





Dans le dernier billet nous sommes entrés dans les détails des détecteurs d'anomalies et avons montré comment certains modèles simples pouvaient fonctionner. Nous allons maintenant construire un pipeline de détection d'anomalies en continu.
Nous allons utiliser un pipeline déclenché pour cette tâche. Un pipeline déclenché est instancié à chaque fois qu'une requête arrive. L'instanciation peut prendre quelques secondes, il n'est donc pas recommandé pour les situations de faible latence ou de fort trafic. Si nous recevons des données plus fréquemment que cela, ou si nous voulons moins de latence, nous devrions utiliser un pipeline Ultra. Un pipeline Ultra reste en cours d'exécution, de sorte que le temps de latence entre les entrées et les sorties est nettement inférieur.
Pour les besoins de ce billet, nous allons supposer que nous disposons d'un Snap Anomaly-Detector-as-a-Service. Dans le prochain article, nous verrons comment créer cette application à l'aide d'Azure ML. Notre pipeline se présentera comme suit :
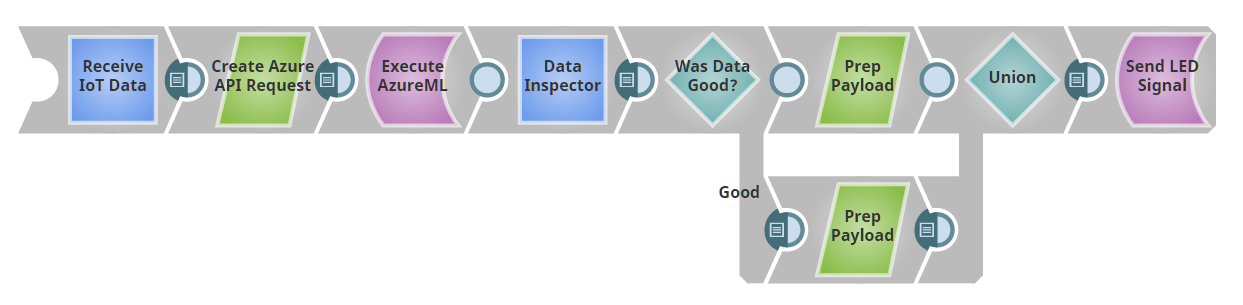
Notre premier Snap sert de point de terminaison REST, c'est-à-dire que le pipeline fournit un serveur web. Si vous envoyez un message avec une charge utile JSON à l'URL fournie, la sortie de ce Snap sera le JSON envoyé en tant que document. (En fait, nous utilisons ici un Snap Record Replay pour mettre en cache les données d'entrée, de sorte qu'une fois que nous avons envoyé une entrée au pipeline, nous l'avons stockée pour la réutiliser au fur et à mesure que nous développons sans avoir besoin de POSTER sans cesse de nouvelles données).
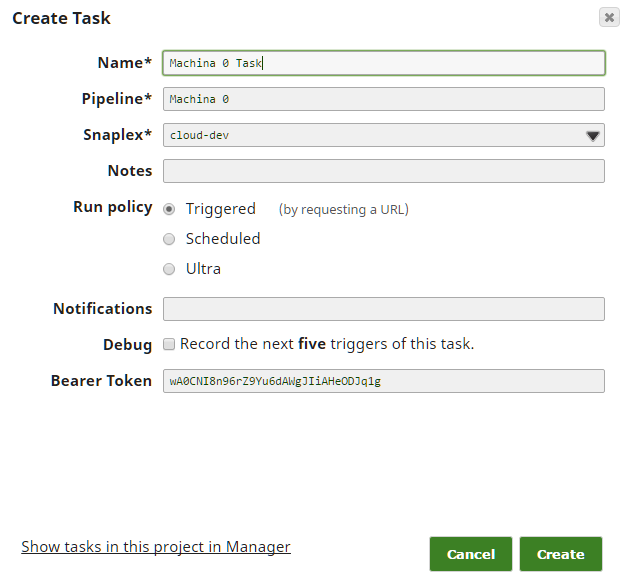
Si vous vous suivez dans SnapLogicvous remarquerez que le Snap Record Replay n'a pas d'entrée comme le montre l'image. Pour l'ajouter, cliquez sur le Snap, cliquez sur "Views", puis cliquez sur le signe plus "+" à côté de input pour ajouter une entrée. Ensuite, avant d'oublier, configurons la Tâche déclenchée pour que nous puissions POST à ce pipeline. Cliquez sur le bouton "Create task" (Créer une tâche), indiqué en vert ci-dessous.

Ensuite, remplissez les champs - dans la plupart des cas, les valeurs par défaut devraient fonctionner ; assurez-vous simplement que vous avez sélectionné la "Politique d'exécution" de "Déclenché".
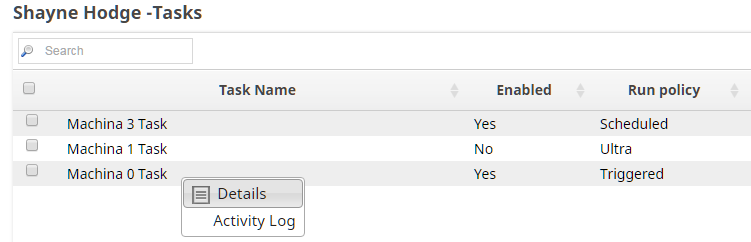
Finally, we need to take a quick detour to Manager to get the URL and Authorization Token for this Task. Drill down on the side navigation pane to Projects -> <Your Project> -> Tasks. In the right hand task pane, click the dropdown arrow and then Details. You’ll be taken to the page with the URL and token you need, as well as a Task Status log. You’ll want to come back here if things seem not to be working right to see if there are failures in the execution of the pipeline.
Vous pouvez maintenant prendre cette URL et ce jeton d'authentification et les donner à l'application ou à l'appareil qui doit vous envoyer des données. Pour ce projet, nous avons créé un script Python qui génère aléatoirement des données (au format JSON) et les envoie au pipeline. En général, il est plus facile d'utiliser des "stubs" comme celui-ci et de passer à la source réelle lorsque vous savez que tout le reste est correctement configuré.
Nous introduisons les données entrantes de notre point d'accès REST dans notre détecteur d'anomalies en boîte noire. Le détecteur renvoie un jugement sur chaque point, qu'il soit "bon" ou "mauvais". Nous disposons d'un routeur Snap qui envoie les bons et les mauvais points vers des chemins de traitement différents. Si vous avez suivi la série IoTvous avez vu que nous avons construit un pipeline qui fait clignoter une LED d'une couleur différente en fonction de la charge utile qui lui est envoyée. Ici, nous avons réutilisé cette lumière, en transformant le "bon" en une charge utile "color : 'green" et le mauvais en une charge utile "color : 'red", et nous l'avons renvoyée à la lumière.
Nous pourrions simplement enregistrer les points anormaux dans une base de données, déclencher un service tel que PagerDuty, ou publier une annonce dans un canal Slack. (Ou nous pourrions faire tout cela, ou choisir différents canaux de notification en fonction de la date et de l'heure de la journée). La principale chose à noter est qu'il y a deux composants principaux à ce pipeline : (1) la capacité d'ingérer des données en agissant comme un point d'arrivée POST et (2) la capacité de passer ces données à une API REST et de traiter la sortie comme n'importe quel autre document dans SnapLogic. Le Snaplogic REST Snaps nous permet de traiter des services web arbitraires comme n'importe quel autre Snap dans un pipeline.
Dans le dernier épisode de cette série, nous allons jeter un coup d'œil à l'intérieur de la boîte noire d'AzureML. boîte noire du Snap de requête AzureML et voir comment nous l'implémentons.


