






Dans le premier article de cette série en deux parties, j'ai mis en évidence trois des cinq capacités permettant de rendre votre architecture de données moderne plus moderne. Mais pas seulement plus moderne, moins complexe aussi.
Récapitulation des trois capacités (résumées dans la partie 1) à rechercher :
1. Intégrations de données et intégrations d'application à application combinées
Pousser les données cloud (ELT ou ETL) vers un entrepôt de données cloud tel que BigQuery, Redshift, Snowflake ou autre (avec des outils tels que Fivetran, Matillion, Informatica, etc.) est idéal pour l'analyse et la compréhension post-production et constitue un cas d'utilisation dominant. Cependant, l'intégration des données en elle-même est potentiellement limitative. Une capacité plus moderne est d'avoir, dans le même outil, la flexibilité d'intégrer les données entre les applications pour les charges de travail opérationnelles, en particulier lorsque la performance en temps réel est nécessaire. En outre, par rapport à l'accès aux données via un entrepôt de données, les expériences de données in-app peuvent être plus rapides et plus simples pour une base plus large d'utilisateurs.
2. Modèles de chargement bidirectionnels (ETL, ELT et ETL inversé) - Sans complication
En plus de s'étendre aux intégrations d'application à application, la combinaison de l'ETL et de l'ELT avec des modèles d'ETL inversé, toujours dans une seule solution, est une approche plus moderne qui offre une certaine flexibilité (par rapport à des outils comme Census, Hightouch, Hevo, etc.) pour sélectionner le modèle de chargement qui convient le mieux à votre cas d'utilisation spécifique. L'avantage supplémentaire est la consolidation des outils, ce qui simplifie votre architecture de données.
3. Traiter des données sur site et des données résidant sur le site Cloud sans sacrifier la sécurité
Cloud-Les données résidentes sont la tendance actuelle, mais pour certaines entreprises sensibles à la sécurité ou à la confidentialité, les données sur site ne s'approcheront pas d'un site cloud (quelle qu'en soit la raison). Une solution plus moderne sépare l'exécution des données du contrôle des données, ce qui permet à vos données ou à vos intégrations d'application à application de s'exécuter sur n'importe quelle infrastructure, située n'importe où, y compris derrière un pare-feu sur site, tout en conservant un contrôle souple et agile sur cloud .
Passons maintenant aux deux autres capacités, plus modernes :
4. Données + intégrations inter-applications + API pour une expérience Dev/Ops plus moderne des services de données
Les produits et services de données font fureur ces temps-ci. Mais si l'on considère une fois de plus (comme indiqué dans la partie 1) l'attention que le maillage des données et les principes du maillage des données (données appartenant au domaine, données en tant que produit, architecture de données en libre-service et gouvernance informatique fédérée) ont suscitée, il y a une intersection de nombreuses technologies, dont l'intégration et la gestion des API, pour que le maillage des données se produise. Ensuite, il y a la fourniture de services de données, qui nécessite généralement le développement, le déploiement et la gestion d'API.
La culture axée sur les API (avec des solutions comme Apigee, Kong, etc.) existe depuis un certain temps - du point de vue du développement d'applications et de logiciels. Cependant, du point de vue de l'architecture des données - que les données restent en place ou que les pipelines soient construits pour faire circuler les données - les produits, services et pipelines de données ont des processus de développement qui leur sont propres. Pour cette raison, le développement de produits, de services et de pipelines de données bénéficierait du développement d'applications, en particulier de l'intégration continue et de la livraison continue (CI/CD), ainsi que des meilleures pratiques dev-ops.
Ainsi, si l'intégration, la propriété du domaine, le développement et l'exploitation des produits de données, la fourniture de services de données et les API constituent une intersection importante, la combinaison d'un maximum de ces capacités dans une solution unique plateforme - qui est également orientée vers le libre-service - apportera des avantages en termes de consolidation et de simplification. De plus, les utilisateurs, qu'ils soient techniciens ou non, bénéficieront d'une expérience de développement plus moderne et intégrée.
"En nous appuyant sur SnapLogic pour construire notre site plateforme intégrant l'IA, nous pouvons dynamiser notre entreprise et permettre à nos employés d'accéder aux données dont ils ont besoin du bout des doigts. Plus de 95 % de toutes nos API sont orchestrées par SnapLogic, ce qui permet à nos employés de créer facilement des applications à partir de nos données Marko plateforme ", Brian Murphy, vice-président des données chez Aramark, une entreprise de services alimentaires.
5. Une architecture d'intégration évolutive de A à Z
De même, si vous disposez d'un environnement qui doit prendre en charge plus d'un domaine - par exemple, plusieurs succursales, différentes unités commerciales, plusieurs équipes fonctionnelles, etc.
Techniquement, vous pouvez bien sûr déployer une nouvelle architecture de données pour chaque nouveau domaine, mais cela créerait des limites strictes et une complexité supplémentaire. Bien que cela soit parfois nécessaire, s'il y a un choix à faire, il vaut mieux éviter d'ajouter de la complexité. Par conséquent, une approche plus moderne consiste à intégrer la flexibilité et le choix dans votre architecture avec une épine dorsale d'intégration qui peut évoluer horizontalement (axe X) en ajoutant des nœuds de calcul supplémentaires, verticalement (axe Y) en augmentant la taille d'un nœud de calcul, ou largement (axe Z) en ajoutant des domaines supplémentaires (figure 1). Tous les domaines seraient faiblement couplés au sein du même environnement d'intégration.
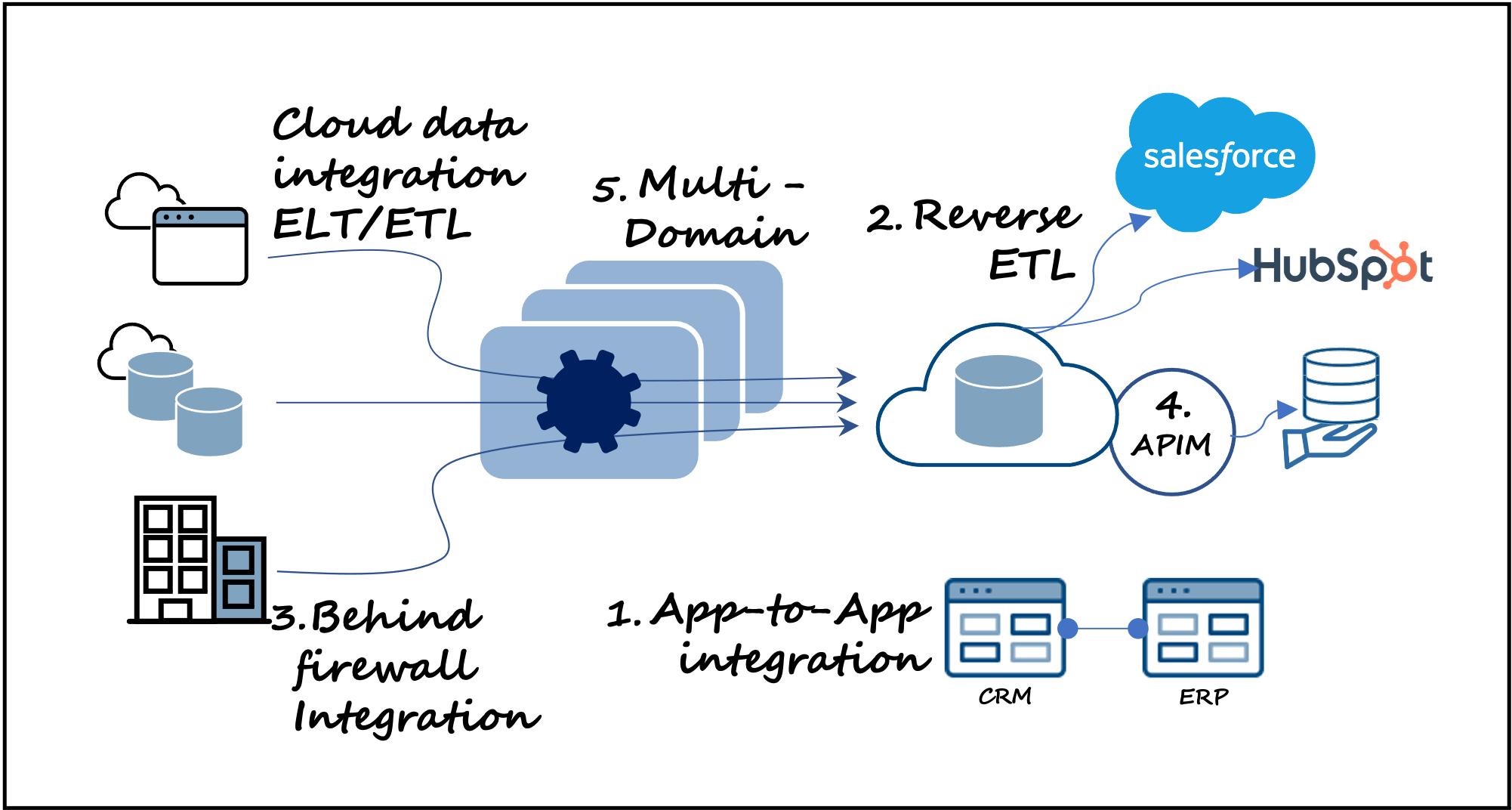
En outre, chaque domaine disposerait de ses propres ressources, tandis que le contrôle et la gestion de l'ensemble de l'environnement intégré pourraient être détenus et gérés par les groupes d'entreprises ou par les services informatiques. La flexibilité est la clé, car les entreprises placent de plus en plus de technologues de type informatique au sein des groupes d'affaires. Pour un tel environnement distribué, il serait également idéal de collecter des métadonnées d'activité dans l'ensemble de l'environnement afin de favoriser la gouvernance et d'appliquer des politiques de sécurité. Les métadonnées et la gouvernance constituent un sujet à part entière qui fera l'objet d'un prochain article. Restez à l'écoute.
Plus moderne + moins complexe = une vie plus simple avec les données
Dans cette série d'articles en deux parties, j'ai résumé comment l'intégration des données (sources de données consolidées dans un entrepôt de données cloud ) tend à être au centre de la plupart des discussions sur l'architecture de données moderne et la pile de données moderne. Pourtant, lorsque j'ai le privilège de m'entretenir avec des responsables des technologies de l'information et des groupes d'affaires, des architectes d'entreprise et des gestionnaires de données plateforme , une préoccupation commune est souvent exprimée : les architectures de données sont trop complexes et trop techniques pour permettre aux personnes extérieures à l'informatique d'intégrer les données et de travailler avec elles.
L'un des principaux facteurs est la présence d'outils multiples qui se chevauchent pour accomplir des tâches plus larges liées aux données, ce qui compense les outils qui ne sont axés que sur l'ELT ou l'ETL, ou encore sur l'ETL inversé.
L'intégration des données (ELT, ETL et ETL inverse), l'intégration d'application à application et la gestion du cycle de vie complet des API, lorsqu'elles sont consolidées au sein d'une intégration unique plateforme, rendront votre architecture de données globale plus moderne (et plus fonctionnelle), mais aussi moins complexe et plus simple pour un plus grand nombre de propriétaires et d'utilisateurs de données. Cela inclut les utilisateurs en dehors du service informatique. En prime, une telle solution consolidée et unifiée vous permet également de séparer le contrôle cloud de l'exécution sur site (derrière un pare-feu) et vous permet d'évoluer verticalement, horizontalement ou largement pour répondre aux exigences de performance et pour ajouter des domaines.




