






![]()
Dans le monde des affaires d'aujourd'hui, les données volumineuses (big data) font beaucoup parler d'elles. Outre la recherche, le stockage et la mise à l'échelle, il y a une chose qui ressort clairement : le traitement en flux. C'est là qu'intervient Apache Kafka.
À un niveau élevé, Kafka peut être décrit comme un système de messagerie avec publication et abonnement. Comme tout autre système de messagerie, Kafka maintient des flux de messages dans des rubriques. Les producteurs écrivent des données dans les sujets et les consommateurs lisent des données à partir de ces sujets. Par souci de simplicité, j'ai mis un lien vers la documentation de Kafka ici.
Dans ce billet de blog, je vais démontrer un cas d'utilisation simple où Twitter alimente un sujet Kafka et où les données sont écrites dans Hadoop. Vous trouverez ci-dessous les instructions détaillées sur la façon dont les utilisateurs peuvent construire des pipelines à l'aide de SnapLogic Elastic Integration Platform.
Dans la version du printemps 2016, SnapLogic a introduit les Snap Kafka pour le producteur et le consommateur. Le lecteur Kafka est le Snap du consommateur Kafka et l'écrivain Kafka est le Snap du producteur Kafka.
SnapLogic Pipeline : Publication de flux Twitter vers un sujet Kafka
Pour construire ce pipeline, j'ai besoin d'un Snap Twitter pour récupérer les flux Twitter et publier ces données dans un sujet de la base de données Snap Kafka Writer (producteur Kafka). Choisissons un sujet, disons "Régions", et configurons le Kafka Writer Snap pour qu'il écrive dans ce sujet.
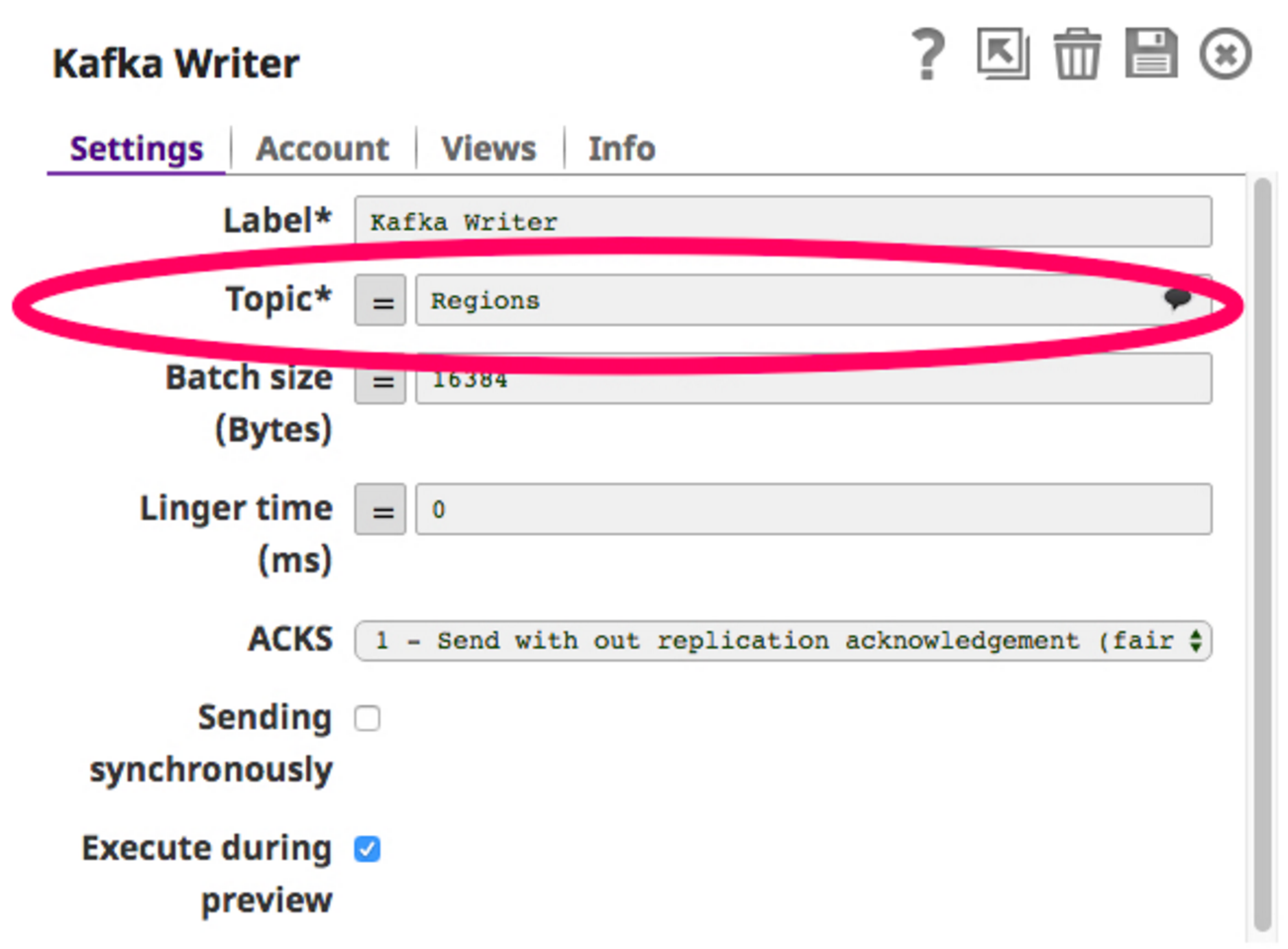 Maintenant que le writer Snap est configuré, nous pouvons construire le pipeline et l'exécuter. Voici à quoi ressemble le pipeline :
Maintenant que le writer Snap est configuré, nous pouvons construire le pipeline et l'exécuter. Voici à quoi ressemble le pipeline :
 Sauvegardons et exécutons-le. Lors de l'exécution, le flux Twitter publiera des données vers le sujet "Régions" sélectionné dans l'instantané Kafka Writer et voici à quoi ressemblera la sortie :
Sauvegardons et exécutons-le. Lors de l'exécution, le flux Twitter publiera des données vers le sujet "Régions" sélectionné dans l'instantané Kafka Writer et voici à quoi ressemblera la sortie :
 Le sujet Kafka "Regions" contient désormais tous les flux Twitter relatifs aux régions, comme indiqué ci-dessus. L'étape suivante consiste à lire le même sujet à l'aide du lecteur Kafka (consommateur Kafka) Snap et, enfin, à écrire sur HDFS.
Le sujet Kafka "Regions" contient désormais tous les flux Twitter relatifs aux régions, comme indiqué ci-dessus. L'étape suivante consiste à lire le même sujet à l'aide du lecteur Kafka (consommateur Kafka) Snap et, enfin, à écrire sur HDFS.
Pour cela, je fais glisser et je dépose un instantané de lecteur Kafka sur le canevas. L'instantané de lecture Kafka agit comme un consommateur en interrogeant constamment le sujet sélectionné. Voici une capture d'écran de l'instantané de lecteur Kafka :
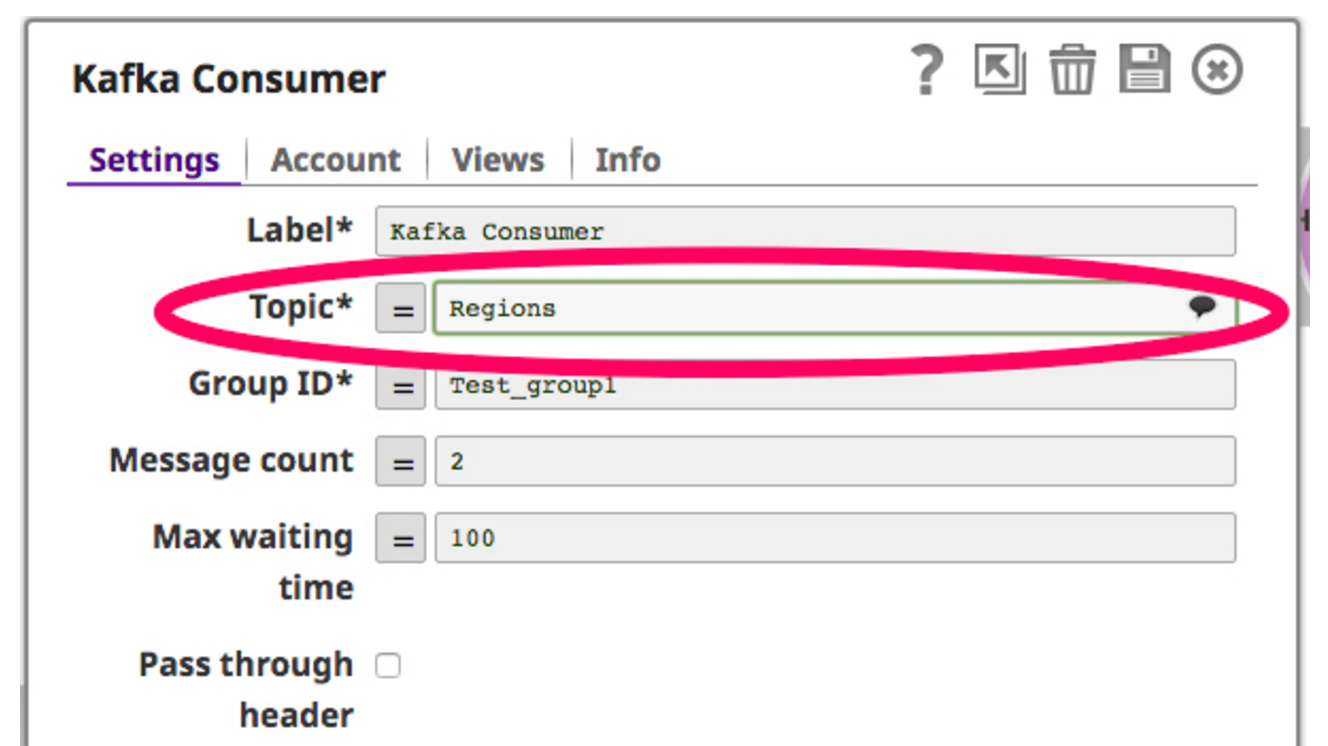 Maintenant que le consommateur est configuré pour lire sur le sujet, je filtre les données récupérées du consommateur Kafka et j'écris sur HDFS à travers le Snap HDFS Writer. Voici une capture d'écran de ce pipeline :
Maintenant que le consommateur est configuré pour lire sur le sujet, je filtre les données récupérées du consommateur Kafka et j'écris sur HDFS à travers le Snap HDFS Writer. Voici une capture d'écran de ce pipeline :
 Maintenant, quand je lance ce pipeline, le Snap consommateur Kafka lit les données du sujet "Regions", filtre les données vers une région spécifique "China" et enfin écrit dans HDFS en utilisant le Snap rédacteur HDFS.
Maintenant, quand je lance ce pipeline, le Snap consommateur Kafka lit les données du sujet "Regions", filtre les données vers une région spécifique "China" et enfin écrit dans HDFS en utilisant le Snap rédacteur HDFS.
Kafka peut également être combiné avec Ultra en exécutant le pipeline de production Twitter en tant que pipeline Ultra afin qu'il fonctionne en permanence, poussant le flux Twitter dans Kafka. Le pipeline consommateur peut quant à lui être exécuté en tant que pipeline programmé consommant régulièrement des lots de données provenant du courtier Kafka.
Le Kafka Writer Snap peut écrire sur plusieurs sujets comme celui-ci et les données de ces sujets peuvent alimenter plusieurs services pour divers cas d'utilisation. La plateforme d'intégration élastique SnapLogic en tant que service(iPaaS) permet tous ces cas d'utilisation de manière beaucoup plus simple et rapide.
Prochaines étapes :
- En savoir plus sur notre version de printemps 2016
- Regardez une démonstration ou contactez-nous
- Faites-nous part des sujets sur lesquels vous aimeriez que nous écrivions dans les commentaires ci-dessous.



