





Zuvor auf Medium veröffentlicht
Ich habe das Glück, mit einer starken Gruppe von Ingenieuren, Architekten und Analysten bei einem Unternehmen namens CBG zusammenzuarbeiten. Unsere Vision bei CBG ist es, mit unserem anerkannten klinischen, betrieblichen und digitalen Fachwissen und unseren Lösungen eine Vielzahl von Einrichtungen im Gesundheitswesen aufzubauen und zu unterstützen, und das alles mit dem Ziel, bewährte Ergebnisse zu beschleunigen. Unsere Mitarbeiter, unsere Denkweise und unsere Unternehmenskultur machen dies in hohem Maße möglich. Ein solches Unternehmen im Gesundheitswesen, das wir aufgebaut haben, heißt RealRx, und es sind weitere in Planung.
Unsere Teams haben im vergangenen Jahr sowohl auf sozialer als auch auf beruflicher Ebene so viel Widerstandskraft bewiesen. Wie die meisten Technologie-Teams lösen sie jeden Tag schwierige Probleme, passen sich schnell an neue Entwicklungen in unserem Unternehmen an und bemühen sich, unsere technologische Mission zu erfüllen. Ein Teil dieses Auftrags besteht darin, Verschwendung und Wartezeiten zu beseitigen, um den Durchsatz des Teams zu maximieren. Wir haben herausgefunden, dass eine Möglichkeit, Verschwendung und Wartezeiten zu vermeiden, darin besteht, alles zu automatisieren und CI/CD für ALLES zu nutzen, was wir entwickeln, anfassen und unterstützen, einschließlich Low-Code/No-Code-Plattformen, auf denen wir entwickeln.
Ich möchte Ihnen einen Ansatz vorstellen, den wir mit der SnapLogic Intelligent Integration Platform (IIP) verfolgen, um die CI/CD-Automatisierung in unsere täglichen SDLC-Praktiken einzubetten, die nachweislich zu schnelleren Geschäftsergebnissen für unsere strategischen Partner, Kunden und Mitglieder führen.
Was ist CI/CD?
Moderne Entwicklungsteams setzen in der Regel auf diese vier Säulen: kontinuierliche Integration, kontinuierliche Bereitstellung, Infrastruktur als Code und ein Sicherheitsdenken, das die Sicherheit weit nach links in den SDLC eines Unternehmens verlagert. Das Problem, über das ich gestolpert bin, ist, dass viele Teams immer noch nicht wirklich verstehen, was diese Schlagworte bedeuten, warum sie für ein Team wichtig sind und wann sie eigentlich keine Rolle spielen (wenig Wert bieten).
Ich möchte mich auf die erste der oben genannten Säulen konzentrieren. In der Vergangenheit arbeiteten die Entwickler in einem Team möglicherweise über einen längeren Zeitraum isoliert und führten ihre Änderungen erst dann in den Master/Hauptzweig/Stamm ein, wenn ihre Arbeit abgeschlossen war. Diese "Batch-Modus"-Praxis machte das Zusammenführen von Codeänderungen schwierig und zeitaufwändig und führte dazu, dass sich Fehler über lange Zeit ansammelten, ohne dass sie korrigiert wurden. Diese Faktoren erschwerten die schnelle und risikofreie Bereitstellung von Aktualisierungen für die Kunden.
Um diese Faktoren zu beheben, wurde die kontinuierliche Integration eingeführt. Kontinuierliche Integration ist eine Praxis der Softwareentwicklung, bei der Entwickler ihre Codeänderungen regelmäßig und häufig in ein zentrales Repository einbringen, woraufhin automatisierte Builds und Tests durchgeführt werden. Kontinuierliche Integration (im Folgenden CI) bezieht sich meist auf die Build- oder Integrationsphase des Software-Release-Prozesses, die sowohl eine Automatisierungskomponente (z. B. einen CI- oder Build-Dienst) als auch eine kulturelle Komponente (z. B. das Erlernen häufiger Integrationen) umfasst.
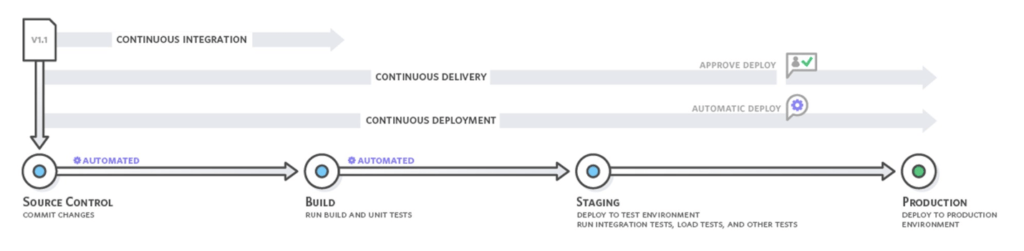
Neben der KI wurden zwei weitere Praktiken für Softwareteams eingeführt: die kontinuierliche Bereitstellung und das kontinuierliche Deployment. Interessanterweise setzen viele Entwicklungsteams das eine oder das andere mit CD gleich, aber meistens ist die kontinuierliche Bereitstellung das, was wirklich zählt.
Bei der kontinuierlichen Bereitstellung werden Codeänderungen automatisch erstellt, getestet und für die Produktionsfreigabe vorbereitet, gelangen aber nicht tatsächlich in die Produktion. Continuous Delivery baut auf Continuous Integration auf, indem alle Codeänderungen nach der Build-Phase in einer Testumgebung bereitgestellt werden. Und Continuous Deployment erzielt den Touchdown, bringt uns zu done^2 und treibt es auf die Spitze, indem es das Deployment aller durch CI-Verfahren gesammelten Änderungen automatisiert. Ziemlich einfach.
Wie gehen wir an CI/CD heran?
Das ist das Konzept von CI/CD in einer Nussschale, und es ist reine Theorie. Es kann eine Herausforderung sein, die Theorie zu verdauen und sie in echten Treibstoff umzuwandeln, der ein Team dazu antreibt, neue Gewohnheiten und Praktiken in einer schnelllebigen Unternehmens- oder Startup-Umgebung gleichermaßen anzupassen.
In der realen Welt bei CBG kann man die CI/CD-Praktiken in der täglichen Arbeit unseres Teams auf hohem Niveau beobachten:
- Die Entwickler nehmen häufig Übertragungen an ein gemeinsames Repository vor, wobei Git als Versionskontrollsystem verwendet wird, manchmal mehrmals am Tag mit einer Methodik, die GitFlow ähnelt.
- Vor jeder Übergabe führen die Entwickler lokale Unit-Tests für ihren Code durch, bevor sie ihn integrieren
- Außerdem führen sie über Build-Skripte Linting, Sicherheitsscans und Rechtschreibprüfungen durch.
- Jede Revision, die übertragen wird, löst auch einen automatisierten Build- und Testlauf aus, um eventuelle Fehler oder Probleme sofort automatisch zu erkennen.
- Ereignisse werden an MS Teams und AWS CloudWatch weitergeleitet, damit sie für die Teammitglieder sichtbar sind, egal ob gut oder schlecht, so dass sie "groß und laut" sind.
- Eingehende Webhook-Konnektoren ermöglichen es externen Diensten, unsere CI/CD-Kanäle über benutzerdefinierte Medien zu benachrichtigen
- GitHub Actions-Jobs und -Schritte steuern die Automatisierung dieser Aktivitäten und übermitteln benutzerdefinierte Metadaten mit Job-/Schritt-Status
- Alle CI/CD-Aktivitäten im Zusammenhang mit Pull-Requests, Pushes und Problemen werden an ChatOps (MS Teams) und die zentrale Protokollierung (AWS CloudWatch) übertragen.
- Jeder Merge/Push zu unseren Hauptzweigen löst automatisch eine neue Version und eine neue Bereitstellung für die Produktion aus, die bereits mehrfach getestet wurde, wodurch das Risiko von Ausfallzeiten minimiert und die Anzahl der Funktionen, die unsere Teams in jeder Iteration bereitstellen können, maximiert wird.
CI hilft unseren Teams, produktiver zu arbeiten, indem es die Entwickler von manuellen Aufgaben befreit und Verhaltensweisen fördert, die dazu beitragen, die Anzahl der Fehler und Bugs, die an die Kunden weitergegeben werden, zu reduzieren. Durch häufigere Tests können die Teams Bugs früher entdecken und beheben, bevor sie sich später zu größeren Problemen auswachsen. Und schließlich hilft es den Teams, ihren Kunden schneller und häufiger Updates zu liefern.
Wo kommt SnapLogic ins Spiel?
Eine weitere Technologie-Mission, die wir bei CBG leben, ist die pragmatische Automatisierung, RPA, Bots, API-Integrationen und Low-Code/No-Code-Lösungen, um robuste, einfach zu verwendende digitale Lösungen zu entwickeln. Eine dieser Low-Code/No-Code-Plattformen, die wir für unsere ETL/ELT, Daten- und API-Integrationen und Automatisierung verwenden, heißt SnapLogic Intelligent Integration Platform.
SnapLogic leistet hervorragende Arbeit bei der Handhabung verschiedener Arten von Daten und API-Integrationen für alle Arten von Unternehmen. Parallel dazu nutzen zukunftsorientierte Unternehmen wie CBG DevOps/NoOps-Methoden für ihre eigenen Daten und Application Integration Workflows und Initiativen. Ein Problem, auf das ich schon früher gestoßen bin, ist, dass sich Dienste wie SnapLogic (auch bekannt als Low-Code/No-Code) nicht immer gut mit DevOps-Praktiken wie CI/CD und Infrastructure-as-Code integrieren lassen. SnapLogic ist eine angenehme Ausnahme von dieser Aussage, und ich möchte Ihnen zeigen, warum und wie.
SnapLogic bietet Unternehmen mehrere Methoden zur Anwendung von CI/CD-Verfahren in ihrem SDLC, einschließlich einiger nativer Migrationsmethoden, aber keine hat sich für meine Teams als leistungsfähiger und flexibler erwiesen als der SnapLogic Metadata Snap. Der CI/CD-Ansatz von CBG für SnapLogic nutzt den SnapLogic Metadata Snap in Pipelines, die für CI/CD-Aktivitäten bestimmt sind. Damit können Entwickler Pipelines erstellen und anpassen, um eine, einige oder alle Metadatenkategorien für ihre CI/CD-Anforderungen zu nutzen.
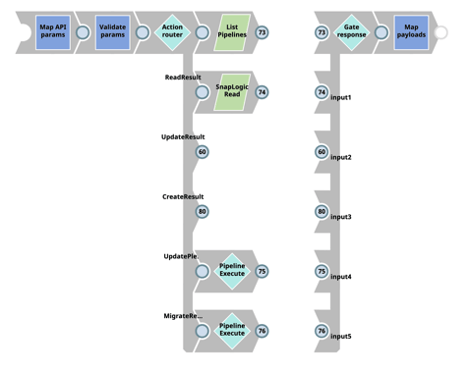
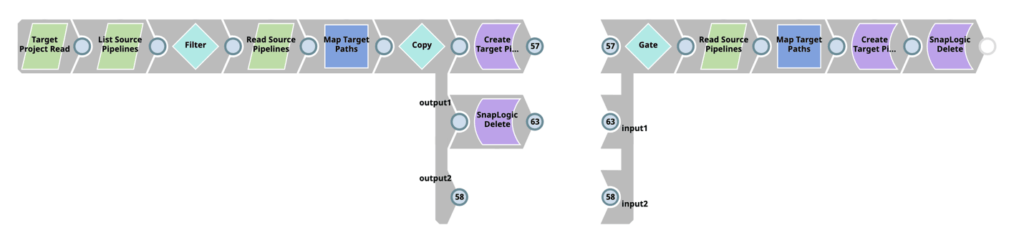
Mit SnapLogic-Pipelines können unsere Teams jede Pipeline-Komponente nutzen, um die Metadaten zu ändern und umzuwandeln, damit sie den Geschäftsanforderungen entsprechen. Der Hauptvorteil dieses Ansatzes und der Grund, warum unsere Teams bei CBG ihn für die überlegene Methode halten, ist, dass wir die volle Kontrolle darüber haben, wie und was für unseren spezifischen CI/CD-Prozess getan wird, einschließlich der Bereitstellung dieser Pipeline-Artefakte an verschiedene Knoten und Projekte.
Unsere Entwicklungsteams profitieren außerdem von bestehenden Versionskontrollsystemen (wie GitHub) und bestehenden Build-/Deploy-Automatisierungssystemen (wie GitHub Actions), um mit den SnapLogic-Komponenten zu arbeiten. Unsere Teams haben festgestellt, dass unsere Versionskontrollsysteme und Build-/Deploy-Automatisierungssysteme sehr gut zusammenspielen und bei der Ausführung von SnapLogic-Remote-Pipelines von GitHub über die bereitgestellte SnapLogic-API, die mit unseren ausgelösten Aufgaben verknüpft ist, nahezu nahtlos funktionieren. Wir haben GitHub Actions-Workflows und SnapLogic-APIs erfolgreich miteinander verbunden, um unseren Low-Code/No-Code-Implementierungsprozess über die gesamte Entwicklungs-, Test- und Produktionsphase zu automatisieren.
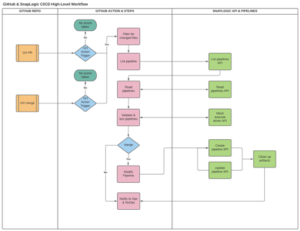
Dieser High-Level-Ansatz gibt unseren Teams die Möglichkeit, die Inhalte in GitHub zu verpacken und dann Build/Deploy-Automatisierungsskripte zu verwenden, um bestimmte, geänderte Versionen auf der Grundlage einer Pull-Anfrage oder eines Merge-Requests zurück an SnapLogic zu senden, um sie zu entpacken und eine Downstream-Umgebung von der Entwicklung zu aktualisieren.
Vorbei sind die Zeiten, in denen wir Deployments manuell über die SnapLogic-Benutzeroberfläche durchführen mussten. Alle Änderungen werden automatisch auf der Grundlage von Ereignissen in der Versionskontrolle, GitHub-Aktionen und den Arten von Abläufen, die diese Ereignisse auslösen, auf den angegebenen Knoten und das Projekt bereitgestellt.

Wenn wir CI/CD auf diese Weise durchführen, können unsere Teams einen natürlicheren Entwicklungsfluss annehmen, der dem anderer Codes und Microservices ähnelt, an denen sie parallel arbeiten, und zwar während derselben oder künftiger Iterationen. Sie müssen sich nicht mehr an einen anderen CI/CD-Fluss erinnern, je nachdem, welches Projekt sie gerade in Angriff nehmen oder ob es sich um Low-Code/No-Code handelt oder nicht. Auch für Auditoren sieht es sehr sauber und automatisiert aus, und wir sind in der Lage, die Berechtigungen auf granularer Ebene in den SnapLogic-Knoten, Umgebungen und Projekten einzuschränken.
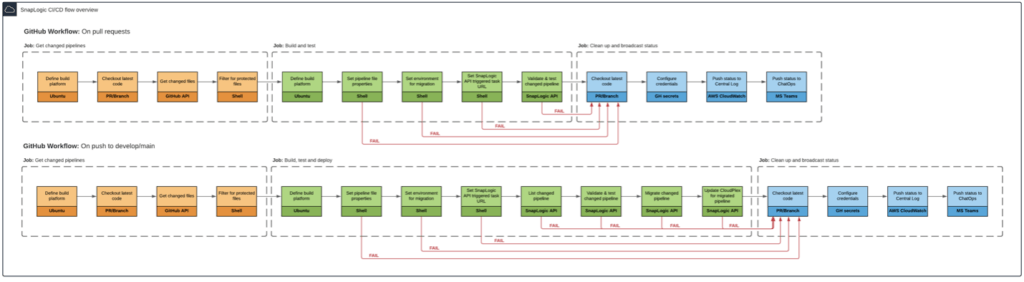
Derzeit decken unsere CI/CD-Abläufe zwei Szenarien ab: einen für Pull-Requests in GitHub, der dazu dient, SnapLogic-Pipelines zu validieren und zu testen, bevor sie in Entwicklungs- oder Hauptzweige integriert werden, und einen weiteren für den Fall, dass in GitHub ein Push/Merge-Ereignis für Entwicklungs- oder Hauptzweige auftritt. Der letztgenannte Fluss dient nicht nur der Validierung und dem Testen von Pipelines, sondern auch der automatischen Bereitstellung und Aktualisierung von Metadaten für neu geänderte Pipelines, die für die kontinuierliche Bereitstellung verpackt werden.
TL;DR
Zusammenfassend lässt sich sagen, dass es inspirierend ist zu sehen, wie unsere Technologie-Teams nie zufrieden sind, bis sie einen manuellen Prozess automatisieren können, einschließlich Low-Code/No-Code-Services wie SnapLogic. Noch erfrischender ist es, wenn Plattformen wie SnapLogic mehrere Optionen für die Einhaltung von CI/CD bieten. Unsere Teams lieben den aktuellen Fluss, unsere Auditoren lieben die Automatisierung und das Fehlen menschlicher Fehler, und unsere Geschäftspartner lieben das minimale Risiko bei der Bereitstellung neuer Funktionen für die Produktion.




