





Selon McKinsey, les employés des entreprises utiliseront les données pour optimiser la quasi-totalité de leur travail d'ici à 2025. Les applications et les plates-formes de votre pile technologique fournissent déjà une énorme quantité de données qui peuvent fournir des informations commerciales essentielles. Mais avant de pouvoir exploiter vos données, vous devez trouver un moyen de gérer leur arrivée et leur circulation dans votre organisation.
C'est là qu'intervient l'épine dorsale de l'entreprise moderne : le pipeline de données.
Qu'est-ce qu'un pipeline de données ?
Un pipeline de données est une série de les workflows automatisés permettant de transférer des données d'un système à un autre.
D'une manière générale, le pipeline de données comprend trois étapes :
- Ingestion de données à partir du point A (la source).
- Transformation ou traitement.
- Chargement au point B (lac de destination, entrepôt ou système d'analyse).
Chaque fois qu'un traitement a lieu entre le point A et le point B, vous avez créé un pipeline de données entre ces deux points. Si le traitement a lieu après le point B, vous avez toujours créé un pipeline de données, mais sa configuration est différente.
Les pipelines de données consolident les données provenant de sources isolées en une source unique de vérité que l'ensemble de l'organisation peut utiliser, et sont donc essentiels à l'analyse et à la prise de décision. Sans pipeline, les équipes analysent les données de chaque source dans un silo, ce qui les empêche de voir comment les données se connectent à un niveau global.
Data Pipeline vs. ETL vs. ELT
Le terme "pipeline de données" est un terme générique, tandis que ETL (extraction, transformation, chargement) et ELT (extraction, chargement, transformation) sont des types de pipelines de données.
Les pipelines de données ETL extraient les données de la source, les transforment par le biais d'un ensemble d'opérations et les chargent dans l'entrepôt ou le système de destination. Une transformation est une action automatisée qui modifie les données avant qu'elles n'atteignent l'entrepôt. Les transformations les plus courantes sont les suivantes
- Nettoyage et déduplication des données.
- Agrégation de différents ensembles de données.
- Conversion des données dans un autre format.
- Effectuer des calculs pour créer de nouvelles données.
Si vous utilisez un pipeline ETL, votre objectif est de valider, d'élaguer et de normaliser vos données avant qu'elles ne soient chargées dans l'entrepôt.
Si vous transformez les données une fois qu' elles ont atteint l'entrepôt, vous utilisez un pipeline de données ELT. Ceux qui utilisent le stockage de données sur cloud préfèrent souvent l'ELT parce qu'il leur permet d'accélérer et de simplifier la livraison de la source à l'entrepôt.
Exemples d'architecture de pipeline de données
Un pipeline ETL simple se présente comme suit :
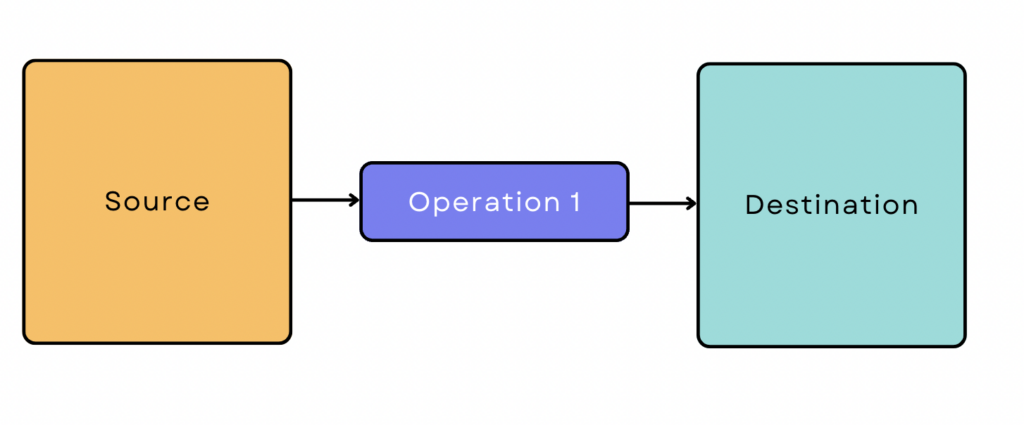
Cependant, la plupart des pipelines de données ne sont pas aussi simples. Ils impliquent généralement de nombreuses sources et opérations, et les données interagissent souvent avec d'autres outils et plateformes en cours de route. Parfois, différentes opérations sont exécutées en parallèle pour accélérer le processus.
Au début du pipeline de données, il existe deux façons d'ingérer des données à partir de la source : le traitement par lots et le traitement en temps réel/en flux continu. Parfois, vous avez besoin d'une combinaison des deux. Ces différents besoins d'ingestion sont à la base de trois configurations courantes de pipeline de données.
Pipeline de données par lots
Dans le traitement par lots, l'outil d'ingestion extrait les données de la source par lots à des intervalles de temps périodiques. Un pipeline de données basé sur le traitement par lots est un pipeline qui commence par l'ingestion par lots. Supposons que vous souhaitiez extraire des données transactionnelles de Google Analytics, appliquer trois transformations et les charger dans l'entrepôt. Votre pipeline ressemblerait à ceci :
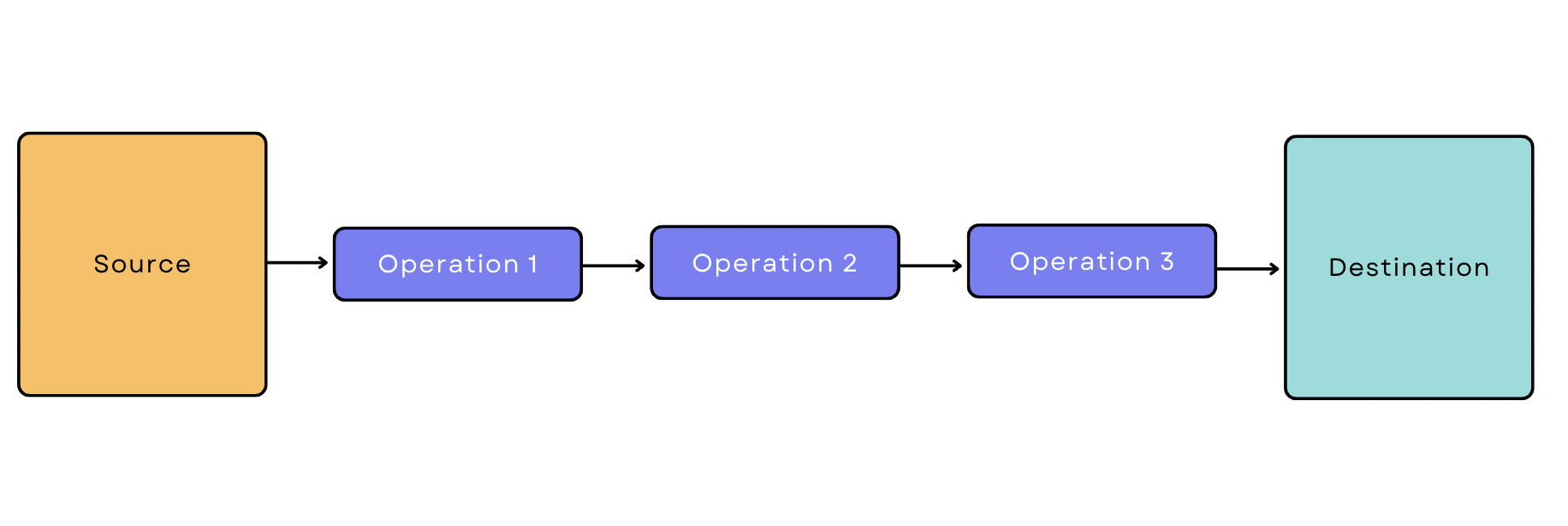
Pipeline de données en temps réel/en continu
Dans le traitement en temps réel/en flux continu, les données sont ingérées à partir de la source en continu et en temps réel. Un pipeline de données en continu est un pipeline qui commence par l'ingestion de données en temps réel/en flux continu.
Par rapport à l'ingestion par lots, l'ingestion en temps réel/en flux continu est plus difficile à gérer pour les logiciels, car ils doivent être activés et surveiller en permanence le flux de données en temps réel. Cette complexité supplémentaire se manifeste également dans le pipeline lui-même ; la version la plus simple d'un pipeline de données en continu est un peu plus compliquée que la version la plus simple d'un pipeline basé sur le traitement par lots.
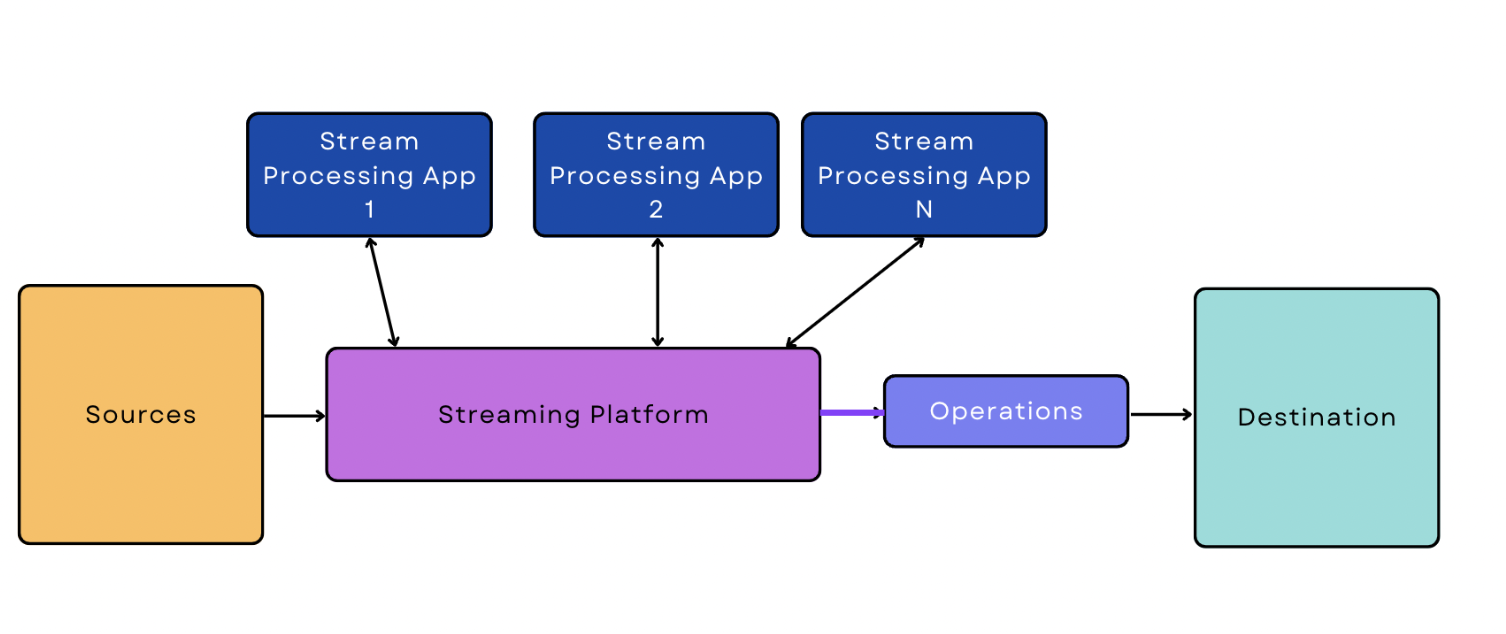
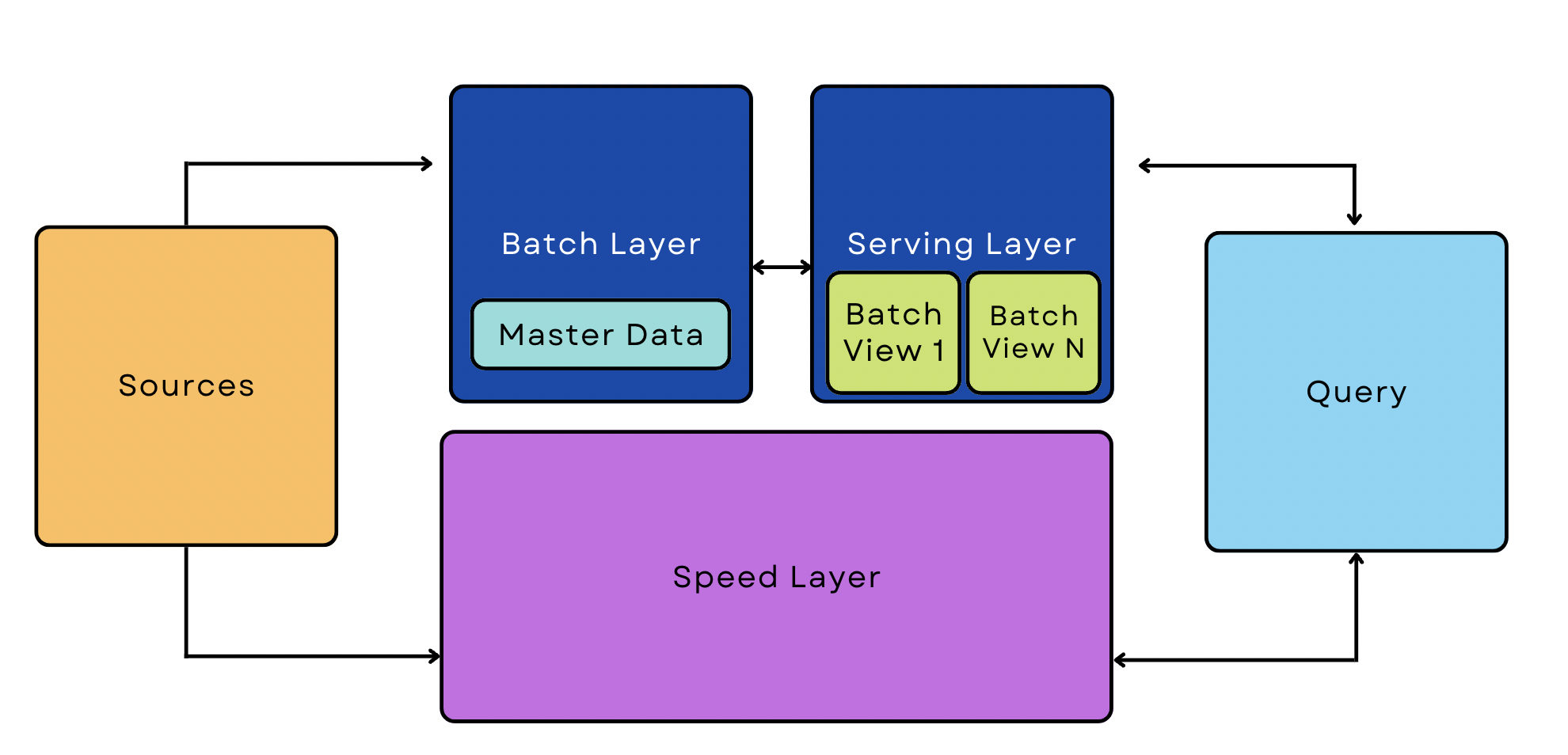
Pipeline de l'architecture Lambda
Un pipeline Lambda combine des processus batch et streaming dans la même architecture. Ces pipelines sont des moyens populaires de gérer les big data car ils peuvent s'adapter aux cas d'utilisation en streaming et en temps réel.
5 étapes pour créer un pipeline de données interne à partir de zéro
Par rapport à l'utilisation d'outils prêts à l'emploi, la création d'un pipeline à partir de zéro est souvent un processus qui demande beaucoup de temps et de ressources. En règle générale, ce processus n'a de sens que pour les organisations ayant des besoins exceptionnellement spécialisés et disposant de nombreuses ressources d'ingénierie. Si votre entreprise répond à ces critères, envisagez de suivre les étapes suivantes pour créer votre pipeline.
1. Définissez vos objectifs et vos contraintes
Commencez par comprendre précisément ce que vous attendez du pipeline. Souhaitez-vous extraire des informations d'une base de données et les associer à une autre ? Avez-vous besoin d'intégrer vos résultats dans une boutique en ligne ? De combien de sources disposerez-vous ?
Plus précisément, il s'agit d'exposer les points suivants :
- Sources - Quelles sont les sources de données utilisées ?
- Type d'ingestion des données - Les données peuvent-elles être traitées par lots ou devez-vous les traiter en continu ?
- Destination - Où vont les données ?
- Transformation - Comment les données doivent-elles être modifiées pour qu'elles soient cohérentes d'une source à l'autre et utiles aux outils d'analyse ? Quand ces changements doivent-ils intervenir ?
- Arrêts - Les données doivent-elles être transférées vers d'autres applications ou destinations en cours de route ?
2. Établir un plan de haut niveau Workflow
Esquissez les principaux composants de votre pipeline à l'aide d'un logiciel de modélisation, d'un logiciel d'organigramme ou même d'un crayon et d'une feuille de papier. Cette étape vous aide à visualiser les différents composants de votre architecture et leurs interactions.
Laissez les questions suivantes vous guider dans la construction de votre pipeline, en visant le flux de travail le plus simple possible :
- Existe-t-il des dépendances en aval par rapport aux travaux en amont ? Par exemple, si vous disposez de données sources provenant de bases de données MySQL, avez-vous besoin des résultats d'un processus ETL avant de passer à une autre étape ?
- Quels sont les travaux qui peuvent être exécutés en parallèle (le cas échéant) ?
- Plusieurs outils doivent-ils avoir accès aux mêmes données ? Quel type de synchronisation est nécessaire ?
- Qu'est-ce que le workflow pour les emplois échoués ? Qui en est informé ?
- Si les données ingérées ne passent pas la validation, où vont-elles ? Voulez-vous les écarter automatiquement ou préférez-vous diagnostiquer les erreurs et les réintroduire dans votre pipeline ?
3. Concevoir les composants de base
Si vous créez votre pipeline de données à partir de zéro, vous devrez écrire un logiciel pour extraire et transformer les données. Cette étape varie considérablement d'un pipeline à l'autre.
Supposons que vous souhaitiez consolider les données clients provenant de différents systèmes, tels que votre système de gestion de la relation client (CRM) et votre système de point de vente. Dans ce cas d'utilisation, vous écrirez des programmes qui nettoient et dédupliquent les données, puis les "normalisent" en fonction des mêmes champs (sexe, format de données, etc.) afin de les assimiler correctement. Les données consolidées pourraient ensuite être utilisées pour informer les notifications personnalisées, les ventes incitatives et les campagnes d'e-mailing segmentées.
4. Dimensionner le pipeline
Effectuez des tests d'étalonnage et de charge pour identifier les éventuels goulets d'étranglement et les problèmes d'évolutivité. Cela vous aidera à identifier les performances cibles et maximales de votre pipeline, la charge cible et maximale, ainsi que les limites de performance acceptables.
Si les tests de charge révèlent des goulets d'étranglement ou d'autres problèmes d'évolutivité, évaluez les moyens d'y remédier.
- L'équilibrage de charge répartit le trafic réseau sur un groupe de serveurs, en équilibrant le volume de trafic que chaque serveur doit gérer. Cette solution est utile lorsque vous servez des millions d'utilisateurs et que vous devez répondre à un grand nombre de demandes simultanées.
- La répartition des bases de données est un type d'équilibrage de la charge. Dans ce cas, vous répartissez un grand volume de données (et non de trafic) sur un réseau de serveurs. Il est utile pour les mêmes cas d'utilisation que l'équilibrage de charge - si vous avez des millions d'utilisateurs, vous travaillez avec une énorme quantité de données utilisateur.
- La mise à l'échelle horizontale consiste à ajouter des machines à votre parc (mise à l'échelle vers le bas) plutôt que d'ajouter des GPU ou de la RAM aux serveurs existants (mise à l'échelle vers le haut). La mise à l'échelle permet généralement une plus grande flexibilité que la mise à l'échelle supérieure, mais elle peut être plus coûteuse.
- La mise en cache permet de stocker des copies d'un fichier dans un emplacement de stockage temporaire afin de pouvoir y accéder plus rapidement. En amont, la mise en cache permet aux utilisateurs d'accéder au contenu du site web et de rechercher des informations dans votre base de données le plus rapidement possible.
5. Mettre en œuvre un cadre de gouvernance des données
À ce stade, votre pipeline de données est complet - mais vous avez besoin d'un plan pour garder les données des utilisateurs sécurisées et conformes à la réglementation tout au long de votre pipeline. Identifiez toutes les données sensibles que vous allez ingérer et stocker, y compris les informations personnelles, les données de cartes de crédit et tout ce qui est protégé par le GDPR ou d'autres réglementations.
Ensuite, décrivez les mesures que vous prendrez pour protéger ces données. Les mesures de sécurité les plus courantes sont les suivantes
- Cryptage des données.
- Mise en place de contrôles d'accès basés sur les autorisations.
- Tenir des registres et des dossiers détaillés.
- Surveillance des données au moyen d'outils tiers tels que Datadog.
- Permettre l'authentification multifactorielle et l'application d'un mot de passe fort en amont pour aider à se prémunir contre les violations.
Construire ou acheter ? Alternatives à la construction d'un pipeline à partir de zéro
La création d'un pipeline de données à partir de zéro peut être coûteuse et difficile par rapport à l'utilisation d'outils d'ingestion prêts à l'emploi avec des connecteurs prédéfinis. Les modifications en amont de l'API ou les nouveaux besoins en matière d'analyse peuvent modifier la portée d'un projet en cours de route, ce qui entraîne un travail constant et permanent.
Les outils d'ingestion prêts à l'emploi permettent de gagner du temps et de l'argent en automatisant les fonctions critiques sans vous obliger à écrire un logiciel pour effectuer chaque tâche. Les plateformes d'intégration telles que SnapLogic disposent de bibliothèques de connecteurs prédéfinis que vous pouvez utiliser pour créer des pipelines de données personnalisés - aucun codage n'est nécessaire.
Construire des pipelines de données intelligents avec SnapLogic
Ne gaspillez pas vos ressources d'ingénierie en réinventant la roue. Les connecteurs Low-Code/No-Code de SnapLogic, conçus par des experts, vous permettent de créer des pipelines de données puissants et flexibles presque immédiatement. Avec un choix de plus de 600 connecteurs et des options de synchronisation et de préparation des données automatisées, SnapLogic s'intègre à l'ensemble de votre pile technologique.
Prêt à découvrir à quel point il peut être facile de créer des pipelines de données de qualité professionnelle ? Essayez une démo dès aujourd'hui.



