






Ce blog présente les concepts d'entrepôt de données, de lac de données et d'entrepôt de données, leur comparaison et leur contraste, ainsi que les avantages de chaque approche. L'objectif de ce blog est de fournir une vue d'ensemble de l'architecture de haut niveau.
Entrepôts de données classiques
Cheval de bataille de longue date du monde de la veille stratégique et de l'analyse des données, le concept classique d'entrepôt de données existe depuis les années 1980 et la popularité de l'entrepôt de données en tant qu'outil commercial est largement attribuée à l'informaticien américain Bill Inmon. Inmon, souvent considéré comme le "père" de l'entreposage de données, a défini à l'origine l'entrepôt de données comme "une collection de données orientée vers le sujet, non volatile, intégrée et variable dans le temps, destinée à soutenir les décisions de la direction".
Les entrepôts de données sont devenus, et restent, des outils populaires pour les entreprises du monde entier, car ils leur permettent d'analyser les données et les changements au fil du temps, de créer des informations et de parvenir à des conclusions qui aident à prendre des décisions commerciales.
Les entrepôts de données classiques [Figure 1] fonctionnent généralement comme des référentiels centraux où les informations, c'est-à-dire les données, arrivent des unités commerciales internes, des partenaires commerciaux externes, des opérations de vente, des opérations de fabrication et d'une multitude d'autres sources. L'objectif et l'avantage de l'entreposage de données sont de collecter toutes ces informations, de les stocker, de les agréger et d'avoir une vision holistique de l'entreprise afin d'obtenir des informations plus complètes et plus exhaustives sur l'entreprise. Plus un entrepôt de données peut aider les utilisateurs et les dirigeants à créer des informations ou à en rendre compte rapidement, mieux c'est.
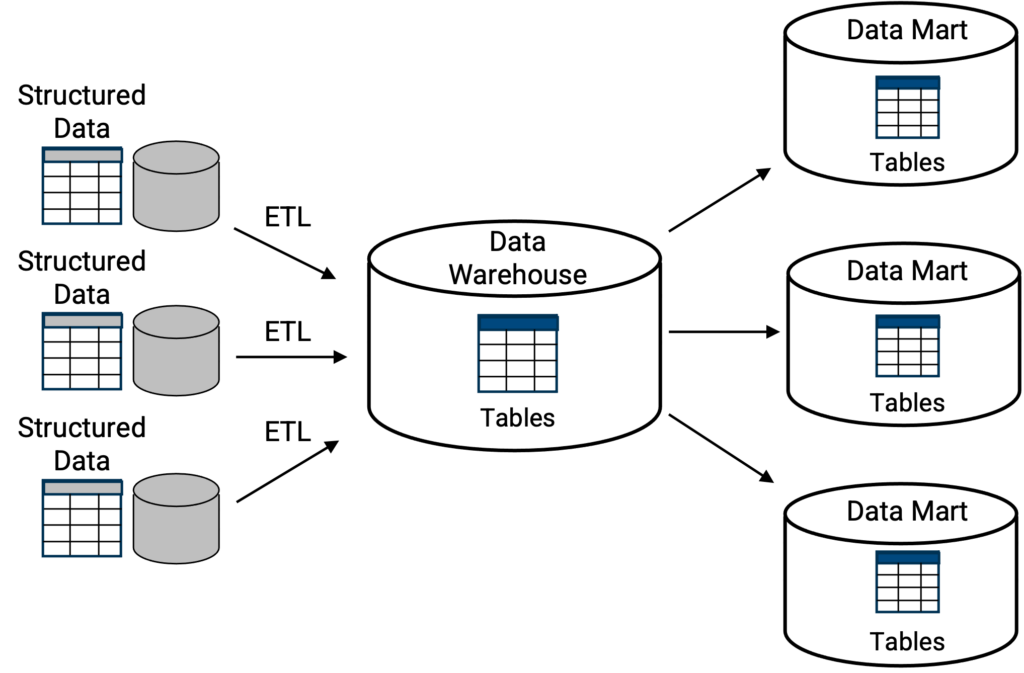
Ci-dessus, la topologie classique d'un entrepôt de données où la structure de stockage primaire est un emplacement centralisé pour une collection de tables ou de bases de données. Les capacités d'interrogation, généralement SQL, sont intégrées de manière native dans l'entrepôt de données. Comme indiqué, les bases de données ou les tables peuvent être répliquées dans des "data marts" plus petits, en tant que sous-ensemble de l'entrepôt de données, où chaque "data mart" remplit une fonction spécifique, telle qu'un "data mart" financier, ou un "data mart" de fabrication, etc.
Les exemples d'entrepôts de données classiques comprennent Oracle, Teradata, Amazon Redshift, Azure Synapse - tandis que la mise en œuvre du déploiement peut différer selon que l'entrepôt de données classique est déployé sur site ou sur le site cloud.
Lacs de données
Le principal avantage d'une architecture de lac de données (née en 2010) est qu'il s'agit d'une option plus flexible pour servir de dépôt central pour davantage de types de données [Figure 2]. Toutes sortes de données, dont la plupart sont trop encombrantes, trop volumineuses en termes de volume total ou trop variées pour qu'un entrepôt de données classique puisse les traiter efficacement, le point clé étant de les traiter efficacement [si elles sont traitées].
Avec les privilèges d'accès appropriés, toutes les communautés de professionnels des données (analystes commerciaux, scientifiques des données, ingénieurs des données, etc.) au sein d'une entreprise qui doivent travailler avec les données et les analyser doivent utiliser une variété de méthodes d'interrogation, en fonction du format et de la structure des données interrogées.
Cependant, cela a un prix - ce prix est traditionnellement la complexité. En effet, le défi posé par les lacs de données est qu'il faut des compétences particulières, ou un service informatique complet, pour non seulement gérer tous les différents types de fichiers de données qui atterrissent dans un lac de données et prendre en charge les divers outils d'interrogation, mais aussi pour créer des ensembles de données interrogeables, sous la forme d'un tableau, à partir de fichiers bruts. Si l'accès et la lecture ou la prévisualisation des données dans un lac de données peuvent être relativement simples, la tentative d'interrogation d'un ensemble de données pour en tirer des informations est une autre affaire et dépend de la structure des données.
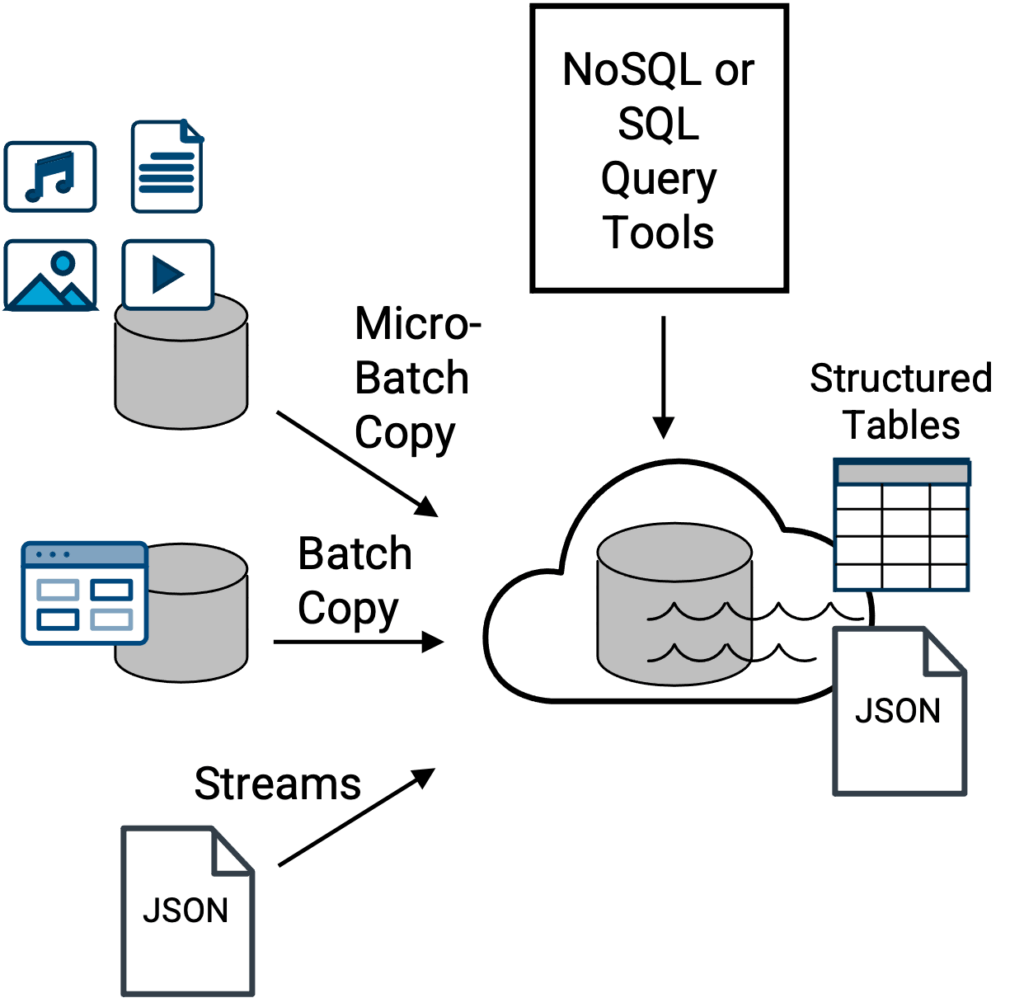
Ci-dessus, topologie traditionnelle de lac de données où les fichiers et les données provenant d'une variété de sources sont ingérés dans le lac de données pour un stockage centralisé, un accès et, potentiellement, une interrogation ultérieure via des outils et des moteurs d'interrogation SQL ou NoSQL. Les outils d'interrogation SQL fonctionnent avec des tables structurées, tandis que les outils d'interrogation NoSQL fonctionnent avec des fichiers de documents JSON natifs. Voici quelques exemples de lacs de données Amazon S3, Apache Iceberg, Azure Data Lake Storage (ADLS), Google Cloud Storageet Hadoop HDFS-stockage basé sur les données.
Par exemple, il peut être facile d'accéder à des données non structurées telles que des vidéos, des sons ou des images, de les prévisualiser et de les explorer sous forme de fichiers individuels à partir d'un lac de données, mais comment obtenir facilement des informations à partir de 1 000 images, et quel type d'outil de requête utiliser ?
Si vous êtes en mesure de répondre rapidement à cette question et d'y parvenir, comptez sur le petit pourcentage de personnes qui ont les compétences nécessaires pour le faire. [La réponse est que, dans la plupart des cas, des métadonnées sur les données non structurées sont créées et qu'elles deviennent les données qui sont analysées pour en tirer des informations à l'aide d'outils SQL standard. Les fichiers non structurés proprement dits peuvent ou non être convertis en un équivalent de chaîne de données, en fonction du cas d'utilisation spécifique des données non structurées].
À l'autre extrémité du spectre, on trouve des données entièrement structurées, avec des lignes et des colonnes, c'est-à-dire un tableau. N'importe quel analyste de données disposant d'un outil de requête, en particulier d'un outil de requête SQL, peut assez facilement interroger 1 000 lignes ou colonnes de données et en tirer des enseignements. Au milieu du spectre se trouvent les données semi-structurées ou les fichiers de documents, tels que les fichiers JSON. De nos jours, les fichiers JSON sont faciles à explorer et, bien qu'ils ne soient pas aussi simples et directs qu'une table structurée à interroger de manière entièrement relationnelle, les données JSON peuvent être interrogées avec des outils NoSQL, et il existe de nombreux outils populaires, dont certains ont considérablement évolué depuis 2010.
Les professionnels des données, y compris les scientifiques des données, peuvent indiquer qu'ils apprécient la flexibilité d'explorer, ou de prévisualiser, des fichiers individuels ou des ensembles de données. Toutefois, lorsqu'il s'agit d'interroger des données et de découvrir des informations et des relations entre les données, la plupart des professionnels des données préfèrent travailler avec des bases de données et des tableaux de données structurés (pour une expérience similaire à celle d'un entrepôt de données classique) plutôt que d'essayer de construire une requête à partir de fichiers bruts individuels.
C'est pourquoi la création d'un ensemble de données à partir de fichiers bruts devra être confiée à une personne technique de l'informatique ayant les compétences nécessaires pour effectuer une telle tâche. Cela entraîne des retards dans la valorisation des données et crée des charges (et des goulets d'étranglement) pour les services informatiques. En outre, en l'absence d'une gouvernance et d'un catalogage appropriés, les lacs de données peuvent devenir des décharges de données - le proverbial marécage de données. Au fil des ans, en l'absence d'outils appropriés, l'approche des lacs de données a acquis la réputation d'être excessivement complexe à mettre en œuvre et à gérer.
Entrepôt de données classique sur un lac de données
Pour la plupart des entreprises, les lacs de données traditionnels et les entrepôts de données classiques n'existent normalement pas de manière complètement séparée. Les données d'un lac de données peuvent être chargées ou transférées dans un entrepôt de données, Figure 3. Il ne s'agit pas d'un nouveau concept, étant donné le chevauchement de l'entreposage de données et des lacs de données depuis 2010.
Toutefois, les exigences de l'entreprise en matière de données et les cas d'utilisation, ainsi que les caractéristiques et capacités spécifiques de l'entrepôt de données classique, dicteront l'ampleur du transfert. Il s'agit notamment de savoir si les données doivent être structurées ou semi-structurées, telles que les données JSON en continu, pour lesquelles l'entrepôt de données devra disposer d'une fonction interne permettant de transformer, ou d'aplatir, le fichier JSON de son format de document natif et parfois hiérarchique en un format de tableau de données structuré tel qu'il est attendu par l'entrepôt de données classique. Si l'entrepôt de données ne dispose pas de cette capacité, des outils ou des processus externes seront nécessaires.
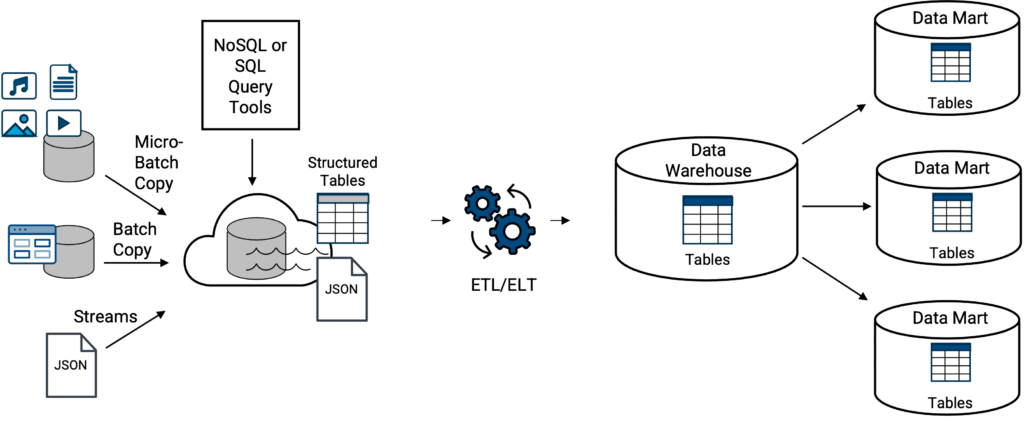
Ci-dessus, les exemples d'entrepôts de données classiques sur un lac de données comprennent tous les types d'entrepôts de données classiques susmentionnés couplés de manière souple (intégrés) avec tous les lacs de données susmentionnés, Amazon Redshift sur S3 (aka, Amazon Spectrum), Azure Synapse sur ADLS, Google Big Query sur Google Cloud Storage, et Snowflake sur S3 externe (continuez à lire).
Compte tenu du spectre entre les données non structurées et les données structurées, les professionnels des données, y compris les scientifiques des données, indiqueront qu'ils apprécient la flexibilité d'explorer des fichiers individuels ou des ensembles de données. Toutefois, lorsqu'il s'agit d'interroger des données et de découvrir des informations et des relations entre les données, la plupart des professionnels des données préfèrent travailler avec des bases de données et des données structurées (comme dans le cas d'un entrepôt de données classique) plutôt que d'essayer d'élaborer une requête à partir de fichiers bruts individuels.
C'est pourquoi la création d'un ensemble de données à partir de fichiers bruts et les transferts de données d'un lac de données vers un entrepôt de données classique devront être confiés à une personne technique au sein des services informatiques ayant les compétences nécessaires pour effectuer une telle tâche. Étant donné que l'attrait d'un lac de données réside en partie dans la possibilité d'interroger les données directement dans le lac, on croit à tort qu'il ne sera pas nécessaire de créer des ensembles de données interrogeables, qu'il ne sera pas nécessaire de dupliquer les données et qu'il s'agit uniquement d'une question d'entrepôt de données. Les ensembles de données structurés et interrogeables sont tout aussi importants dans un lac de données.
Dans l'ensemble, cette situation entraîne des retards dans l'exploitation des données et crée des charges (et des goulets d'étranglement) pour les services informatiques.
Nouvelle génération d'entrepôts de données cloud : les entrepôts de données (data lakehouses)
Les entrepôts de données cloud de nouvelle génération, apparus en 2015, viennent à la rescousse. Outre la prise en charge des fichiers CSV courants et d'autres formats, les entrepôts de données cloud de nouvelle génération peuvent accepter et charger des fichiers JSON (semi-structurés) dans leur format natif (figure 4). À partir de là, un entrepôt de données de nouvelle génération peut disposer d'outils intégrés pour analyser automatiquement les données JSON, aplatir toute structure de tableau et présenter une version de tableau orientée colonne des données JSON, prête à être interrogée de manière relationnelle avec le langage SQL standard, ce qui résout un problème critique avec les lacs de données et les entrepôts de données classiques sur les approches de lacs de données. Les options plateforme (d'un fournisseur) les meilleures et les plus riches en fonctionnalités, ainsi que les plus évolutives et les plus souples pour ce concept seront les solutions basées sur cloud.
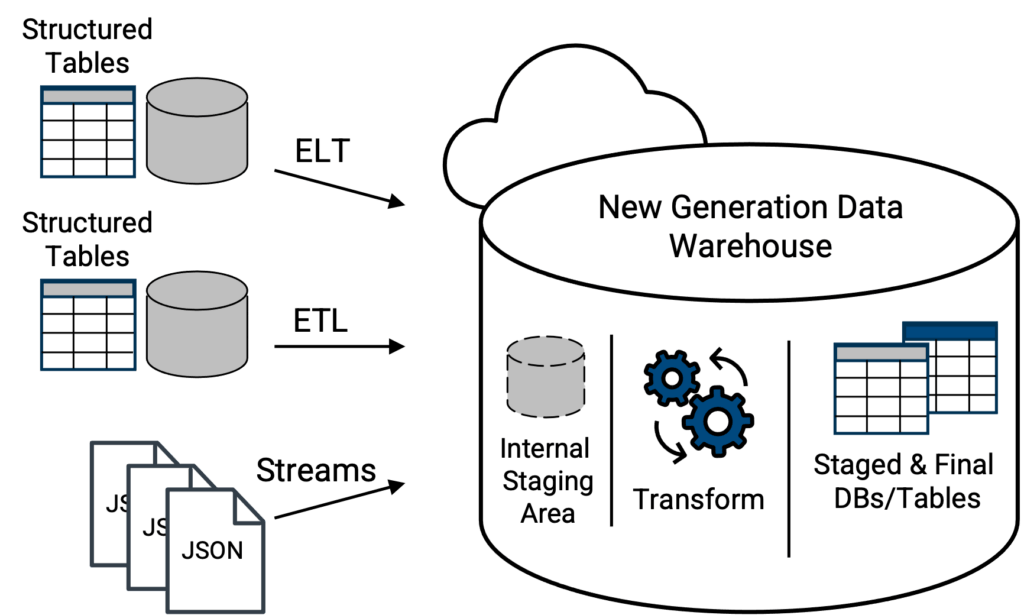
Ci-dessus, topologie moderne où les tables de données et les fichiers JSON natifs sont directement chargés dans un entrepôt de données de nouvelle génération. Les capacités de l'outil d'intégration des données à mobiliser les données vers l'entrepôt de données détermineront si les tables de données doivent d'abord être transformées pour correspondre à la structure du schéma de la table cible dans l'entrepôt de données. Un entrepôt de données de nouvelle génération vraiment moderne aura la capacité d'analyser le fichier JSON natif lors du chargement et de le transformer en une forme de table interrogeable. Ainsi, le fichier JSON n'est plus dans son format natif littéral, mais ses données sont sous une forme qui peut être interrogée par l'entrepôt de données de nouvelle génération à l'aide d'un langage SQL standard.
La couche de stockage étant souvent séparée de la couche de calcul, les nouvelles générations d'entrepôts de données cloud (ou plateformes de données comme on les appelle parfois) peuvent essentiellement offrir une expérience intégrée de lac de données et d'entrepôt de données tout-en-un - créant ainsi le concept de lac de données (data lakehouse). Cette conception élimine une partie de la complexité des approches typiques des lacs de données. Les exemples incluent Snowflake et Databricks Delta.
En outre, la séparation des couches de calcul et de stockage permet à ces deux groupes de ressources d'évoluer indépendamment et d'utiliser des éléments de stockage moins coûteux, ce qui réduit le coût du stockage par téraoctet par rapport aux approches classiques des entrepôts de données qui verrouillent les données et les ressources de calcul au fur et à mesure qu'elles évoluent.
La technologie d'entreposage de données de nouvelle génération se chargeant de transformer les fichiers de données non relationnels en une structure relationnelle, les analystes commerciaux, les scientifiques et les ingénieurs des données peuvent extraire de la valeur de ces données beaucoup plus rapidement, en libre-service. En outre, les tables formatées en colonnes pour les données JSON permettent généralement des analyses plus rapides lorsqu'une interrogation relationnelle complexe est nécessaire, par rapport à l'utilisation d'outils d'interrogation NoSQL avec JSON sous forme de document natif.
En outre, certains entrepôts de données de nouvelle génération, ou data lakehouses, offrent une zone de stockage interne où les fichiers JSON peuvent être transférés et rester dans leur forme native. Par exemple, Snowflake dispose d'une zone de stockage interne S3 distincte de l'infrastructure de stockage d'objets pour ses entrepôts de données virtuels. Cependant, les données JSON ne pourront pas être interrogées tant qu'elles n'auront pas été chargées dans l'entrepôt de données et transformées. Attention, tous les entrepôts de données n'offrent pas cette capacité de stockage au sein de la même structure physique.
Dans l'ensemble, l'approche de la conception d'un lac élimine une grande partie de la complexité des approches typiques des lacs de données, mais elle présente également des inconvénients.
Premièrement, plus l'entreprise est grande et plus il y a de professionnels des données, plus il est probable que les groupes individuels ne préfèrent pas tous opérer au sein du même entrepôt de données ou de la même solution de centre de données. Deuxièmement, les principaux fournisseurs de solutions de stockage de données ont tendance à appliquer une tarification basée sur la consommation, ce qui signifie que le compteur tourne en permanence en fonction de l'utilisation de la solution de stockage de données.
Si tout le monde est entassé dans un entrepôt de données de nouvelle génération avec une tarification à la consommation, il faut veiller à surveiller les ressources et à s'assurer qu'elles sont désactivées lorsqu'elles ne sont pas utilisées. De plus, des alertes doivent être mises en place pour signaler les seuils d'utilisation ou de coût.
Par conséquent, les entreprises découvrent que l'arrangement le plus flexible consiste à faire coexister un lac de données basé sur cloud et un entrepôt de données de nouvelle génération cloud , lakehouse, plutôt qu'un entrepôt de données classique. Cette approche permet au lac de données d'être le principal réservoir de toutes les données, tout en desservant toutes les communautés et en maximisant la flexibilité.
Ce qu'il faut rechercher dans un outil d'intégration de données
Les outils modernes d'intégration de données peuvent faciliter et automatiser la mobilisation de grandes quantités de données vers ou depuis l'un des concepts suivants : entrepôt de données, lac de données ou lac de données. Ces outils vous permettent d'obtenir des données à partir d'une grande variété de sources. Cela permet d'économiser du temps et des efforts lors de la préparation des données pour l'analyse, ce qui permet d'accélérer les projets d'analyse.
Les outils modernes d'intégration de données garantissent également que les données sont dans le bon format et la bonne structure, ce qui facilite leur interrogation et leur analyse. En outre, ces outils sont souvent dotés de fonctions qui permettent de sécuriser les données et de les rendre conformes à la réglementation.
Lors de la première mise en place d'un système de données d'entreprise plateforme , optez pour un outil d'intégration de données facile et intuitif à utiliser. Idéalement, optez pour un outil doté d'une fonctionnalité de glisser-déposer et de la possibilité de transformer visuellement les données à l'intérieur du site plateforme, ce qui permet à des personnes de tous niveaux de compétences de travailler facilement avec les données. Pour en savoir plus sur l' intégration et l'automatisation des données dans votre entreprise.




