In einem früheren Blogbeitraghabe ich die wichtigsten Trends im Bereich der Datenintegration und die Umstellung der Kunden von On-Premise auf Cloud erörtert. Ich möchte mich auf einen Trend konzentrieren, der die Verlagerung von Daten von lokalen oder Cloud-Datenanalyseplattformen zu einer Data Lake-Technologie wie Azure Data Lake beinhaltet.
Was ist ein Data Lake?
Data Lake ist ein Begriff, der für die Speicherung großer Datenmengen in ihrer rohen, nativen Form verwendet wird, einschließlich strukturierter und unstrukturierter Daten an einem Ort. Diese Daten können aus verschiedenen Quellen stammen, und der Data Lake kann als eine einzige Quelle der Wahrheit für jede Organisation dienen. Aus architektonischer Sicht werden die Daten zunächst im Datensumpf/bei der Datenerfassung gespeichert, dann im Rahmen der Datentransformation bereinigt/transformiert und später veröffentlicht, um Geschäftseinblicke zu gewinnen.
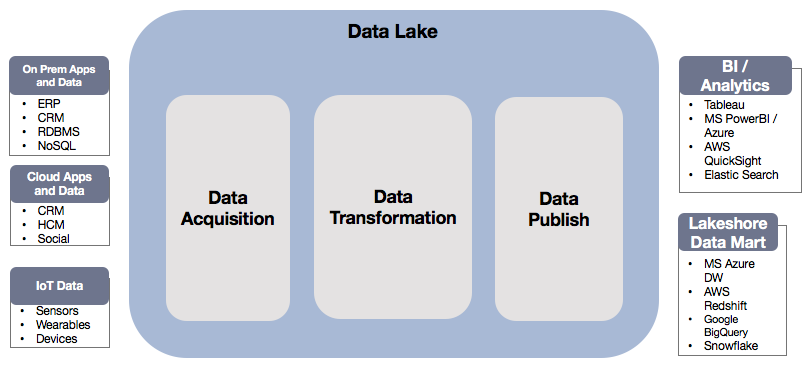
Wie im obigen Diagramm zu sehen ist, haben Unternehmen mehrere Systeme wie ERP, CRM, RDBMS, NoSQL, IoT-Sensoren usw. Die disparaten Daten, die in verschiedenen Systemen gespeichert sind, machen es schwierig, Daten daraus zu ziehen. Ein Data Lake bringt alle Daten unter ein Dach (Datenerfassung) und nutzt einen der folgenden Dienste:
- Azure Blob
- Azure Data Lake Speicher
- Amazon S3
- HDFS
- Andere
Die in einem dieser Dienste gespeicherten Daten können dann auf folgende Weise umgewandelt werden:
- Aggregat
- Sortieren
- Beitreten
- Zusammenführen
- Andere
Die umgewandelten Daten werden dann in den Bereich Datenveröffentlichung/Datenzugriff verschoben (könnte derselbe sein wie bei den Datenerfassungsdiensten), wo die Benutzer die folgenden Werkzeuge zur Abfrage der Daten verwenden können:
- Microsofts U-SQL
- Amazonas-Athena
- Bienenstock
- Presto
- Andere usw.
Unterm Strich kann ein Data Lake als Plattform für die Durchführung von Analysen dienen, um eine bessere Kundenerfahrung, Empfehlungen und mehr zu bieten.
Wo werden die Daten in Azure gespeichert?
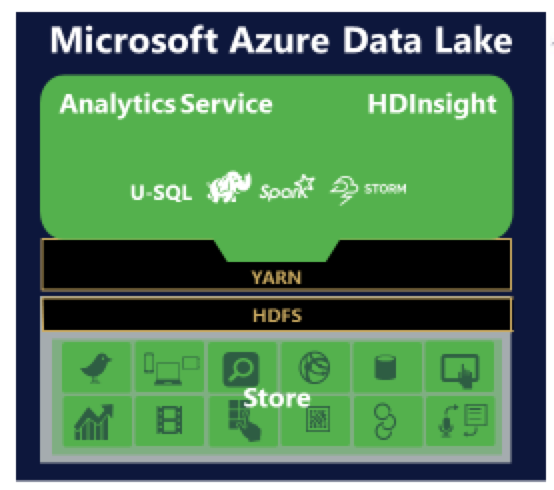
Azure Data Lake ist ein solcher Data Lake von Microsoft und das Repository, das zum Speichern aller Daten verwendet wird, ist der Azure Data Lake Store. Benutzer können Analytics Service, HDInsight oder U-SQL - eine Big-Data-Abfragesprache - auf diesem Datenspeicher ausführen, um bessere Geschäftseinblicke zu erhalten.
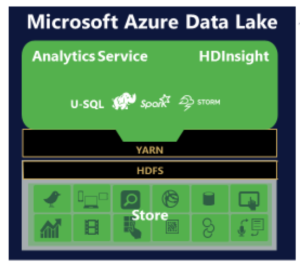
Der Azure Data Lake Store (ADLS) kann beliebige Daten in ihrem nativen Format speichern. Eines der Ziele dieses Datenspeichers ist es, Daten aus unterschiedlichen Quellen zusammenzuführen. Die Snaplogic Enterprise Integration Cloud mit ihren vorgefertigten Konnektoren namens Snaps hilft dabei, Daten aus verschiedenen Systemen schnell in den Datenspeicher zu übertragen.
ADLS bietet eine komplexe API, die Anwendungen nutzen, um Daten in ADLS zu speichern. Snaplogic hat all diese Komplexitäten über Snaps abstrahiert, so dass die Benutzer wissen, wo die Daten in Azure gespeichert sind, und sie können nun ganz einfach Daten von verschiedenen Systemen nach ADLS verschieben, ohne etwas über die Komplexität dieser APIs wissen zu müssen.
Anwendungsfall
Ein Unternehmen muss Inhalte verfolgen und analysieren, um seinen Kunden Produkte oder Dienstleistungen besser empfehlen zu können. Seine Daten - aus verschiedenen Quellen wie Oracle, Dateien, Twitter usw. - müssen in einem zentralen Repository wie ADLS gespeichert werden, damit die Geschäftsanwender darauf Analysen durchführen können, um das Kaufverhalten der Kunden, ihre Interessen und die gekauften Produkte zu messen.
Hier finden Sie ein Beispiel für eine Pipeline, die diesen Anwendungsfall mit Snaps lösen kann:
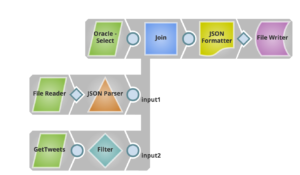
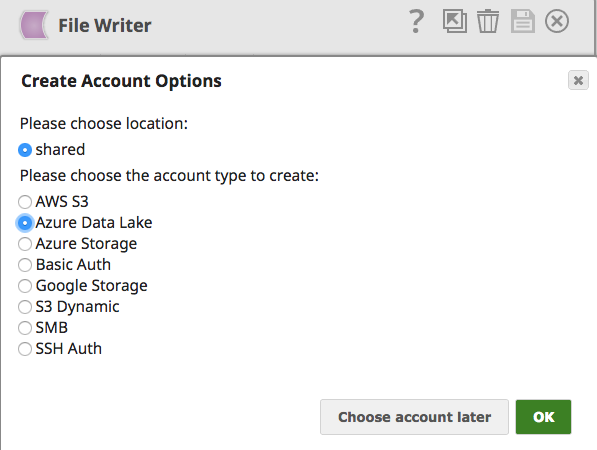
Mit dem File Writer Snap und der Auswahl des Azure Data Lake-Kontos (siehe unten) können Sie die aus verschiedenen Systemen zusammengeführten Daten problemlos in Azure Data Lake speichern.
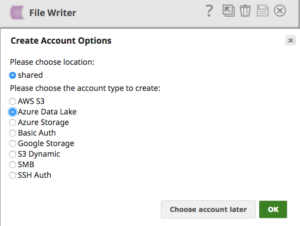
Alles in allem kann der Data Lake ein zentraler Speicher für beliebige Daten sein, der den Benutzern mehr Möglichkeiten bietet, Erkenntnisse aus verschiedenen Datenquellen zu gewinnen. Und SnapLogic ist bereit, es den Benutzern zu erleichtern, ihre Daten schnell und einfach in den Data Lake (in diesem Fall einen Azure Data Lake Store) zu verschieben.
Pavan Venkatesh ist Senior Produktmanager bei SnapLogic. Folgen Sie ihm auf Twitter @pavankv.