





 Par Sharath Punreddy
Par Sharath Punreddy
Comme vous le savez probablement, les pipelines de données SnapLogic utilisent des flux, un flux continu de données d‘une source à une cible. En traitant et en extrayant des informations précieuses des données en continu, un utilisateur/système peut prendre des décisions plus rapidement qu‘avec un traitement par lots traditionnel. L‘analyse des données en continu permet désormais de réaliser des analyses en temps quasi réel, voire en temps réel, y compris l‘analyse de l‘API en continu de Twitter.
À l‘ère des données, la rapidité de l‘analyse et de la compréhension des données est devenue un facteur clé de différenciation. Dans certains cas, les données deviennent moins pertinentes - voire obsolètes - au fur et à mesure qu‘elles vieillissent. L‘analyse des données au fur et à mesure de leur arrivée est cruciale pour des cas d‘utilisation tels que l‘analyse sentimentale pour le lancement de nouveaux produits dans le commerce de détail, la détection des transactions frauduleuses dans le secteur financier, la prévention des pannes de machines dans la fabrication, le traitement des données des capteurs pour les prévisions météorologiques, les épidémies dans le secteur des soins de santé, etc. Le traitement des flux permet un traitement en temps quasi réel, voire en temps réel, ce qui permet à l‘utilisateur ou au système de tirer des enseignements des données les plus récentes. Outre les API traditionnelles, les entreprises fournissent des API de flux pour rendre les données en temps réel, au fur et à mesure qu‘elles sont générées. Contrairement aux API ReST/SOAP traditionnelles, les API de diffusion en continu établissent une connexion avec le serveur et diffusent les données en continu pendant la durée souhaitée. Une fois le temps écoulé, la connexion est interrompue. Apache Spark avec Apache Kafka en tant que Streaming plateforme est devenu un standard industriel de facto pour le traitement des flux.
Dans cet article de blog, je vais vous présenter les étapes de la construction d‘un pipeline simple pour récupérer et traiter les analyses de Twitter streamingAPI. Vous pouvez également accéder à la vidéo de démonstration ici.
Flux Twitter
Twitter est devenu une source de données essentielle pour l‘analyse des sentiments. Les API de streaming de Twitter permettent d‘accéder aux tweets globaux et peuvent être consultées en temps réel au moment où les gens tweetent. Le Snap "Twitter Streaming Query" de Snaplogic permet aux utilisateurs de récupérer des Tweets sur la base d‘un mot clé dans le texte du Tweet. Les Tweets peuvent ensuite être traités à l‘aide de Snap tels que Filter Snap, Mapper Snap ou Aggregate Snap, respectivement pour le filtrage, la transformation et l‘agrégation. SnapLogic propose également un Snap "Spark Script" qui permet d‘exécuter un programme Python existant sur les Tweets entrants. Avec l‘analyse de l‘API de streaming de Twitter, les tweets peuvent également être acheminés vers différentes destinations en fonction d‘une condition, copiés vers plusieurs destinations (RDBMS, HDFS, S3, etc.) pour être stockés et faire l‘objet d‘une analyse plus poussée.
Mise en route
Vous trouverez ci-dessous un pipeline simple pour récupérer les Tweets, les filtrer en fonction de la langue et les publier sur un cluster Kafka.
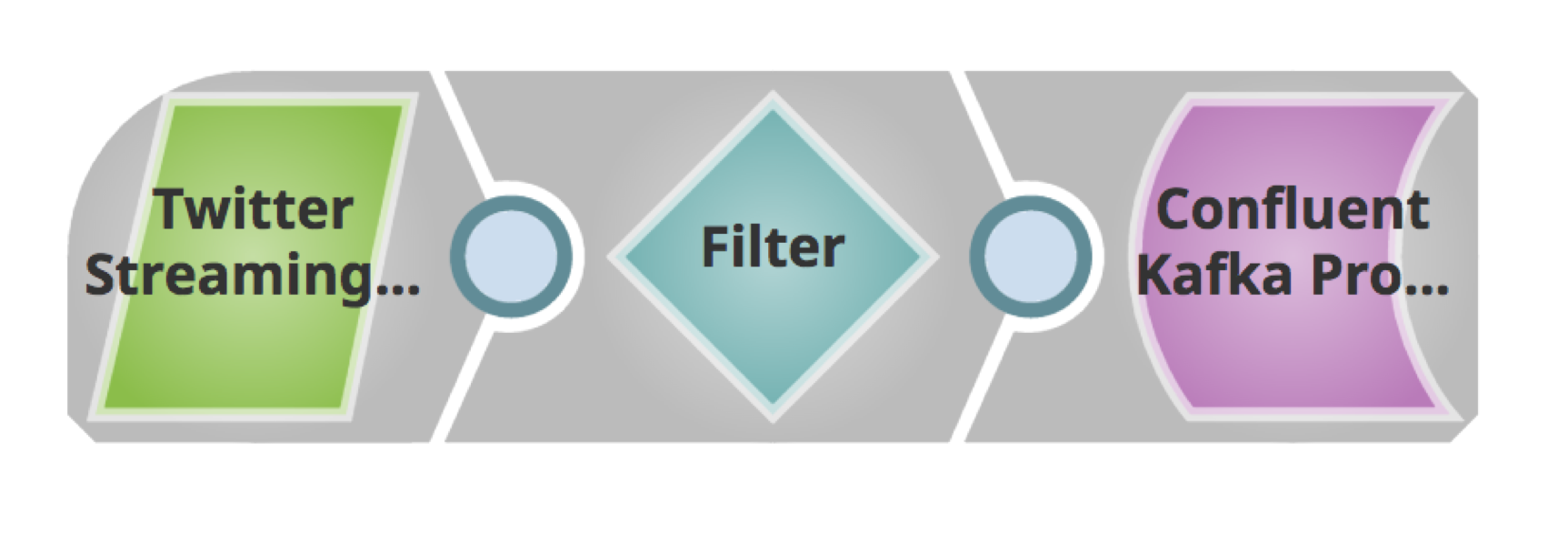 En utilisant l‘onglet Snap dans le cadre de gauche, recherchez le Snap. Faites glisser et déposez l‘instantané sur le canevas du Designer (espace blanc à droite).
En utilisant l‘onglet Snap dans le cadre de gauche, recherchez le Snap. Faites glisser et déposez l‘instantané sur le canevas du Designer (espace blanc à droite).
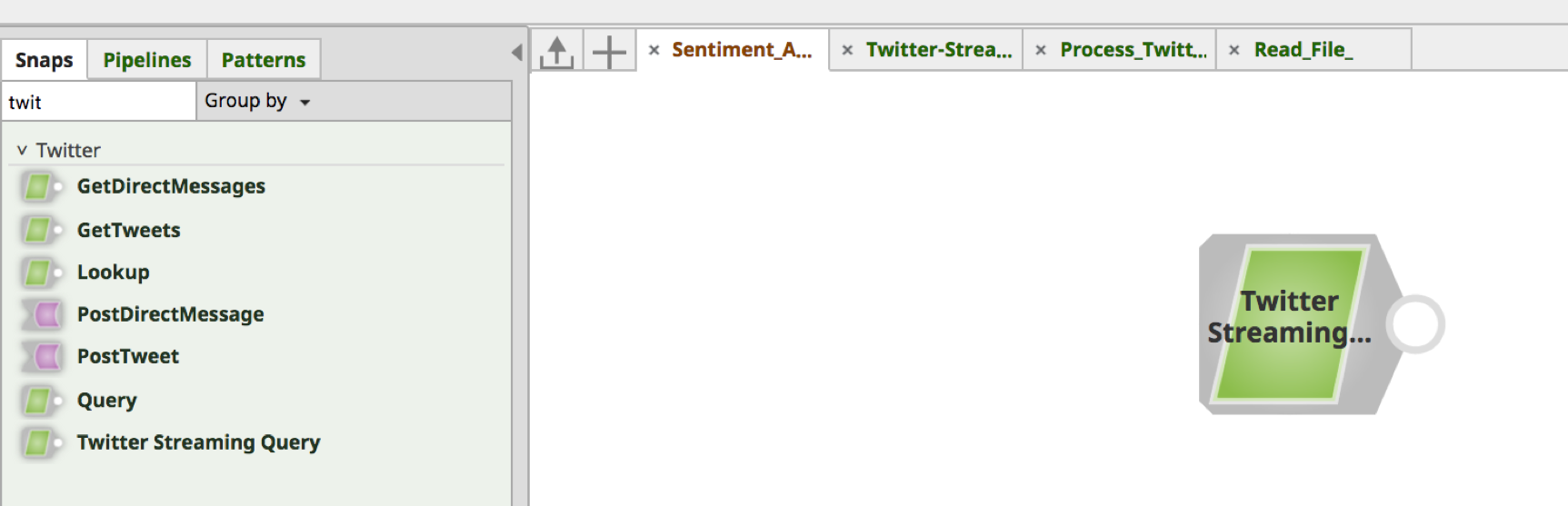 a. Cliquez sur l‘image pour ouvrir le formulaire Snap Settings (Paramètres de l‘image).
a. Cliquez sur l‘image pour ouvrir le formulaire Snap Settings (Paramètres de l‘image).
 Remarque : Le Snap "Twitter Streaming Query", et donc l‘analyse de l‘API de streaming Twitter, nécessite un compte Twitter, qui peut être créé dans le Designer pendant la construction du pipeline ou à l‘aide du Manager avant la construction du pipeline.
Remarque : Le Snap "Twitter Streaming Query", et donc l‘analyse de l‘API de streaming Twitter, nécessite un compte Twitter, qui peut être créé dans le Designer pendant la construction du pipeline ou à l‘aide du Manager avant la construction du pipeline.
b. Cliquez sur l‘onglet "Compte".
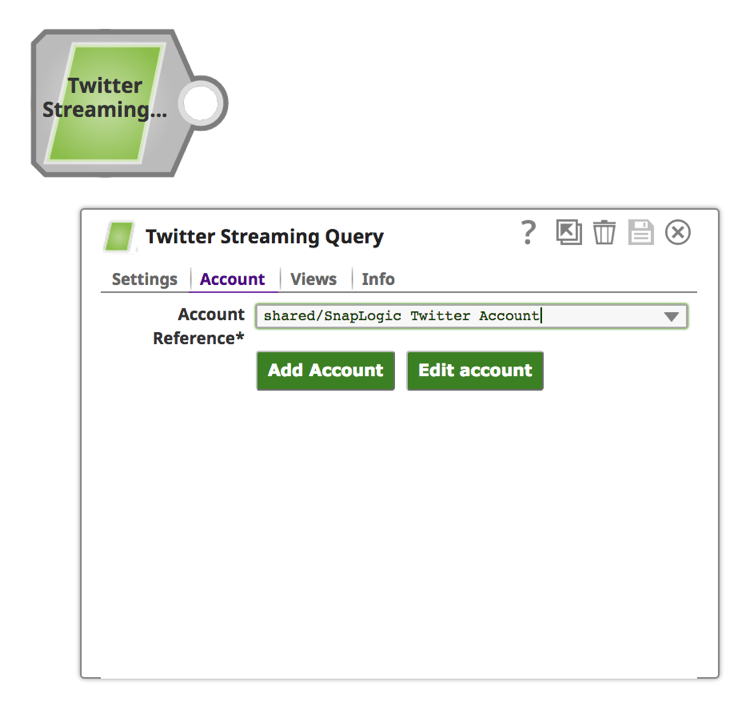 c. Cliquez sur le bouton "Ajouter un compte".
c. Cliquez sur le bouton "Ajouter un compte".
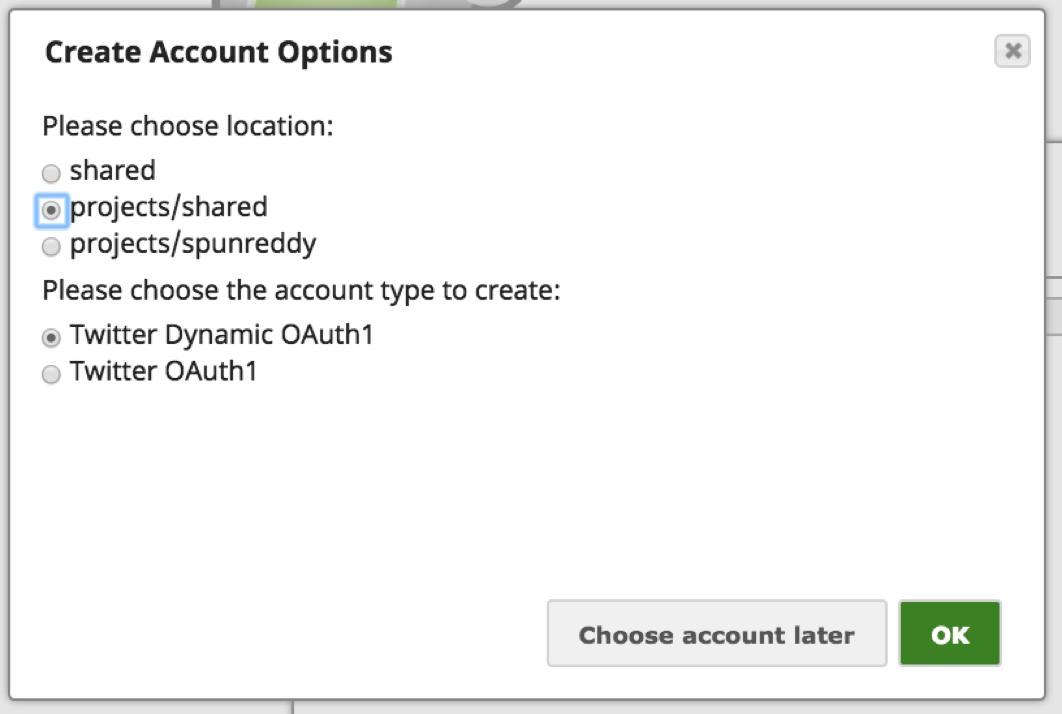 Remarque : Twitter propose quelques les moyens d‘authentification au compte Twitter. Le "Twitter Dynamic OAuth1" est destiné à Authentification par application seulement et "Twitter OAuth1" est pour Authentification de l‘utilisateur où l‘utilisateur doit authentifier l‘application en se connectant à Twitter. Dans ce cas, nous utilisons le mécanisme d‘authentification de l‘utilisateur.
Remarque : Twitter propose quelques les moyens d‘authentification au compte Twitter. Le "Twitter Dynamic OAuth1" est destiné à Authentification par application seulement et "Twitter OAuth1" est pour Authentification de l‘utilisateur où l‘utilisateur doit authentifier l‘application en se connectant à Twitter. Dans ce cas, nous utilisons le mécanisme d‘authentification de l‘utilisateur.
d. Choisissez une option appropriée en fonction de l‘accessibilité du compte :
i. Pour l‘emplacement du compte : Partagé rend ce compte accessible à l‘ensemble de l‘organisation, "projets/partagé" rendrait le compte accessible à tous les utilisateurs du projet, et "projet/" rendrait le compte accessible uniquement à l‘utilisateur.
ii. Pour le type de compte : Choisissez l‘option "Twitter OAuth1" pour accorder l‘accès au compte Twitter de l‘utilisateur individuel.
iii. Cliquez sur "OK".
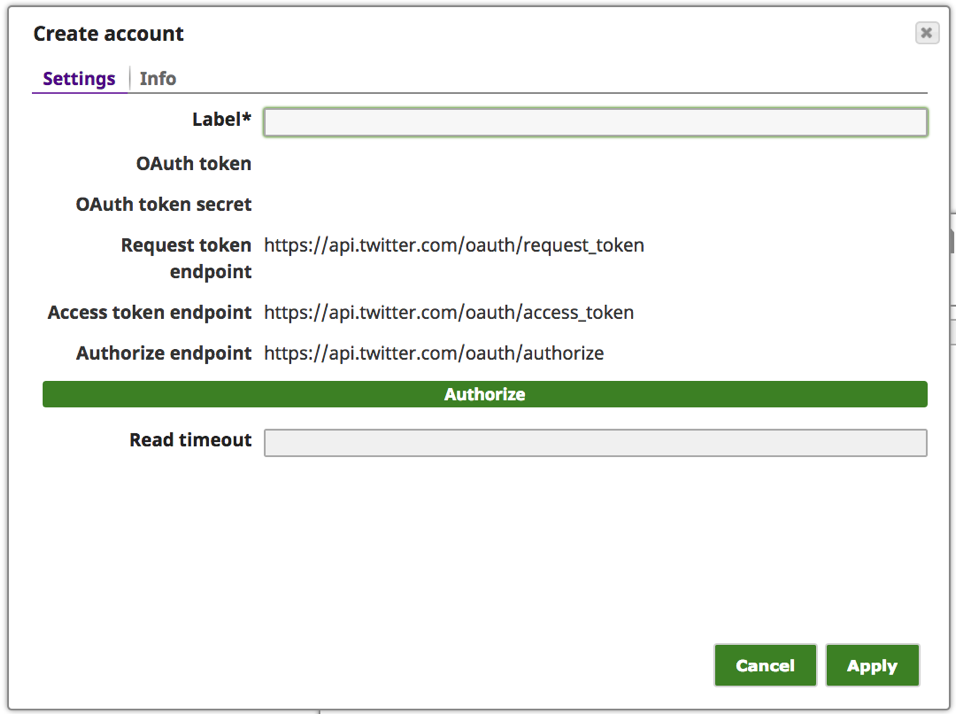 e. Saisissez un texte significatif pour l‘"étiquette", par exemple [Twitter_of_], et cliquez sur le bouton "Autoriser".
e. Saisissez un texte significatif pour l‘"étiquette", par exemple [Twitter_of_], et cliquez sur le bouton "Autoriser".
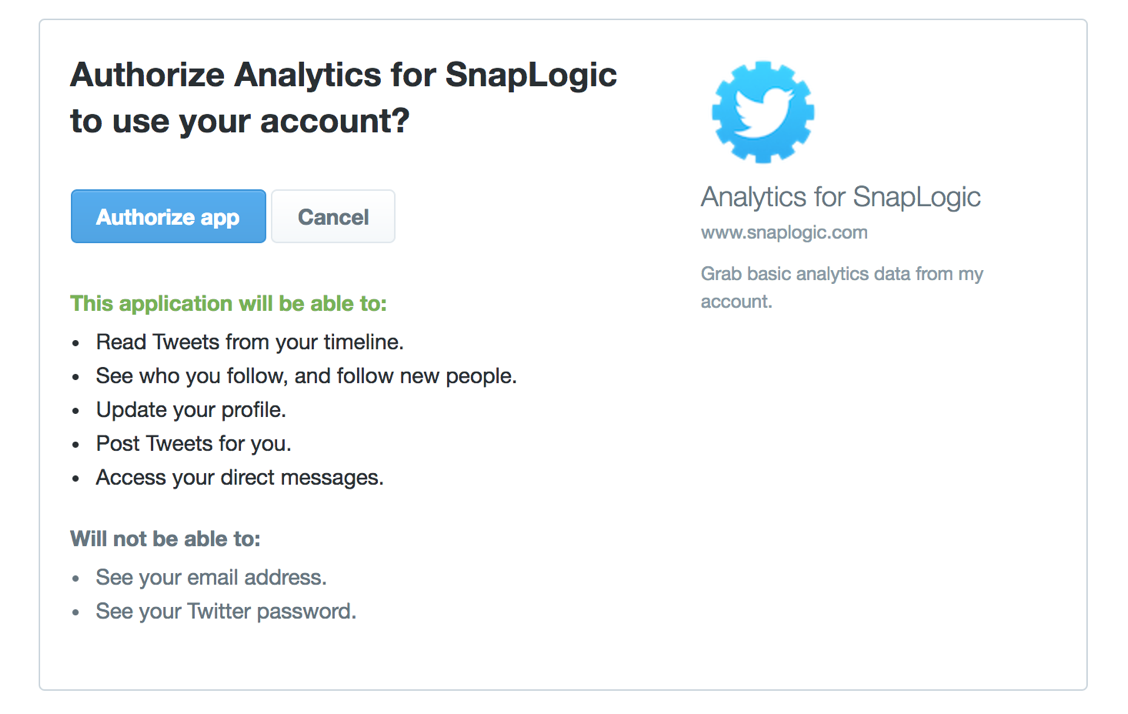 Remarque : Si un utilisateur est connecté à Twitter avec une session active, il sera dirigé vers la page "Autoriser" du site web de Twitter pour que l‘utilisateur accorde l‘accès à l‘application. Si l‘utilisateur n‘est pas connecté ou n‘a pas de session active, il sera dirigé vers la page de connexion de Twitter pour qu‘il s‘identifie.
Remarque : Si un utilisateur est connecté à Twitter avec une session active, il sera dirigé vers la page "Autoriser" du site web de Twitter pour que l‘utilisateur accorde l‘accès à l‘application. Si l‘utilisateur n‘est pas connecté ou n‘a pas de session active, il sera dirigé vers la page de connexion de Twitter pour qu‘il s‘identifie.
f. Cliquez sur le bouton "Autoriser l‘application".
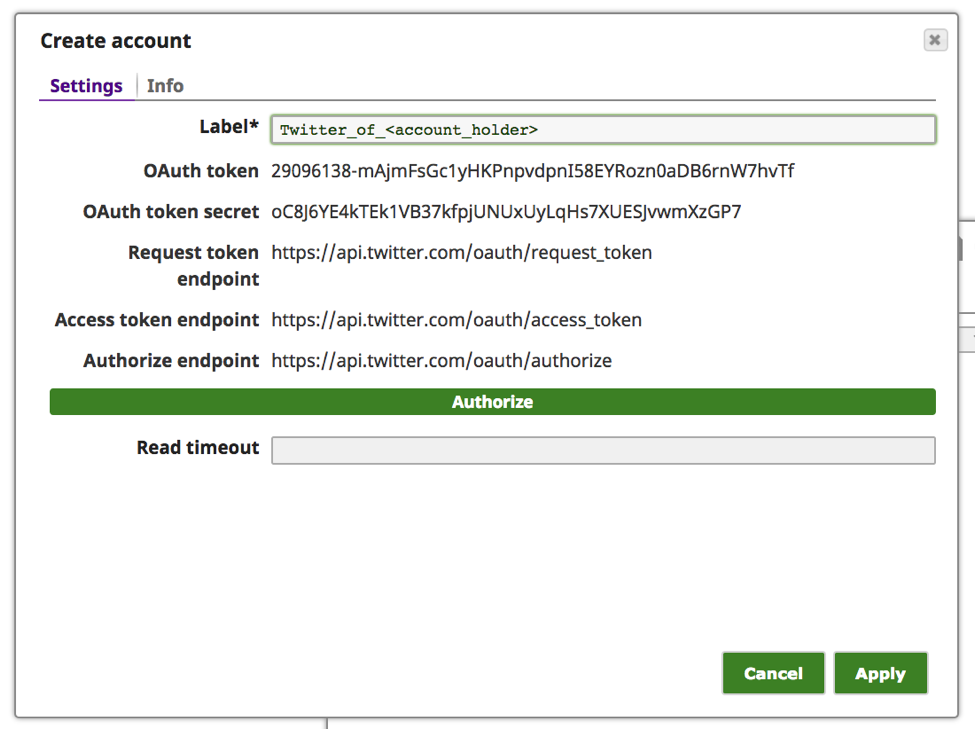 Remarque : Les valeurs "OAuth token" et "OAuth token secret" ci-dessus ne sont pas actives et ne sont données qu‘à titre d‘exemple.
Remarque : Les valeurs "OAuth token" et "OAuth token secret" ci-dessus ne sont pas actives et ne sont données qu‘à titre d‘exemple.
g. À ce stade, le "jeton OAuth" et le "secret du jeton OAuth" doivent avoir été renseignés. Cliquez sur "Apply".
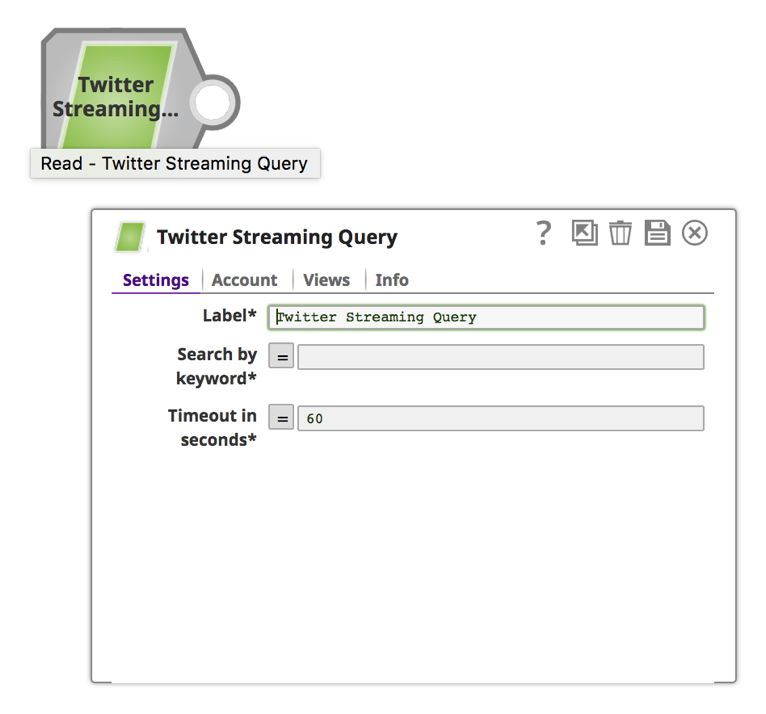
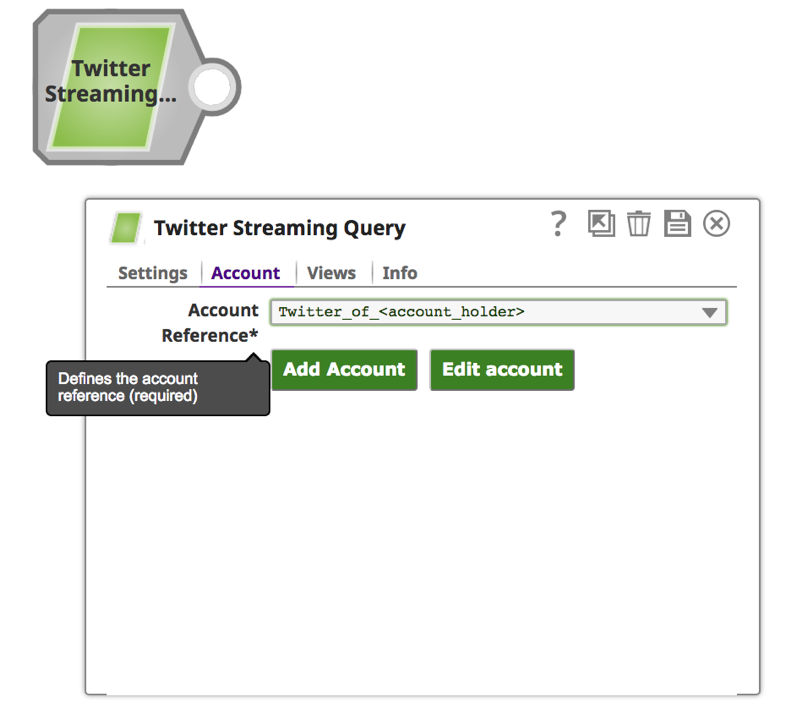 2. Une fois le compte configuré avec succès, cliquez sur l‘onglet "paramètres" pour indiquer le mot-clé et l‘heure de la recherche.
2. Une fois le compte configuré avec succès, cliquez sur l‘onglet "paramètres" pour indiquer le mot-clé et l‘heure de la recherche.
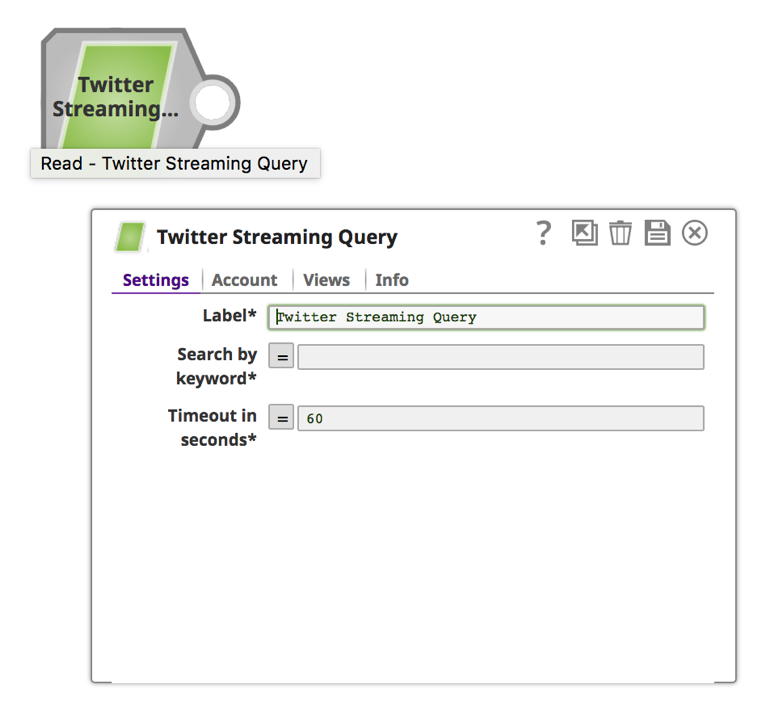 Remarque : L‘instantané Twitter récupérera les Tweets pendant une durée déterminée. Pour une récupération continue, vous pouvez donner une valeur de "0" au "Délai d‘attente en secondes".
Remarque : L‘instantané Twitter récupérera les Tweets pendant une durée déterminée. Pour une récupération continue, vous pouvez donner une valeur de "0" au "Délai d‘attente en secondes".
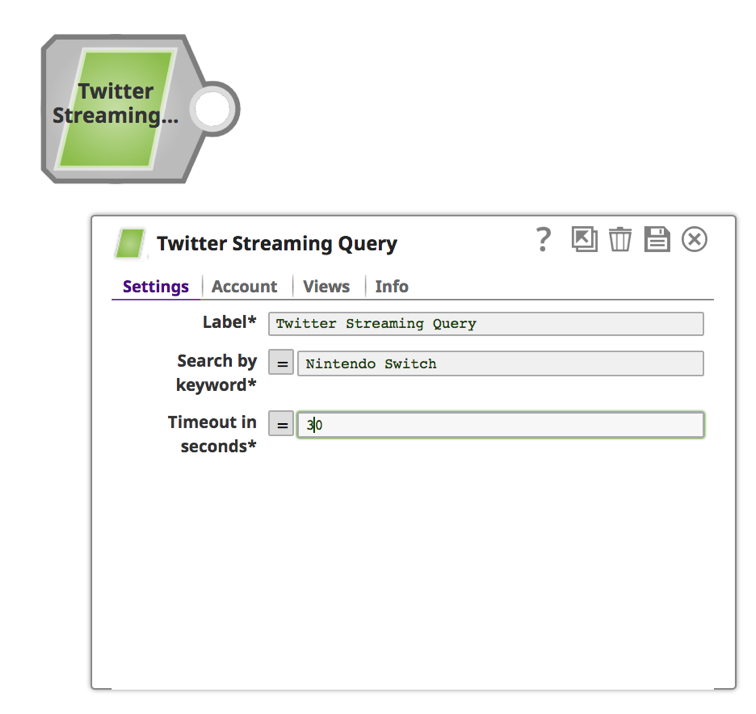
a. Saisissez un mot-clé et une durée en secondes.
3. Sauvegarder en cliquant sur l‘icône de la disquette en haut à droite. ![]() . Cela déclenchera la validation et devrait se transformer en une coche.
. Cela déclenchera la validation et devrait se transformer en une coche. ![]() si la validation est réussie.
si la validation est réussie.
4. Cliquez sur la liste ![]() pour prévisualiser les données.
pour prévisualiser les données.
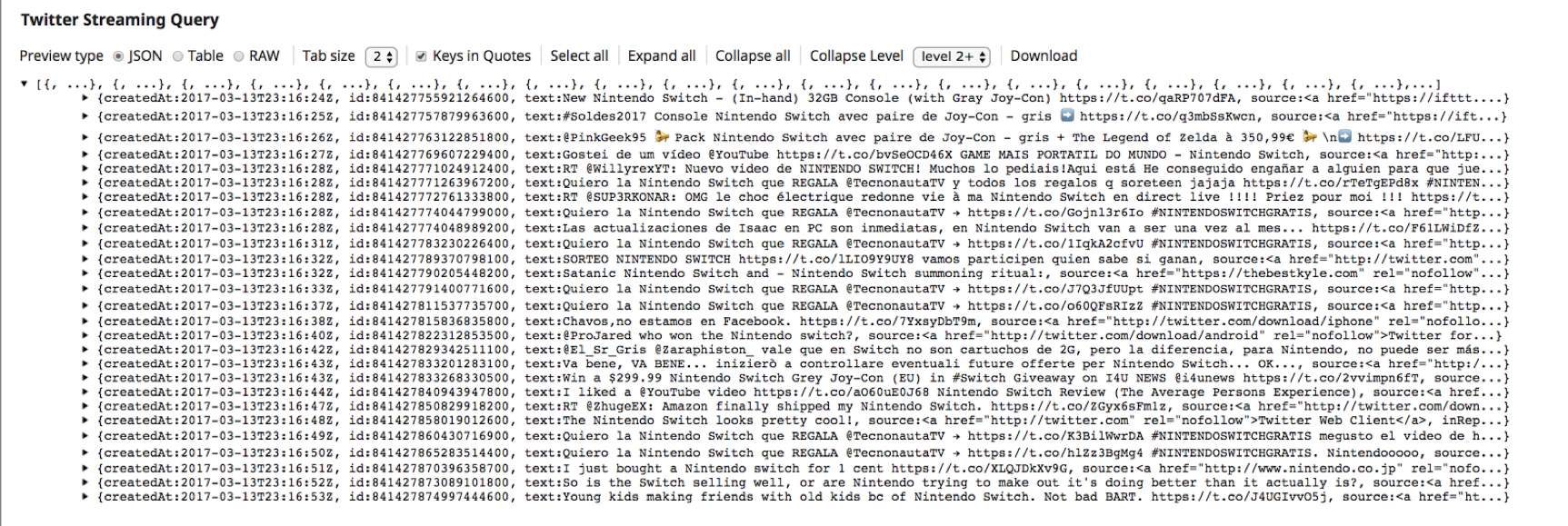 5. Cela confirme que le Snap "Twitter Streaming Query" a réussi à établir une connexion avec le compte Twitter et qu‘il récupère les Tweets.
5. Cela confirme que le Snap "Twitter Streaming Query" a réussi à établir une connexion avec le compte Twitter et qu‘il récupère les Tweets.
6. L‘instantané "Filtre" est utilisé pour filtrer les Tweets. Recherchez "Filter" à l‘aide de l‘onglet Snaps dans le cadre de gauche. Faites glisser et déposez l‘image instantanée "Filtre" sur le canevas.
 a. Cliquez sur l‘icône "Filtre" pour ouvrir le formulaire des paramètres.
a. Cliquez sur l‘icône "Filtre" pour ouvrir le formulaire des paramètres.
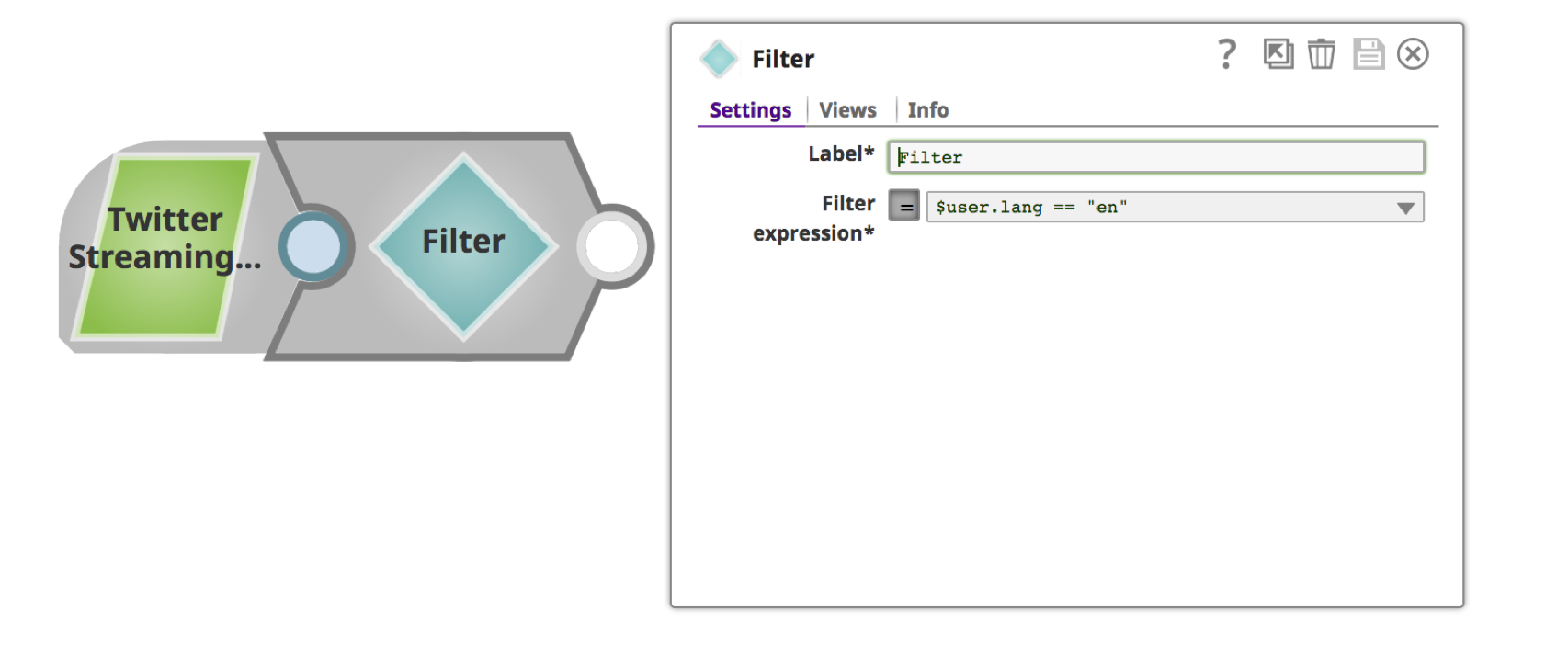 b. Donnez un nom significatif tel que "Filtrer par langue" pour l‘"étiquette" et la condition de filtrage pour l‘"expression de filtrage". Vous pouvez utiliser la liste déroulante pour choisir l‘attribut de filtre.
b. Donnez un nom significatif tel que "Filtrer par langue" pour l‘"étiquette" et la condition de filtrage pour l‘"expression de filtrage". Vous pouvez utiliser la liste déroulante pour choisir l‘attribut de filtre.
7. Cliquer sur l‘icône du disque ![]() pour l‘enregistrer, ce qui déclenche à nouveau la validation. Vous avez maintenant terminé avec succès un Snap "Filtre".
pour l‘enregistrer, ce qui déclenche à nouveau la validation. Vous avez maintenant terminé avec succès un Snap "Filtre".
8. Recherchez le Snap "Confluent Kafka Producer" à l‘aide de l‘onglet Snaps dans le cadre de gauche. Glissez-déposez le Snap sur le canevas.
 Remarque : Confluent est une distribution Apache Kafka destinée aux entreprises.
Remarque : Confluent est une distribution Apache Kafka destinée aux entreprises.
a. Le "Confluent Kafka Producer" nécessite un compte pour se connecter au cluster Kafka. Choisissez les valeurs appropriées en fonction de l‘emplacement et du type de compte.
 b. Fournissez un texte significatif pour l‘"étiquette" du ou des serveurs d‘amorçage. En cas de serveurs d‘amorçage multiples, utilisez une virgule pour les séparer, ainsi que le port.
b. Fournissez un texte significatif pour l‘"étiquette" du ou des serveurs d‘amorçage. En cas de serveurs d‘amorçage multiples, utilisez une virgule pour les séparer, ainsi que le port.
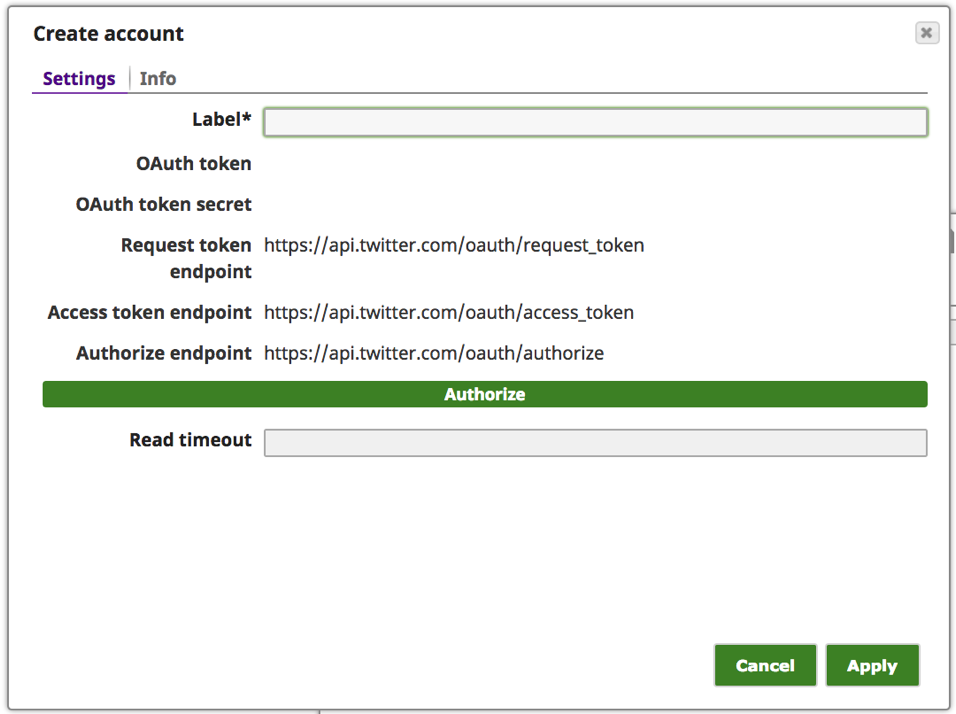 c. L‘"URL du registre des schémas" est facultative, mais elle est nécessaire au cas où Kafka devrait analyser le message sur la base du schéma.
c. L‘"URL du registre des schémas" est facultative, mais elle est nécessaire au cas où Kafka devrait analyser le message sur la base du schéma.
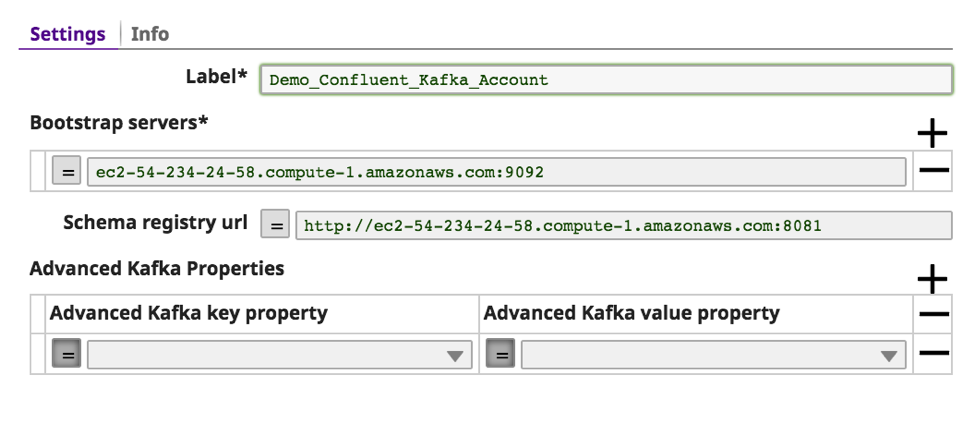 d. Les autres propriétés optionnelles du Kafka peuvent être transmises au Kafka en utilisant les "Propriétés avancées du Kafka". Cliquez sur "valider".
d. Les autres propriétés optionnelles du Kafka peuvent être transmises au Kafka en utilisant les "Propriétés avancées du Kafka". Cliquez sur "valider".
e. Si la validation est réussie, vous devriez voir apparaître un message en haut de page comme "Validation du compte réussie". Cliquez sur "Appliquer".
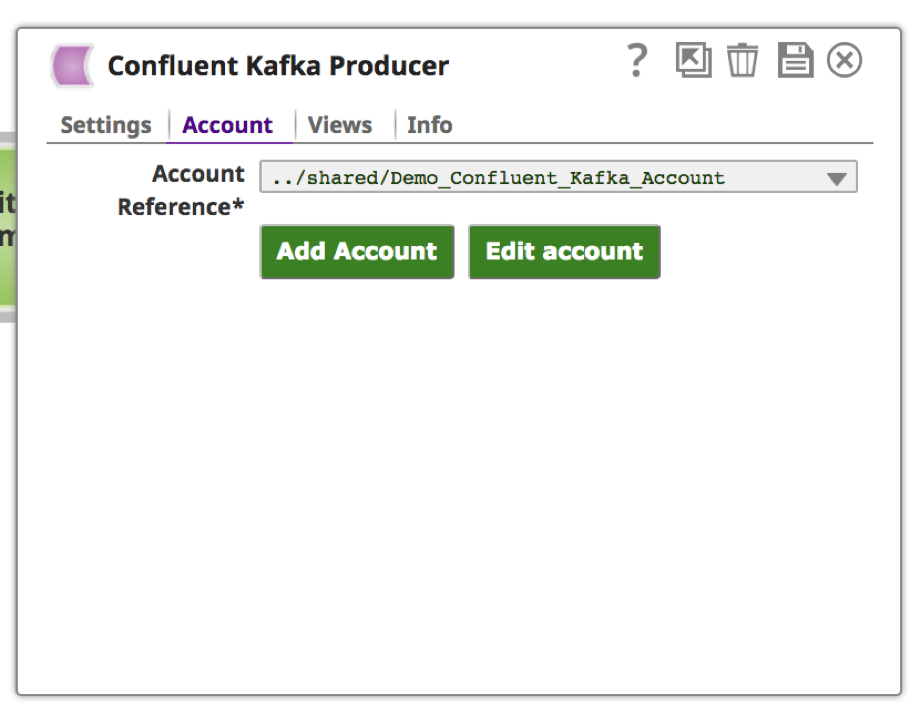 9. Une fois le compte configuré et choisi, cliquez sur l‘onglet "Settings" pour indiquer le sujet et le message Kafka.
9. Une fois le compte configuré et choisi, cliquez sur l‘onglet "Settings" pour indiquer le sujet et le message Kafka.
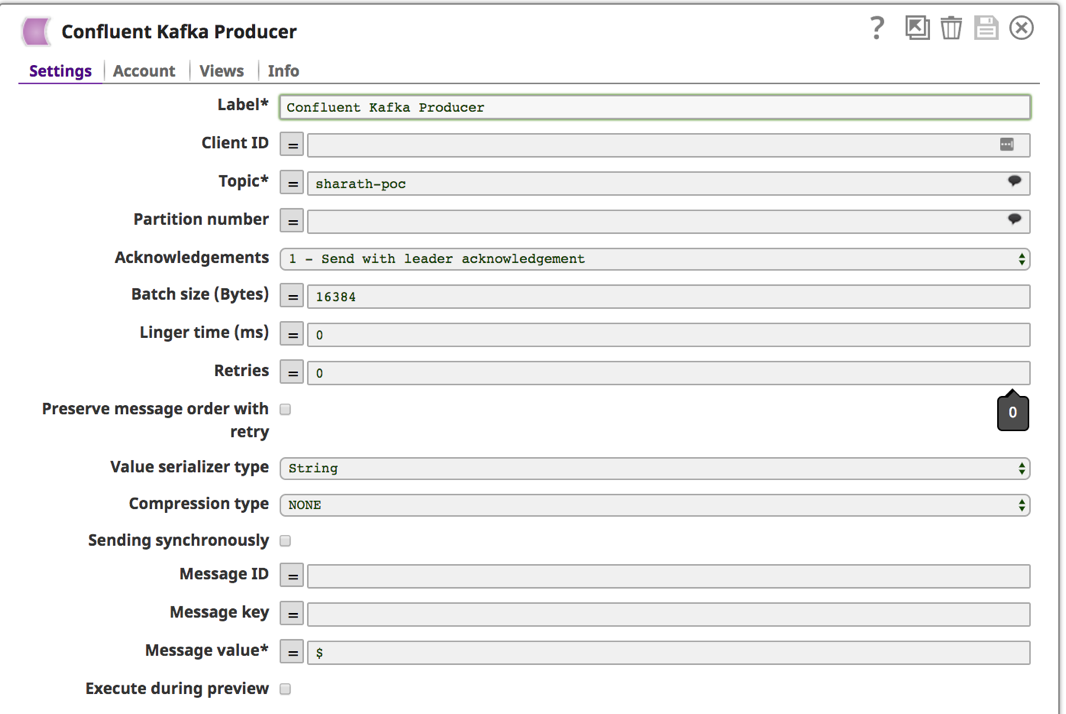
a. Vous pouvez choisir dans la liste des sujets disponibles en cliquant sur l‘icône en forme de bulle ![]() à côté du champ "Sujet". Laissez les autres champs par défaut. Un autre champ obligatoire est celui de la "Valeur du message". Saisissez "$" pour envoyer l‘intégralité du Tweet et des métadonnées. Sauvegardez en cliquant sur l‘icône de la disquette
à côté du champ "Sujet". Laissez les autres champs par défaut. Un autre champ obligatoire est celui de la "Valeur du message". Saisissez "$" pour envoyer l‘intégralité du Tweet et des métadonnées. Sauvegardez en cliquant sur l‘icône de la disquette ![]() .
.
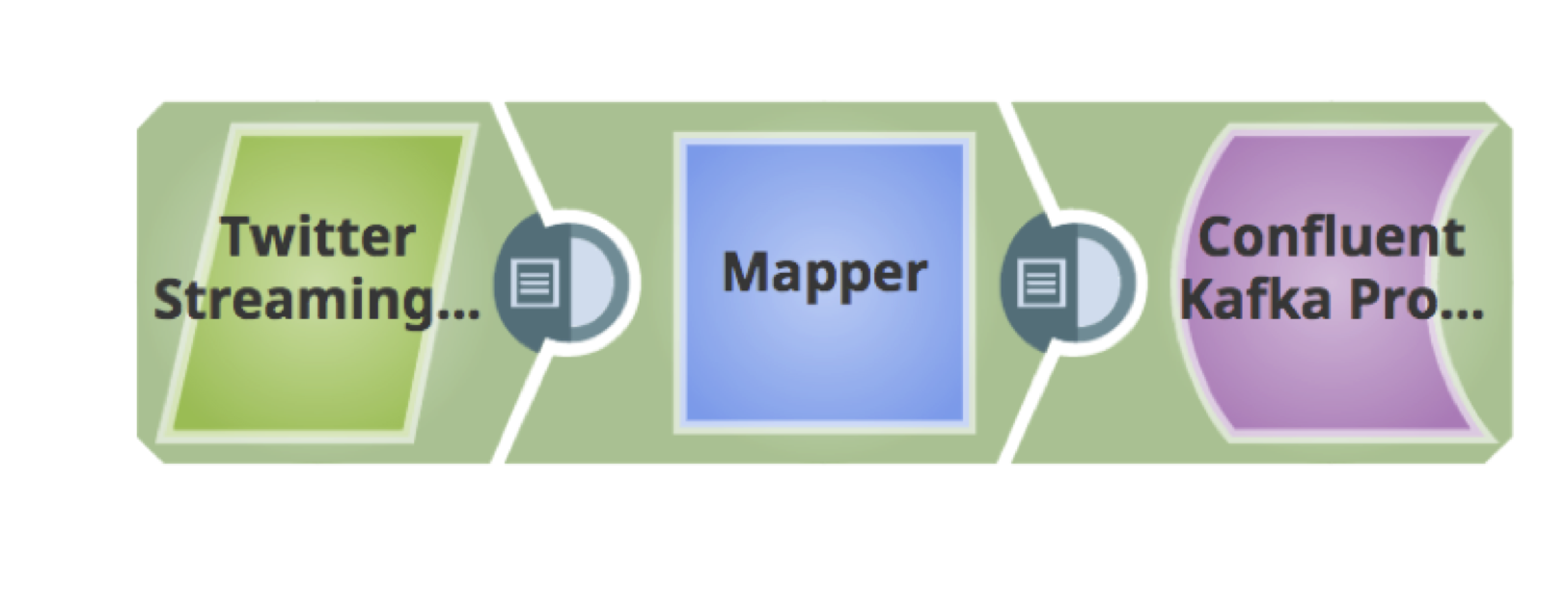 10. Ce qui précède est un pipeline entièrement validé pour récupérer les tweets et les charger dans Kafka.
10. Ce qui précède est un pipeline entièrement validé pour récupérer les tweets et les charger dans Kafka.
11. À ce stade, le pipeline est prêt à recevoir les Tweets et à les envoyer dans Kafka Topic. Exécutez le pipeline en cliquant sur le bouton "play" dans le coin supérieur droit. ![]() . Visualisez la progression en cliquant sur le bouton d‘affichage
. Visualisez la progression en cliquant sur le bouton d‘affichage ![]() .
.
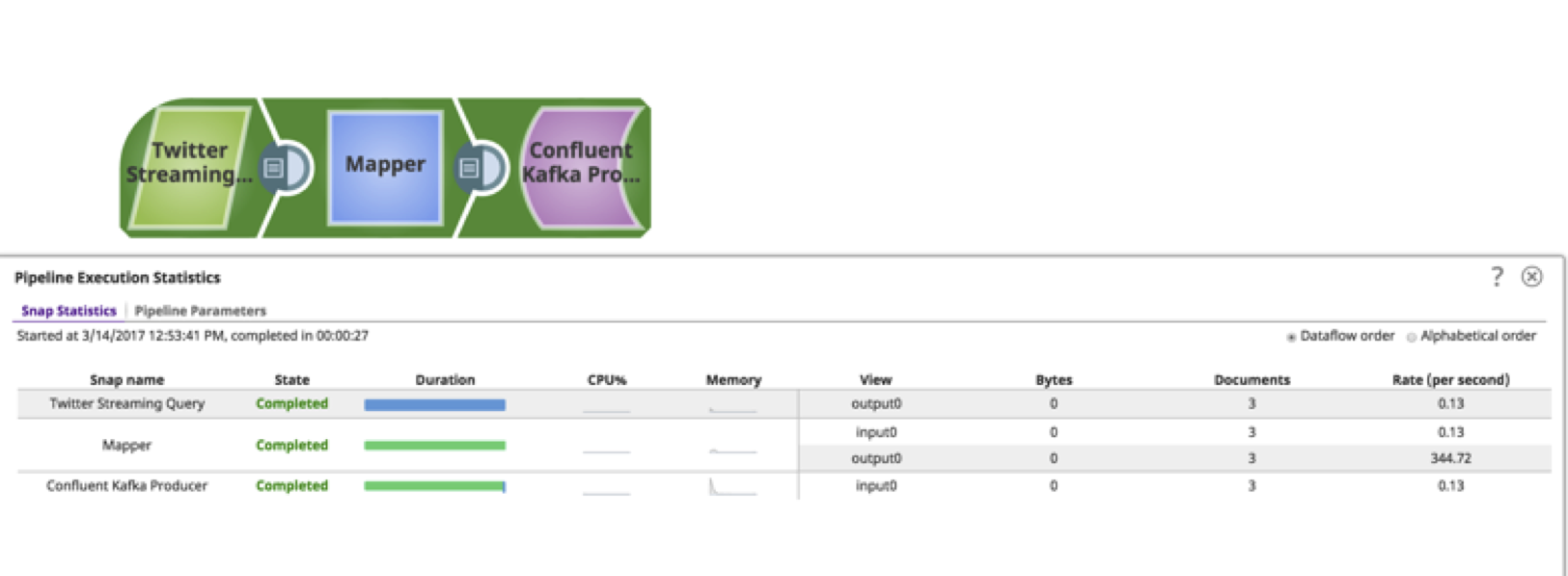 Comme vous pouvez le constater, le pipeline peut être construit en moins de 15 minutes sans nécessiter de connaissances techniques approfondies. Ce tutoriel et vidéo fournit un exemple de base de ce qu‘il est possible de faire en utilisant ces snaps. Plusieurs autres snaps peuvent agir sur les données, comme le filtrage, la copie, l‘agrégation, le déclenchement d‘événements, l‘envoi de courriels, etc. autres. Snaplogic est fier d‘apporter une technologie complexe à l‘intégrateur citoyen. J‘espère que vous avez trouvé cela utile !
Comme vous pouvez le constater, le pipeline peut être construit en moins de 15 minutes sans nécessiter de connaissances techniques approfondies. Ce tutoriel et vidéo fournit un exemple de base de ce qu‘il est possible de faire en utilisant ces snaps. Plusieurs autres snaps peuvent agir sur les données, comme le filtrage, la copie, l‘agrégation, le déclenchement d‘événements, l‘envoi de courriels, etc. autres. Snaplogic est fier d‘apporter une technologie complexe à l‘intégrateur citoyen. J‘espère que vous avez trouvé cela utile !
Sharath Punreddy est architecte de solutions d‘entreprise chez SnapLogic. Suivez-le sur Twitter @srpunreddy.





{kind=link}