





Imaginez que vous essayiez de trouver un seul point de repère dans une grande ville étrangère sans carte. Il s'agit peut-être d'un exercice futile, mais la même analogie pourrait être faite pour les systèmes d'intelligence artificielle complexes, avec un circuit complexe de routes et d'artères. Les encastrements vectoriels jouent le rôle de carte pour les systèmes d'intelligence artificielle (IA), en traduisant des données complexes telles que des textes et des images en coordonnées numériques. Ces coordonnées révèlent les relations entre les points de données, ce qui permet à l'intelligence artificielle d'effectuer des tâches telles que la recherche ou les recommandations avec précision. Cependant, sans l'infrastructure adéquate, la gestion de ces embeddings peut s'avérer écrasante.
SnapLogic simplifie ce processus. Avec AgentCreatorSnapLogic facilite la création d'embeddings à partir de vos données, leur stockage dans des bases de données vectorielles et leur interrogation pour obtenir des informations. Grâce à la prise en charge de bases de données vectorielles telles que Pinecone, MongoDB, Snowflake et bien d'autres, SnapLogic aide les entreprises à tirer parti des embeddings pour améliorer les les workflows pilotés par l'IA et alimenter des applications plus intelligentes.
Qu'est-ce que l'intégration vectorielle ?
Les encastrements vectoriels sont essentiels pour de nombreuses applications d'intelligence artificielle. Ils aident les machines à traiter des données complexes et non structurées telles que du texte, des images et du son. En convertissant ces données en vecteurs numériques, les embeddings révèlent des modèles et des relations qui échappent souvent aux méthodes traditionnelles. Par exemple, dans la recherche sémantique, les embeddings permettent aux systèmes de comprendre le sens des mots, et pas seulement de faire correspondre les mots-clés. De même, ils alimentent les moteurs de recommandation en identifiant les similitudes entre les articles ou les comportements des utilisateurs.
Avec l'IA générative (GenAI), les encastrements sont essentiels à chaque étape. Au cours de la formation, les grands modèles de langage (LLM) apprennent à partir de données vectorisées, ce qui leur permet de saisir les relations entre les mots et les concepts. Lorsqu'un utilisateur saisit une invite, le modèle la convertit en vecteurs afin d'en saisir le sens et le contexte. Ce processus permet aux LLM de générer des réponses précises et adaptées au contexte en identifiant des modèles dans l'entrée.
En tirant parti de ces enchâssements, l'IA générative ne se contente pas de réagir, elle le fait :
- Recherche d'informations
- S'appuie sur les données existantes
- Trouver des liens significatifs
Cela en fait un outil puissant pour les workflows comme la recherche, la personnalisation et l'automatisation, ce qui favorise le passage à une entreprise agentique.

Générer des embeddings vectoriels avec SnapLogic
L'intégration de SnapLogic avec OpenAI et d'autres LLM rend la génération d'embeddings vectoriels simple et facile. Grâce à Azure OpenAI Embedder Snap, les utilisateurs peuvent rapidement créer des embeddings à partir de différents types de données, tels que du texte ou des images. Ce processus convertit les données d'entrée en vecteurs numériques, ce qui les rend facilement et efficacement lisibles par les machines.
Une interface conviviale simplifie le processus de vectorisation des données. Grâce à la fonctionnalité "glisser-déposer", la création de pipelines pour générer des embeddings est intuitive, même pour les utilisateurs non techniques.
Prenons l'exemple d'une organisation qui stocke des documents de connaissances internes, tels que des politiques, des rapports de recherche ou des manuels de formation. En générant des enchâssements pour ces documents, l'entreprise peut utiliser la génération augmentée par récupération (RAG) pour améliorer les réponses d'un LLM. Lorsqu'un utilisateur saisit une question, le système récupère les documents pertinents sur la base des enchâssements vectorisés, et le LLM utilise ces informations pour générer des réponses plus précises et plus riches en contexte.
Stockage et interrogation d'embeddings avec AgentCreator
Les bases de données vectorielles sont essentielles pour faire évoluer les assistants, les applications et les agents de la GenAI en stockant et en récupérant efficacement les embeddings. Elles permettent des recherches et des récupérations rapides de données d'une manière que les bases de données traditionnelles ont du mal à égaler. SnapLogic prend en charge plusieurs bases de données vectorielles, notamment Pinecone, OpenSearch, MongoDB, AlloyDB, PostgreSQL et Snowflake, ce qui permet aux entreprises de stocker et de gérer de manière transparente les embeddings générés à partir de leurs données.
L'interrogation d'embeddings vectoriels est essentielle pour alimenter les fonctions avancées de l'IA telles que les moteurs de recherche et de recommandation. En trouvant des similitudes entre les embeddings, les systèmes d'IA peuvent rapidement retrouver des contenus pertinents, personnalisant ainsi les résultats pour les utilisateurs. SnapLogic simplifie ce processus en s'intégrant aux bases de données vectorielles qui prennent en charge la recherche par approximation du plus proche voisin (ANN), ce qui permet d'interroger efficacement les embeddings stockés.
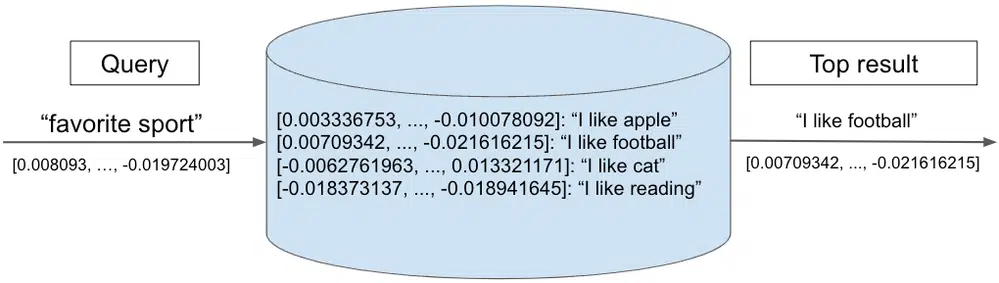
Le diagramme suivant illustre une recherche dans une base de données vectorielle. Un vecteur de requête "sport préféré" est comparé à un ensemble de vecteurs stockés - chacun représentant une phrase de texte. Le plus proche voisin, "J'aime le football", est renvoyé comme premier résultat.


Le SnapLogic AgentCreator améliore encore ces capacités en prenant en charge les principaux LLM d'Amazon, d'OpenAI, d'Azure et de Google. Ces LLM permettent aux entreprises d'interroger les embeddings et d'utiliser ces modèles avancés pour des tâches telles que la génération d'invites, le remplissage de chats et la création de contenu.
L'intégration transparente de SnapLogic avec les bases de données vectorielles et les LLM permet aux entreprises de stocker, d'interroger et de générer du contenu de manière efficace tout en maintenant des performances et une précision élevées. En pratique, ce processus peut se présenter comme suit :
- Étape 1: L'entreprise génère des embeddings vectoriels à partir de sa base de connaissances interne (par exemple, FAQ, manuels de produits) à l'aide de SnapLogic's Azure OpenAI Embedder Snap.
- Étape 2: Ces encastrements sont stockés dans la base de données vectorielles Pinecone, optimisée pour une recherche rapide.
- Étape 3: Lorsqu'il reçoit une requête d'un client, Pinecone effectue une recherche par approximation des plus proches voisins (ANN) pour récupérer les documents pertinents.
- Étape 4: En utilisant Gemini LLM de Google via le Google GenAI LLM Snap Pack, le système génère une réponse personnalisée et riche en contexte en combinant les données récupérées avec la génération de contenu d'IA en temps réel.
Exploitez la puissance des bases de données vectorielles et des embeddings pour votre entreprise
Si vous cherchez à construire un agent GenAI qui tire pleinement parti des données vectorielles, AgentCreator est votre solution. Grâce à une intégration facile, à la prise en charge de plusieurs bases de données vectorielles et à des les workflows transparents, vous pouvez développer vos projets d'IA en toute confiance.
Prêt à passer à l'étape suivante ?
- En savoir plus sur AgentCreator
- Réservez une démonstration avec un expert
- Approfondissez vos connaissances sur les bases de données vectorielles et les intégrations dans cet article technique.







