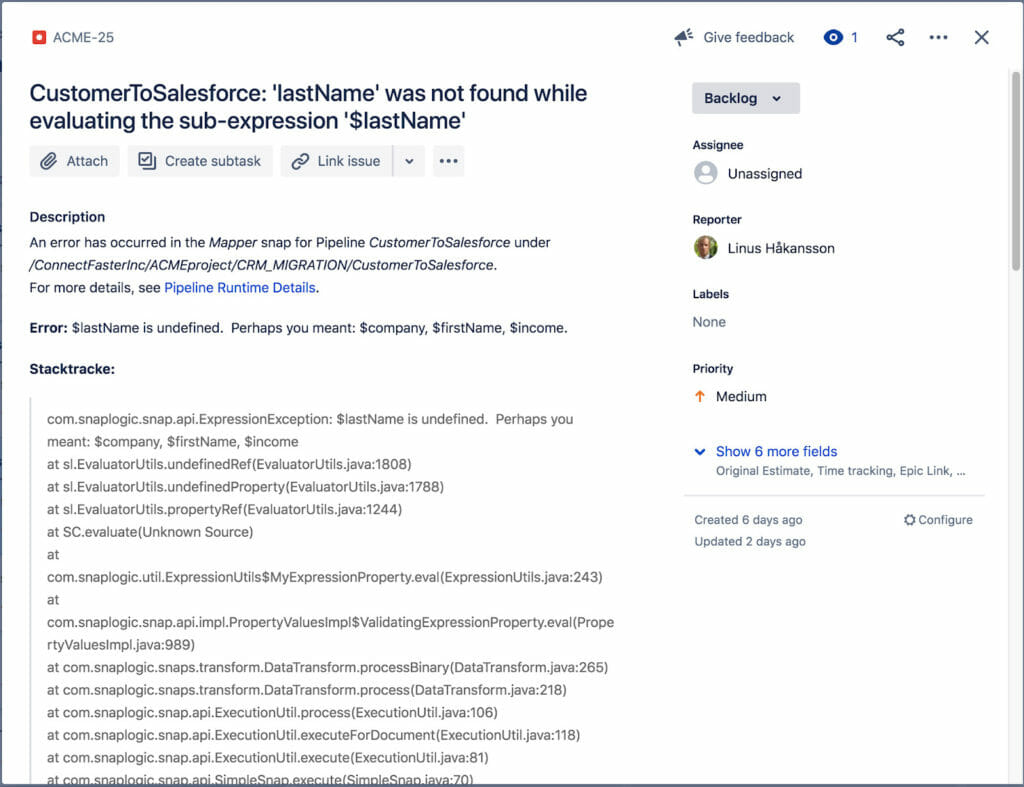
Das verknüpfte JIRA-Ticket ist unten zu sehen. Es enthält den Fehlertitel, die Beschreibung, den Stacktrace, die Auflösung (nicht auf dem Bildschirm) sowie einen Link zu den tatsächlichen Laufzeitdetails der Pipeline-Ausführung, bei der der Fehler aufgetreten ist. Unser Vorgänge und Integrator haben nun genügend Informationen, um mit der Lösung des Problems zu beginnen.
Das folgende Bild zeigt schließlich die neu kopierte CRM_MIGRATION Projekt (das die CustomerToSalesforce-Pipeline und die Aufgabe enthält), das aus der Produktion Umgebung in die Entwicklung Umgebung in den Issue Space (ACMEissues).
Fehlerbehebung + Unit Tests + Git Push
Unser Integrator ist nun in der Lage, sich selbst dem hoch priorisierten Problem zuzuordnen und mit ihrer Arbeit zu beginnen. Da sie nun die richtigen Testanforderungen und Richtlinien von ihrem Testleiterhat, wird sie auch Unit-Tests erstellen, um sicherzustellen, dass der Fehler nicht mehr auftritt. Wenn sie fertig ist, wird sie die "Gitlab Push Pipeline" verwenden, um eine neue Übergabe an den Master-Git-Zweig vorzunehmen.
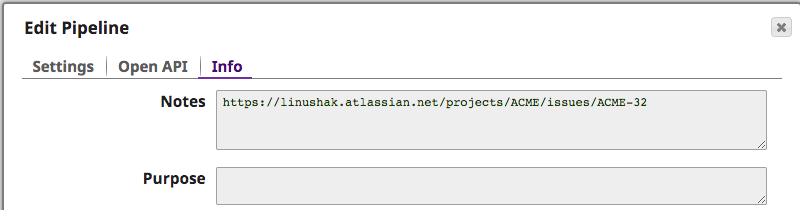
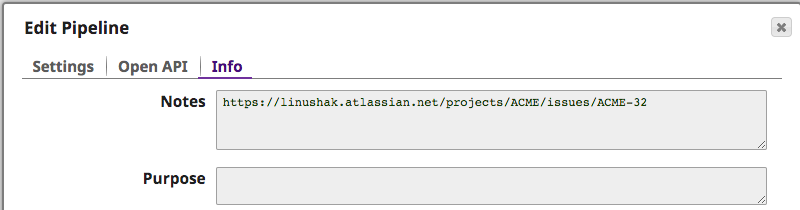
Um besser zu verstehen, welcher Fehler das Problem verursacht hat, kann der Integrator die Anmerkungen der kopierten Pipeline einsehen, die das Problem verursacht hat. Das JIRA-Ticket wurde automatisch eingefügt, um weitere Informationen zu liefern, wie unten zu sehen ist.
Die Testleiter empfiehlt die folgende Logik zur Aktivierung von Einheitstests für die Pipelines.
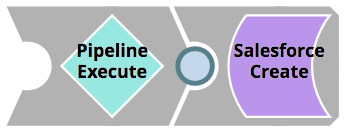
Break out the logic into a separate Pipeline. This will not only make unit testing easier, but also enable reuse of components. This Pipeline should be called <Pipeline_name>_target. The original Pipeline should now instead have a Pipeline Execute Snap that executes the Pipeline housing the logic.
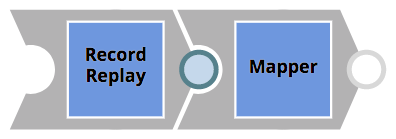
- Create a pipeline as <Pipeline_name>_test der Testdaten lädt und die <Pipeline_name>_target Pipeline mit diesen Daten. Anschließend wird das Ergebnis in einer separaten Datei gespeichert.
- The test data should reside in a file as <Pipeline_name>_input.json
- The result data should be written to a file as <Pipeline_name>_result.json

Hinweis: Wie die Tests tatsächlich ausgeführt werden, wird in einem späteren Schritt in diesem Beitrag behandelt.
Die Integrator passt ihre CustomerToSalesforce-Pipeline wie oben beschrieben an und erstellt die Pipelines CustomerToSalesforce_target (für die Logik) und CustomerToSalesforce_test (zum Lesen und Speichern von Eingabe-/Ausgabedaten). Um sicherzustellen, dass die erforderlichen CRM-Kundeneigenschaften vorhanden sind, und um den Fehler effektiv zu beheben, passt sie die Logik-Pipeline wie folgt an
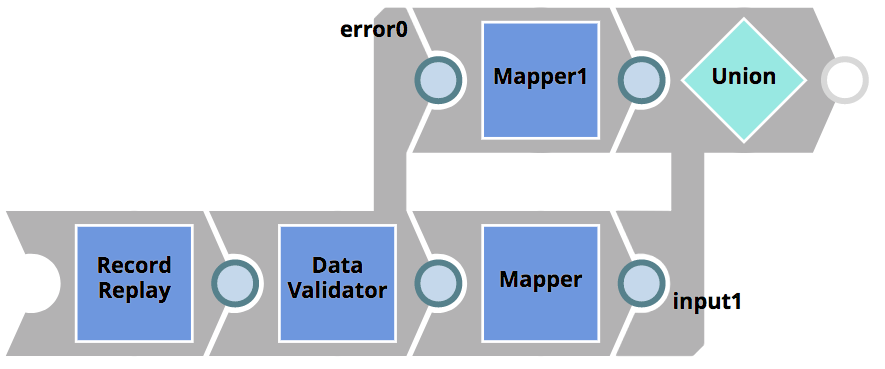
Die Daten-Validator Snap wird verwendet, um das Vorhandensein der erforderlichen Eigenschaften zu prüfen (d.h. Vornamen und Nachname). Wenn die Prüfungen nicht erfolgreich sind, wird das Dokument an die Fehleransicht weitergeleitet, bevor es an den Client zurückgegeben wird. Mit dieser Logik hat der alte CRM-Client die Möglichkeit, auf den Fehler zu reagieren.
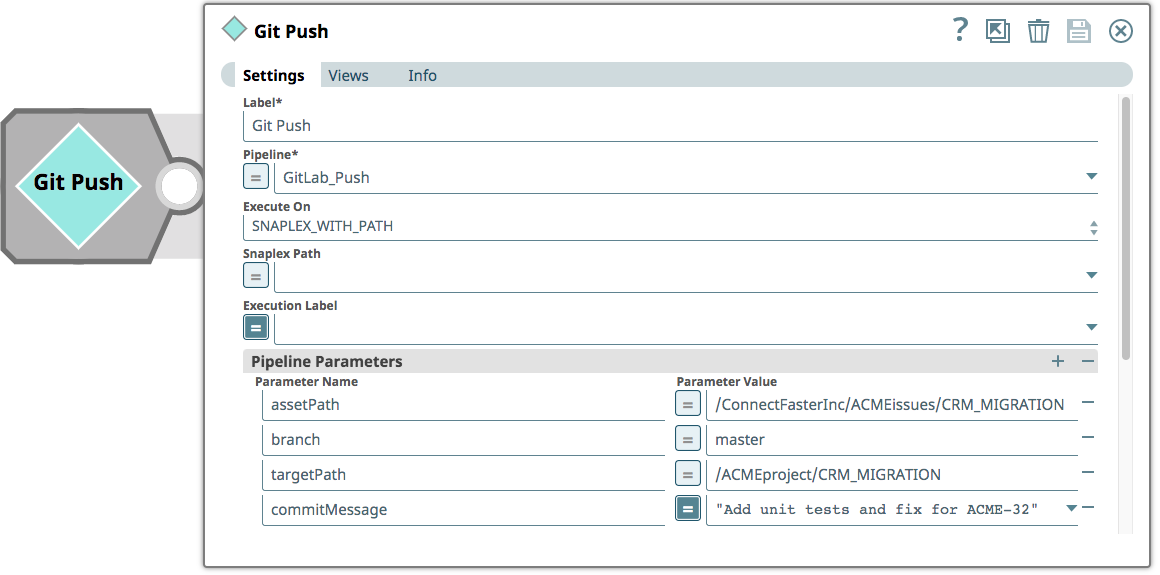
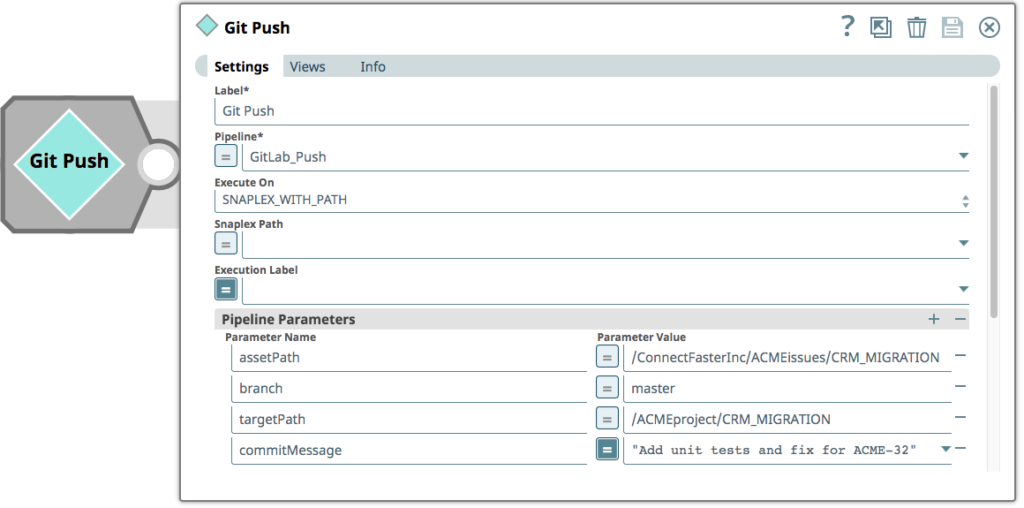
Schließlich überträgt der Integrator die Pipelines in den Master-Zweig des GitLab-Repositorys. Die Pipeline, mit der eine Übergabe an GitLab angestoßen wird, besteht aus einem einzigen "Pipeline Execute"-Snap, der Parameter für den Asset-Pfad (das Projekt, in dem nach Änderungen gesucht werden soll), den Zweig (im GitLab-Repository), einen Zielpfad (das eigentliche Projekt - das Git-Repository enthält keine Verweise auf Umgebungen) und eine Übergabemeldung (in diesem Fall die JIRA-Ticketnummer) enthält.
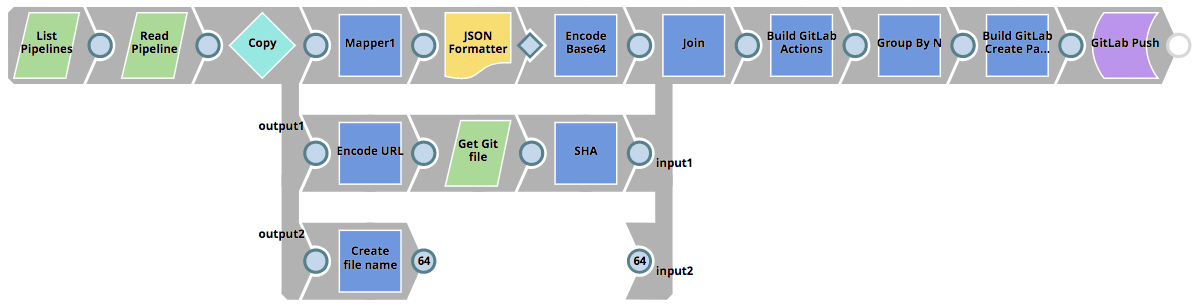
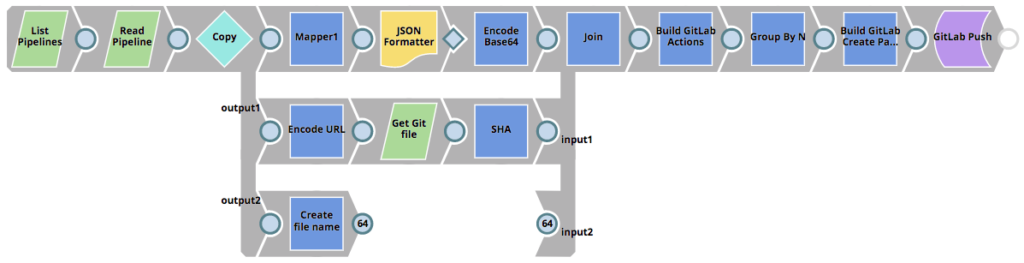
Die aufgerufene Pipeline GitLab_Push ist unten zu sehen. Sie liest alle Pipelines im ausgewählten Projekt, bestimmt, ob die Pipelines im Git-Repository erstellt oder aktualisiert werden sollen (falls bereits ein SHA existiert) und schiebt dann eine Übergabe an GitLab.
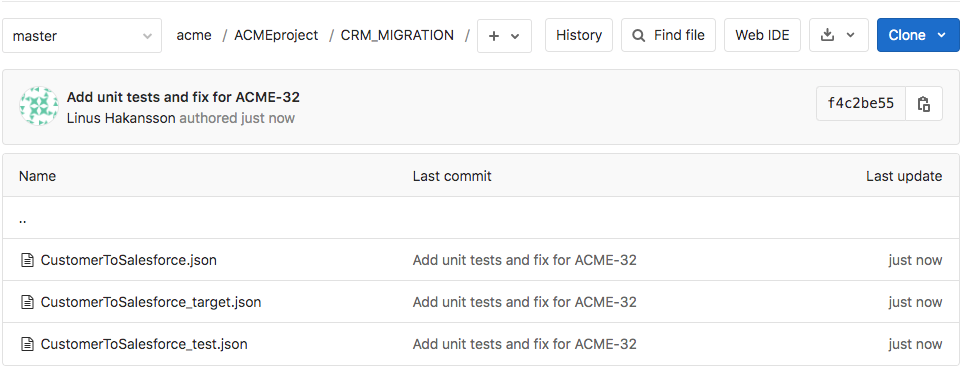
Das Ergebnis der Ausführung der GitLab_Push-Pipeline wird im GitLab-Repository angezeigt, wie in der folgenden Abbildung dargestellt. In der Abbildung ist derzeit der Master-Zweig ausgewählt und der Dateibrowser zeigt die Dateien im Verzeichnis ACMEproject/CRM_MIGRATION an. Die Änderungen an der CustomerToSalesforce-Pipeline sowie die beiden neuen Unit-Test-Pipelines wurden dem Repository als Teil der Übergabe hinzugefügt.
In Teil 2 dieser Serie erfahren Sie mehr über Best Practices für den Umgang mit dem Lebenszyklus von Merge Requests und die Übertragung von Änderungen in die Produktionsumgebung für Ihre Integrationsressourcen!