





Beim letzten Mal haben wir darüber gesprochen, dass es wichtiger ist, herauszufinden, was wir mit maschinellem Lernen erreichen wollen, als wie wir es erreichen. Bevor wir uns also mit dem Aufbau einer Pipeline für maschinelles Lernen in der SnapLogic Elastic Integration Platform befassen, sollten wir darüber sprechen, was wir tun.
Eine Anwendung, die in einer Vielzahl von Branchen und Anwendungsfällen nützlich ist, ist die Anomalieerkennung. Wie der Name schon sagt, dient die Anomalieerkennung dazu, Daten zu finden, die anomal oder abnormal sind. Dies könnte genutzt werden, um Beweise für böswillige Hackerangriffe zu finden, fehlerhafte Software zu identifizieren, Qualitätskontrollen durchzuführen, Daten von IoT-Sensoren zu bereinigen usw. Was auch immer die Motivation ist, der erste Schritt ist das Training des Systems. (Wenn Sie mit der Leistung des Detektors zufrieden sind (indem Sie ihn an Daten testen, die er noch nicht "gesehen" hat), setzen Sie das System ein, um Daten zu prüfen - wahrscheinlich Streaming-Daten.
Systeme zur Erkennung von Anomalien wurden lange Zeit ohne maschinelles Lernen implementiert, im Allgemeinen mit Hilfe von Faustregeln. Widgets, die außerhalb einer bestimmten Toleranz liegen, werden abgelehnt; ein Server, dessen CPU länger als eine Minute zu 95 % ausgelastet ist, wird auf einen möglichen Runaway-Prozess untersucht; ein Thermostat, das Temperaturen außerhalb von 0 bis 120 Grad Fahrenheit meldet, wird auf eine Fehlfunktion überprüft. Das maschinelle Lernen bietet die Möglichkeit, diese Regeln automatisch zu erstellen, mit klarer definierten Kompromissen und mit der Möglichkeit, das Modell regelmäßig neu zu trainieren, wenn wir Grund zu der Annahme haben, dass sich der Prozess im Laufe der Zeit ändern wird.
Werfen wir einen Blick auf ein sehr einfaches Signal. Unten sehen wir ein Signal, das etwas verrauscht ist, aber es ist ziemlich klar, dass es ungefähr 1 sein sollte, mit einem Sechs-Sigma-Bereich von ungefähr zwischen 0,4 und 1,6. Jetzt trainieren wir einen Anomaliedetektor mit einer Einklassen-Support-Vector-Maschine (SVM) darauf. Die Einzelheiten der Funktionsweise einer SVM würden den Rahmen dieses Beitrags sprengen, aber wenn Sie daran interessiert sind, finden Sie bei O'Reilly Media einen hervorragenden interaktiven Beitrag von Jake VanderPlas zu diesem Themasowie in der scikit-learn-Dokumentation. Für unsere Zwecke wird die SVM trainiert, indem wir ihr normale Daten geben. Wir müssen ihr keine Beispiele mit anomalen Daten geben. Nachdem wir die SVM trainiert haben, geben wir ihr ein paar schmutzigere Daten und sehen, wie sie abschneidet:
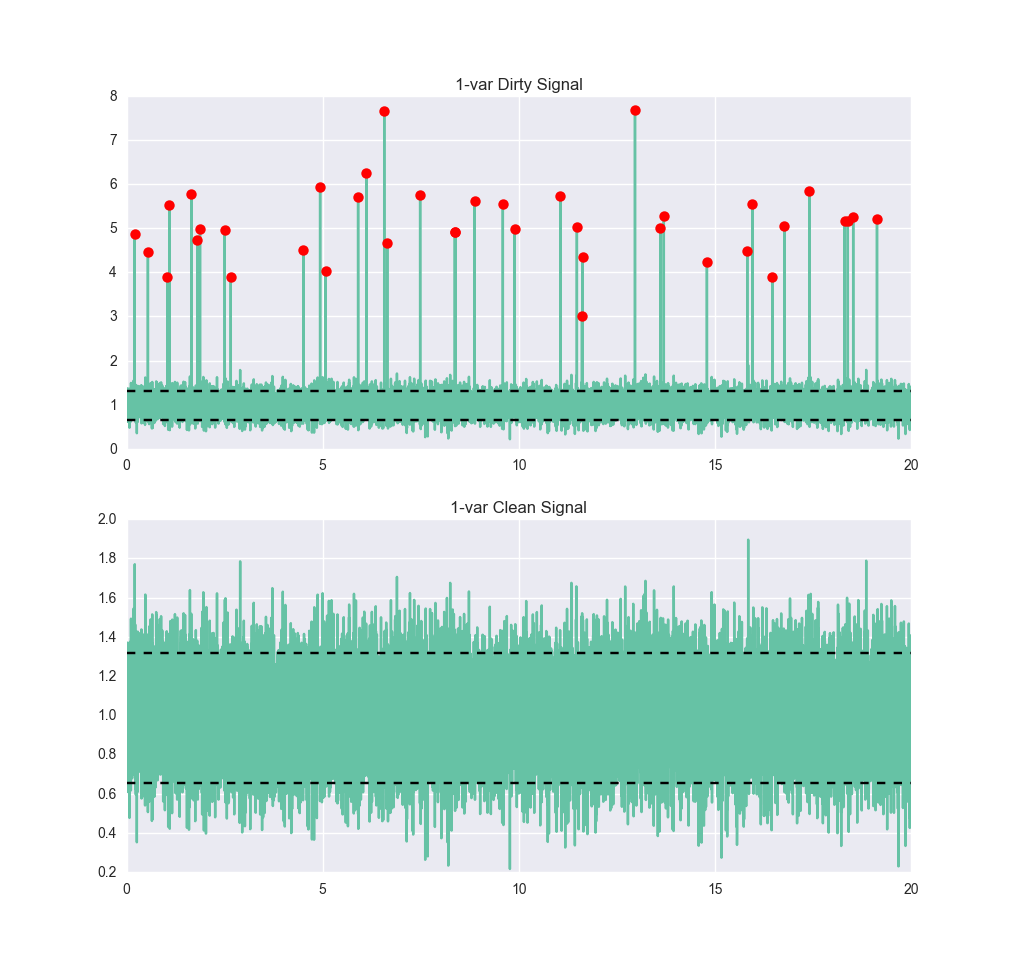
true_pos: 17964 wahr_neg: 39 false_pos: 1997 false_neg: 0 Genauigkeit: 0.90015 Genauigkeit: 0,89995 Rückruf: 1.0 F1: 0.94734
Die Grenzen zwischen Anomalie und Nicht-Anomalie sind in diesem Diagramm als schwarze horizontale Linien eingezeichnet. Für einen handelsüblichen Algorithmus mit geringen Anpassungen ist das nicht schlecht. Wir erfassen alle Anomalien, was gut ist, aber wir stufen auch etwa 10 % der normalen Punkte als Anomalien ein. Hätten wir zwei Klassen verwendet (d. h. mit der Menge der Anomalien trainiert, vorausgesetzt, wir konnten sie identifizieren), hätten wir wahrscheinlich eine viel bessere Leistung erzielt - vor allem viel weniger falsch-positive Ergebnisse.
Anomalie-Detektoren kommen dann richtig zur Geltung, wenn die Anomalie nicht nur eine Variable betrifft, die sich schlecht verhält. Stellen Sie sich zum Beispiel vor, Sie überwachen die eingehenden Verbindungen zu einem Webserver und seine CPU-Auslastung. Im Allgemeinen erwarten wir, dass diese beiden Größen in einem linearen Verhältnis zueinander stehen. Wenn die CPU-Auslastung hoch ist, während die Zahl der Verbindungen niedrig ist, würden wir uns Sorgen über einen fehlerhaften Prozess oder eine mögliche Sicherheitsverletzung machen. Wenn die Verbindungen hoch, die CPU-Auslastung aber niedrig ist, liegt es vielleicht daran, dass unsere Hauptanwendung abgestürzt ist und den Benutzern nur Fehlerseiten angezeigt werden. In jedem Fall reicht es aus, entweder die CPU-Auslastung oder die eingehenden Verbindungen zu kennen, um eine Anomalie zu charakterisieren; wir müssen beide untersuchen, wie unten dargestellt*:
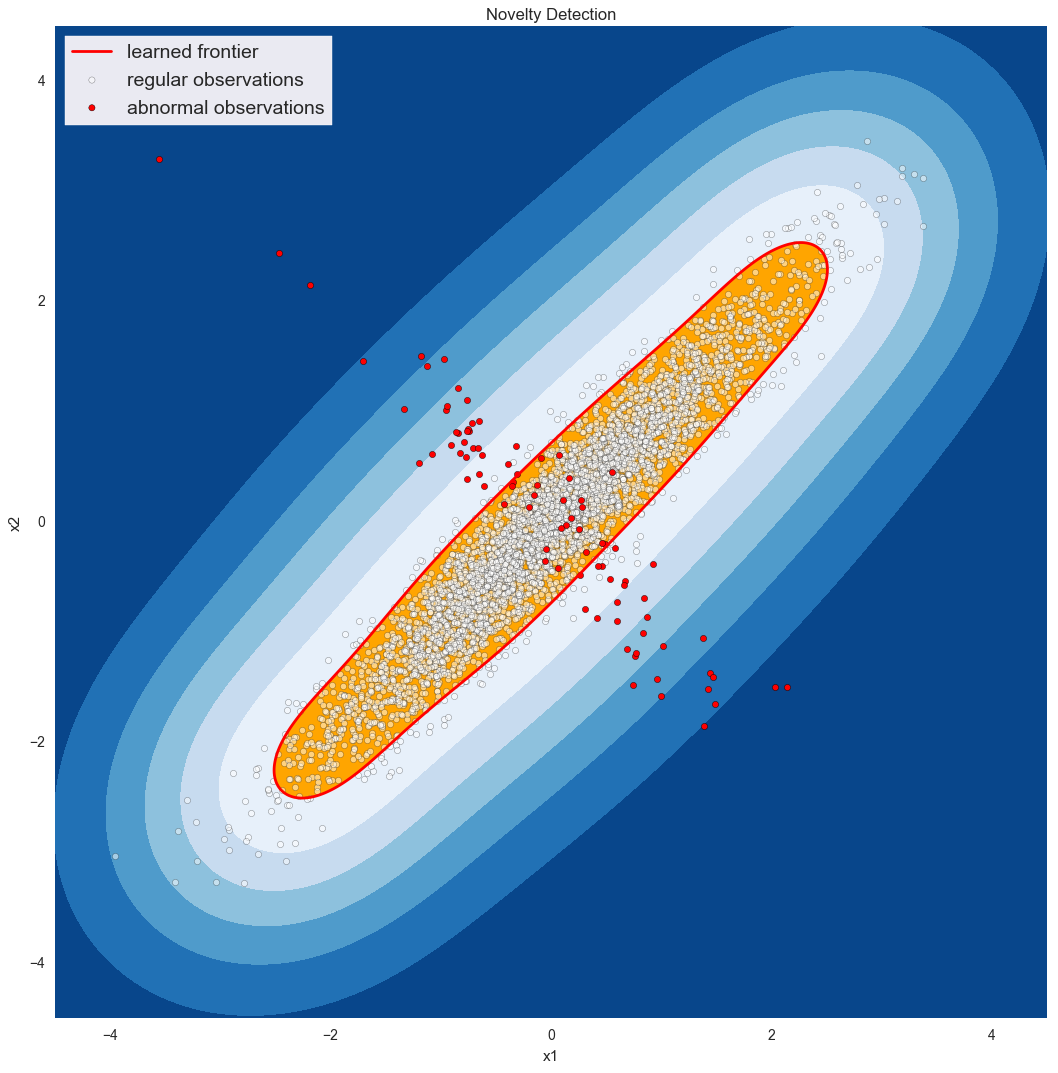
Zugdaten, (sauber): Test-Datensatz: true_pos: 18999 true_pos: 4668 wahr_neg: 0 wahr_neg: 64 false_pos: 0 false_pos: 23 false_neg: 1001 false_neg: 245 Genauigkeit: 0.94995 Genauigkeit: 0.9464 Genauigkeit: 1,0 Genauigkeit: 0,99509 Rückruf: 0.94995 recall: 0.95013 F1: 0,97433 F1: 0,97209
In den nächsten beiden Teilen dieser Serie werden wir zunächst die Pipeline für die Erkennung von Anomalien auf der Grundlage eines einfachen Anomaliedetektors mit einer Variablen aufbauen. Für den ersten Teil gehen wir davon aus, dass wir einen Anomalieerkennungs-Snap haben, aber wir gehen nicht näher darauf ein. Im letzten Teil werden wir auf diesen Blackbox-Snap zurückkommen und zeigen, wie wir schnell einen elastisch skalierenden Anomaliedetektor auf Azure ML einrichten können, der uns als einfacher REST-Dienst zur Verfügung steht. Falls Sie neugierig auf die in diesem Beitrag erstellten Graphen sind, haben wir den Python-Code in einem GitHub-Repository gepostet, damit Sie ihn sich ansehen können. Es gibt zwei Skripte und ein IPython/Jupyter-Notebook. Beide sind in grober Form (Pull Requests willkommen!), aber ein guter Ausgangspunkt für weitere Untersuchungen.
* Man könnte auch anmerken, dass man sich für das Verhältnis zwischen den beiden Variablen - nennen wir sie x1 und x2 - interessiert und daher ein SVM mit einer einzigen Variable für x3 erstellen könnte, indem man x3 = x1 / x2 setzt. Das ist richtig, aber beachten Sie, dass (a) Sie gerade manuell etwas Wissen über den Prozess in das System eingebracht haben (die lineare Beziehung) und (b) wenn x2 gegen 0 geht, geht x3 gegen unendlich, was immer problematisch ist.





