





Ausfallsicherungen können für Unternehmen ein Alptraum sein, wenn sie nicht richtig verwaltet werden. Failover ist ein Backup-Betriebsmodus, bei dem die Funktionen einer Systemkomponente, z. B. eines Prozessors, Servers, Netzwerks oder einer Datenbank, von sekundären Systemkomponenten übernommen werden, wenn die primäre Komponente entweder durch einen Ausfall oder eine geplante Ausfallzeit nicht mehr verfügbar ist. Das Failover-Verfahren ist konzeptionell einfach - es beinhaltet die automatische Verlagerung von Aufgaben auf eine Standby-Systemkomponente, so dass das Verfahren für den Endbenutzer so nahtlos wie möglich ist. Failover ist ein integraler Bestandteil geschäftskritischer Systeme, die ständig verfügbar sein müssen, und wird eingesetzt, um die Fehlertoleranz von Systemen zu erhöhen. Wenn die Ausfallsicherung nicht richtig konzipiert ist, werden Geschäftsprozesse unterbrochen, was zu verfehlten Umsatzzielen und unzufriedenen Kunden führt.
Failover immer im Blick haben
Für Systementwickler und diejenigen, die die verschiedenen Komponenten der Netzwerktopologie eines Systems verwalten, ist die Ausfallsicherheit eine zentrale Überlegung, die an erster Stelle stehen sollte und nicht erst im Nachhinein. Die Geschäftssysteme müssen nicht nur die angegebene Betriebszeit unterstützen, sondern auch die zugrundeliegende Unterstützung der Geschäftssysteme (Infrastruktur, Integration usw.) muss zusammenarbeiten, um die vom Unternehmen definierten Service Level Agreements (SLA) mit den notwendigen Beteiligten zu erreichen.
Es gibt zwar keine Patentlösung für Failover, aber SnapLogic bietet mehrere Möglichkeiten, Failover für ein bestimmtes System oder eine Anwendung zu ermöglichen. Heute werden in SnapLogic Standard Ausführungen ein Failover auf andere Knoten im Cluster, wenn ein Knoten ausfällt. Unter SnapLogic Ultra Pipelines, wo mehrere Thread-Instanzen (Parallelisierung) den Durchsatz erhöhen, wird das Thread-Failover nativ innerhalb der Ultra-Ausführungen gehandhabt. Die oben erwähnte Hochverfügbarkeitsunterstützung (HA) findet innerhalb eines bestimmten Snaplex statt.
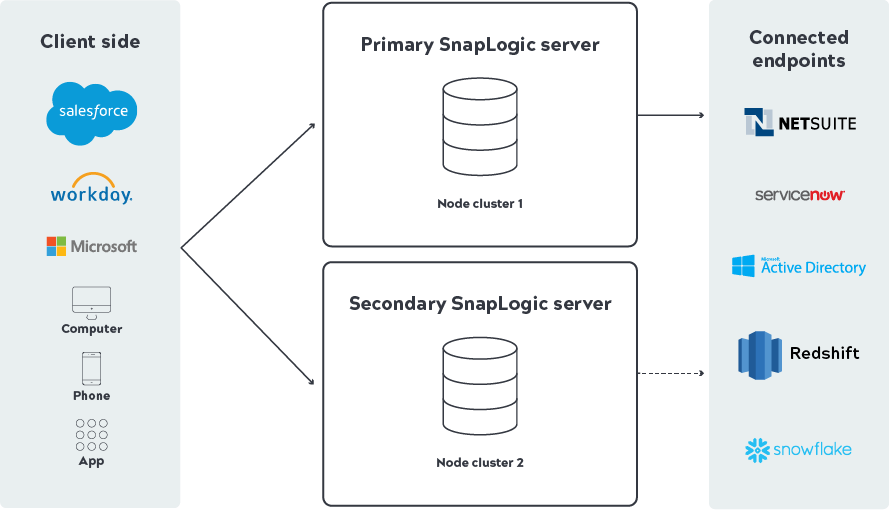
Für eine rechenzentrumsübergreifende Failover-Unterstützung bei einer vollständigen Daten-HA-Unterstützung verfügt SnapLogic über die folgenden Funktionen:
Mit HA-Ultra-Tasks unterstützen wir die Verteilung von Tasks auf mehrere Snaplexes über Aliasing (siehe Ultra-Pipeline-Aufgaben Dokumentation) für die verschiedenen heute verfügbaren Lastausgleichstechnologien und -methoden.
HA für reguläre Tasks wird seit dem Release November 2018 (4.15) unterstützt und ermöglicht Tasks, die per Override URL aufgerufen werden (siehe So führen Sie eine Pipeline von einer URL aus (Triggered Task) Dokumentation .) nahtlos auf jedem Snaplex ausgeführt werden, für den sie Berechtigungen haben.
Systementwickler und ähnliche Beteiligte haben nun mehrere Möglichkeiten, HA-Fälle innerhalb eines bestimmten Snaplex und zwischen verschiedenen Snaplexes in verschiedenen Rechenzentren zu unterstützen.
Weitere Informationen darüber, wie Sie von HA profitieren können, finden Sie unter SnapLogic-Dokumentation oder sehen Sie sich das Webinar zur Version 4.15 vom November 2018.




