





Die Datenmengen nehmen exponentiell zu, und viele Unternehmen beginnen, die Komplexität ihrer wachsenden Datenbewegungen und Datenverwaltungslösungen zu erkennen. Die Daten liegen in verschiedenen Systemen vor, und es ist für viele Unternehmen zu einer großen Herausforderung geworden, einen sinnvollen Nutzen daraus zu ziehen. Außerdem werden die meisten Daten in der Regel in relationalen Systemen wie MySQL, PostgreSQL und Oracle gespeichert, da diese Datenbanken hauptsächlich für OLTP-Zwecke verwendet werden. NoSQL-Systeme wie Cassandra, MongoDB und DynamoDB sind ebenfalls mit einem abstimmbaren Konsistenzmodell auf den Markt gekommen, um einige dieser geschäftskritischen Daten zu speichern. Die Kunden verlagern diese Daten dann in der Regel auf viel größere Systeme wie Teradata und Hadoop (OLAP), die große Datenmengen speichern können, damit sie Analysen, Berichte oder komplexe Abfragen darauf ausführen können. In letzter Zeit ist auch ein Trend zu beobachten, dass einige dieser Daten in die Cloud verlagert werden, insbesondere zu Amazon RedShift oder Snowflake und auch zu HDInsights oder Azure Data Warehouse.
Wenn wir über frühere und aktuelle Trends beim Datenfluss über verschiedene Systeme hinweg sprechen, sieht es folgendermaßen aus:
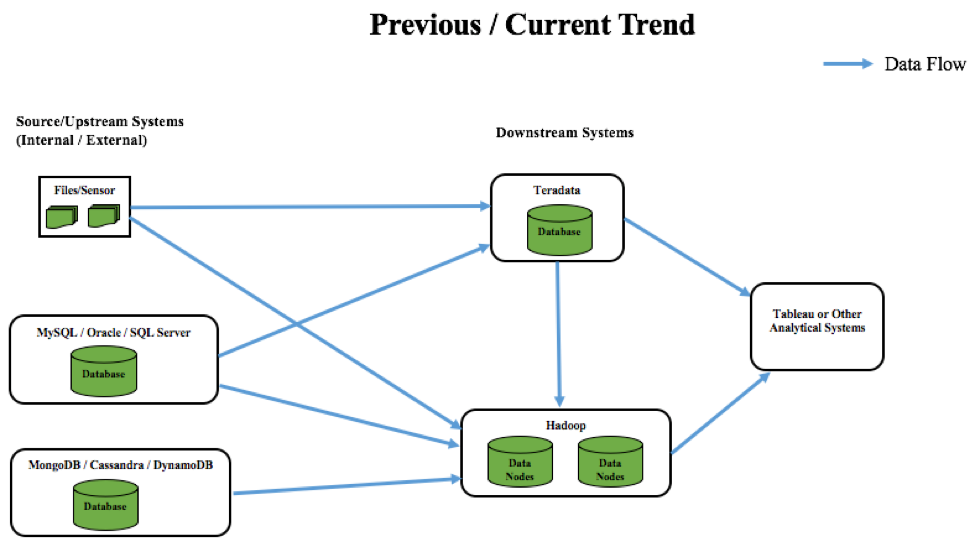 Ein Beispiel: Denken Sie an eine große Lebensmittel- oder Einzelhandelsbranche. Die herkömmliche Methode zur Analyse von Kaufmustern/Trends bestand darin, Daten in Flat Files oder operativen Datenbanken zu speichern und diese später in ein cloudbasiertes Data-Warehouse-System wie Teradata zu verschieben (früherer Trend). Dieser Prozess war eher ein stapelorientierter Vorgang, der keine Erkenntnisse in Echtzeit lieferte. Wenn Kunden beispielsweise Gutscheine für Einkäufe in diesen Branchen erhielten, basierte dies lediglich auf historischen Suchvorgängen und Empfehlungen. Einige dieser Gutscheine mögen für viele Käufer relevant sein, aber meistens waren sie es nicht.
Ein Beispiel: Denken Sie an eine große Lebensmittel- oder Einzelhandelsbranche. Die herkömmliche Methode zur Analyse von Kaufmustern/Trends bestand darin, Daten in Flat Files oder operativen Datenbanken zu speichern und diese später in ein cloudbasiertes Data-Warehouse-System wie Teradata zu verschieben (früherer Trend). Dieser Prozess war eher ein stapelorientierter Vorgang, der keine Erkenntnisse in Echtzeit lieferte. Wenn Kunden beispielsweise Gutscheine für Einkäufe in diesen Branchen erhielten, basierte dies lediglich auf historischen Suchvorgängen und Empfehlungen. Einige dieser Gutscheine mögen für viele Käufer relevant sein, aber meistens waren sie es nicht.
In der heutigen Zeit explodieren die Daten weltweit. Daher nimmt auch die Zahl der Systeme (Sensoren usw.) zu, die diese Daten erfassen, so dass skalierbare NoSQL-Systeme entstanden sind, um diese vielfältigen Datensätze zu speichern. Diese Arten von ständig wachsenden Datensätzen müssen für die Analyse in kostengünstige und skalierbare Systeme übertragen werden. An dieser Stelle hat sich Big Data entwickelt, und die Benutzer haben damit begonnen, Daten auf Hadoop statt auf Teradata zu verschieben, hauptsächlich aus Kostengründen. All diese Systeme werden dann in der Regel mit BI-Tools wie Tableau zur Datenvisualisierung integriert. Auf diese Weise ist die Lebensmittel- und Einzelhandelsbranche in der Lage, Daten schnell an verschiedene Systeme zu senden und in einer schnellen Feedbackschleife zu analysieren. Dies führt zu einem effizienten kundenorientierten Ansatz und zum Drucken von Coupons, die auf einer Kombination von kürzlich/früher gekauften Produkten basieren.
Wenn wir über künftige Trends im Datenfluss über verschiedene Systeme hinweg sprechen, kann man folgendes vorhersehen:
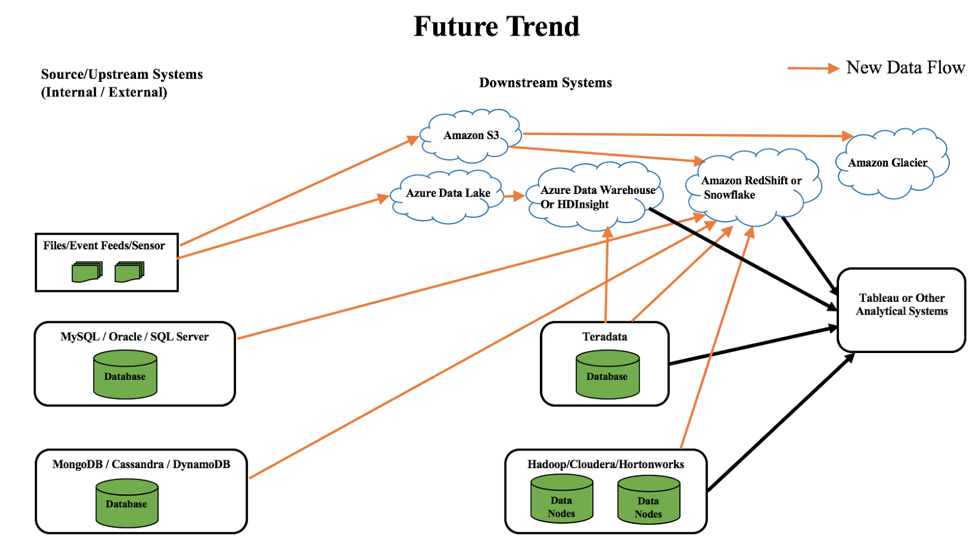
Wie aus dem obigen Diagramm hervorgeht, ist die Cloud nicht mehr wegzudenken und gewinnt mehr denn je an Bedeutung. Die Kunden verlagern ihre Daten allmählich in die Cloud, um die Wartung der Infrastruktur, die Kosten und andere Komplexitäten im Unternehmen zu reduzieren. Einige der zukünftigen Datentrends sind:
- Verschieben von Daten aus operativen und NoSQL-Systemen nach Redshift oder Snowflake
- Verschieben von Daten von Teradata zu Hadoop in der Cloud wie HDInsights oder Azure Data Warehouse
- Verschieben von Daten aus Sensoren/Ereignis-Feeds zu Azure Data Lake oder Amazon S3. Später könnte Amazon Glacier verwendet werden, um kalte/häufig verwendete Daten zu speichern.
Alles in allem ist dasVerschieben von Daten über diese Systeme hinweg entscheidend für die Erzielung eines zentralen geschäftlichen Nutzens geworden. Dies erfordert zusätzlichen ETL-Entwicklungsaufwand, wenn es manuell durchgeführt wird. Snaplogic macht es Anwendern jedoch sehr einfach, Daten in verschiedene Systeme zu verschieben - sowohl für Anwendungen als auch für Datenbanken/Data Warehouses (vor Ort oder in der Cloud), indem Pipelines über vorgefertigte Konnektoren, sogenannte Snaps, erstellt werden - ohne jeglichen Programmieraufwand. Mit einem einfachen Drag-and-Drop-Mechanismus, der von der skalierbaren Snaplogic-Plattform bereitgestellt wird, können Kunden problemlos Pipelines mit relevanten Snaps erstellen und Daten aus verschiedenen Systemen verschieben, so dass sie schnell einen geschäftlichen Nutzen daraus ziehen können. Diese Snaps führen auch eine Datentransformation, -bereinigung oder -aufbereitung durch, damit die nachgelagerten Systeme die gewünschten Daten erhalten, die die Geschäftsergebnisse unterstützen können.
Im Folgenden sind einige SnapLogic-Pipelines für die aktuellen und zukünftigen Trends aufgeführt:

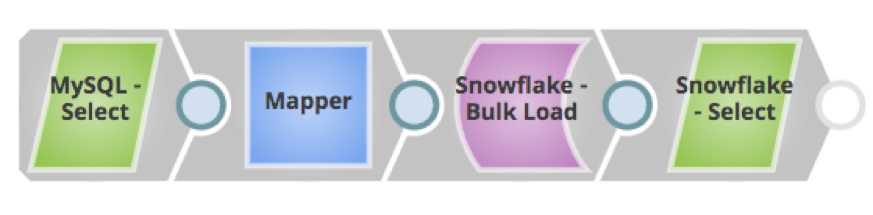 Zusammenfassend lässt sich sagen, dass sich die Cloud durchsetzen wird, da immer mehr Unternehmen ihre Daten in die Cloud verlagern, und zwar aufgrund der hier erwähnten Vorteile und Flexibilität. Und die Cloud-Plattform von SnapLogic steht an vorderster Front, um dies zu ermöglichen.
Zusammenfassend lässt sich sagen, dass sich die Cloud durchsetzen wird, da immer mehr Unternehmen ihre Daten in die Cloud verlagern, und zwar aufgrund der hier erwähnten Vorteile und Flexibilität. Und die Cloud-Plattform von SnapLogic steht an vorderster Front, um dies zu ermöglichen.
