






On a beaucoup parlé des données comme étant la nouvelle monnaie. Comme l'a écrit Rob Versaw, membre du conseil technologique de Forbes, dans son billet de blog, "Comment mettre en œuvre la nouvelle monnaie : Les données," "Les entreprises qui ont le plus grand potentiel de croissance et de conquête de parts de marché utilisent les données plus efficacement que leurs concurrents.." Le potentiel de création de valeur commerciale à partir des données existe bel et bien, mais l'obtention des données au bon endroit, au bon moment et dans le bon format est la clé de la réalisation de ce potentiel. Se contenter de prendre toutes les données disponibles et de les stocker dans un lac de données s'est avéré plus ou moins efficace.1 Le déplacement des applications et des données vers le site cloud est déjà en cours et continue d'évoluer. Le stockage et le traitement des big data suivront certainement une tendance similaire. Comment les entreprises peuvent-elles se préparer à une hydratation réussie des données ?
De toute évidence, les entreprises d'aujourd'hui ont adopté le site cloud et utilisent pleinement un large éventail d'applications SaaS dans de nombreux secteurs d'activité. Des applications telles que Salesforce, Workday et Zendesk contiennent des informations clés lorsqu'il s'agit de découvrir des informations commerciales. Les données en continu des capteurs IoT fournissent des informations précieuses sur l'état des équipements. Les données en continu des médias sociaux fournissent des informations en temps réel sur la façon dont les clients perçoivent vos offres. Cependant, pour tirer le maximum de valeur commerciale des données, vous devez ingérer et combiner des données provenant de nombreuses sources, que ce soit via les fournisseurs SaaS et les sources de streaming mentionnées ci-dessus, ou des sources plus traditionnelles telles que les données d'entreprise sur site (SGBD). En augmentant les sources de données primaires avec des sources de données internes et externes supplémentaires, les entreprises peuvent libérer un potentiel pour découvrir de nouvelles informations.
En tapant sur la touche cloud
Parallèlement au mouvement SaaS, le stockage des données sur le site cloud est désormais la nouvelle norme - que vous utilisiez un SGBD sur le site cloud tel que Snowflake, Amazon Redshift, l'entrepôt de données Microsoft Azure SQL, ainsi que le stockage d'objets dans des services tels que Amazon S3, Microsoft WASB, etc. Cloud Le stockage Cloud supprime la nécessité pour le service informatique de créer des sauvegardes et de répliquer les données puisque ces tâches font partie de l'offre de services cloud , réduisant ainsi le coût et la complexité de la gestion des ressources informatiques. Le stockage offre également un moyen rentable de stocker et de gérer les données de l'entreprise, permettant au service informatique de l'entreprise de devenir plus agile.
Traitement d'ensembles de données complexes
Si Hadoop et HDFS ont fourni aux entreprises la technologie nécessaire pour stocker et traiter des ensembles de données complexes et volumineux, cet environnement requiert des compétences spécialisées. En outre, ces clusters Hadoop ont toujours été des systèmes sur site qui nécessitent un investissement initial important pour démarrer. Les lacs de données et le traitement des grandes données suivent le mouvement cloud en se déplaçant vers le site cloud. La première phase est appelée "lift and shift", où les entreprises déplacent simplement le cluster Hadoop sur site vers un fournisseur cloud fonctionnant dans un réseau virtuel, en profitant des avantages de l'IaaS tels que le coût et la facilité de mise à l'échelle. Toutefois, dans cette phase, les grappes, toujours gérées par l'entreprise, ne comblent pas le manque de compétences.
La phase suivante du traitement des big data consiste à déplacer le traitement vers un environnement Hadoop géré en tant que service (HaaS) tel que Amazon EMR, Microsoft HDInsight, Cloudera Altus, Hortonworks Data cloud, etc. Ces services gérés ont l'avantage de libérer les entreprises de la complexité de la gestion et de la maintenance des environnements Hadoop. Ces services gérés Hadoop peuvent également utiliser les systèmes de stockage sous-jacents cloud tels qu'Amazon S3 et Microsoft ADLS, ce qui facilite l'ingestion et la livraison des données sans avoir à les déplacer/copier vers HDFS.
Faciliter l'hydratation et le traitement des lacs de données
L'intégration hybride de SnapLogic plateforme fournit les moyens de mettre en œuvre l'hydratation des données à partir d'un ensemble complet de points d'extrémité, que ce soit sur cloud ou sur site. Notre architecture Snaplex unique est conçue pour échanger des données à travers un paysage d'entreprise hybride complexe et évolutif.
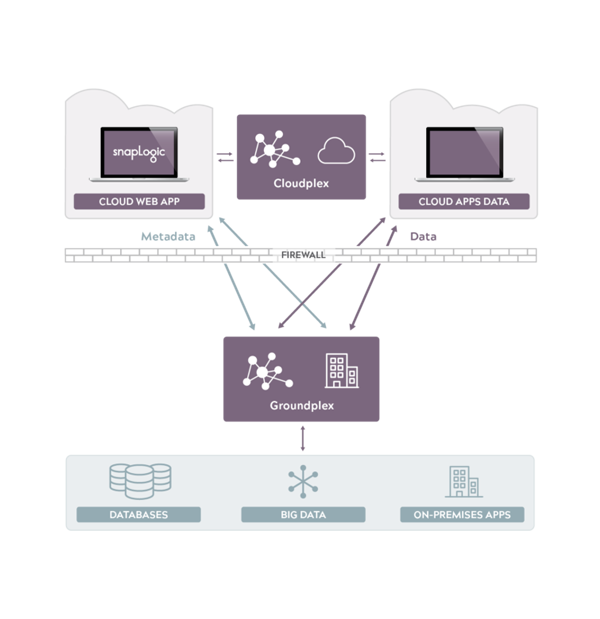
Pour aider à combler le déficit de compétences associé au travail avec les big data grâce à l'hydratation des données, la connexion aux points de terminaison est aussi simple qu'un simple glisser-déposer. Nous nous connectons aux points d'extrémité à l'aide de connecteurs appelés Snaps. Nous avons plus de 400 Snaps qui se connectent à des bases de données ERP, CRM, HCM, Hadoop, Spark, analytiques, de gestion des identités, de médias sociaux, de stockage en ligne, relationnelles, en colonnes et à valeur clé, ainsi qu'à des technologies telles que XML, JSON, OAuth, SOAP et REST, pour n'en citer que quelques-unes. En disposant d'un ensemble complet de points d'extrémité, SnapLogic peut augmenter la valeur du traitement des big data en incluant une plus grande variété de données.
SnapLogic étend l'intégration de vos intégrateurs informatiques traditionnels aux intégrateurs ad hoc du LoB grâce à son interface de programmation visuelle. Le concepteur visuel de SnapLogic permet aux utilisateurs de LoB, aux spécialistes de l'intégration et aux informaticiens d'assembler des intégrations en quelques heures, et non en quelques jours ou semaines, sans avoir besoin de coder.
Les données devenant la nouvelle monnaie, les entreprises qui s'appuient véritablement sur les données bénéficieront d'un avantage concurrentiel. Nous avons assisté au déplacement des données et des applications vers le site cloud, et nous voyons maintenant le traitement des big data se déplacer vers le site cloud. Vos solutions de traitement des big data continueront d'évoluer tout comme vos SaaS et vos données l'ont fait avant elles. Êtes-vous prêt ? SnapLogic peut tout prendre en charge et est là pour votre migration vers le traitement des big data sur cloud.
1. [Source : Gartner : Derive Value From Data Lakes Using Analytics Design Patterns Sept 2017]




