Dans un précédent billet de blogj'ai abordé les principales tendances dans le domaine de l'intégration des données et les clients qui passent d'une solution sur site à cloud. J'aimerais me concentrer sur une tendance qui consiste à déplacer les données des plates-formes d'analyse de données sur site ou cloud vers une technologie de lac de données telle qu'Azure Data Lake.
Qu'est-ce qu'un lac de données ?
Le lac de données est un terme inventé pour stocker de grandes quantités de données dans leur forme native brute, y compris des données structurées et non structurées, en un seul endroit. Ces données peuvent provenir de diverses sources et le lac de données peut servir de source unique de vérité pour toute organisation. Du point de vue de l'architecture, les données sont d'abord stockées dans un marais de données/acquisition de données, puis nettoyées/transformées dans le cadre de la transformation des données, et enfin publiées pour obtenir des informations commerciales.
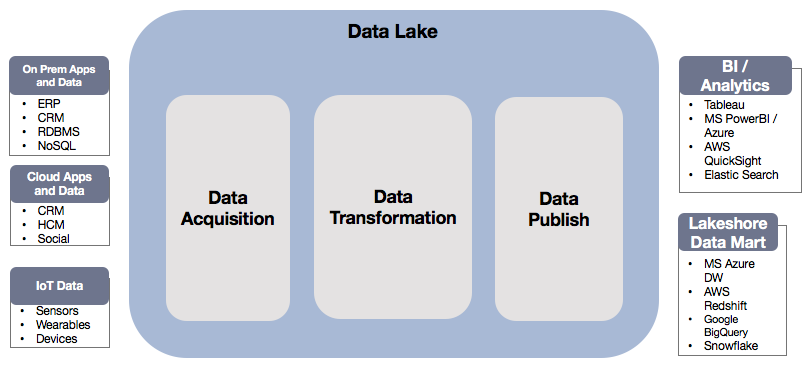
Comme le montre le diagramme ci-dessus, les entreprises disposent de plusieurs systèmes tels que ERP, CRM, RDBMS, NoSQL, capteurs IoT, etc. Les données disparates, stockées dans différents systèmes, sont difficiles à extraire. Un lac de données rassemble toutes les données sous un même toit (acquisition de données) en utilisant l'un des services suivants :
- Blob d'Azure
- Azure Data Lake Store
- Amazon S3
- HDFS
- Autres
Les données stockées dans l'un de ces services peuvent ensuite être transformées de la manière suivante :
- Agrégat
- Trier
- Rejoindre
- Fusionner
- Autres
Les données transformées sont ensuite transférées dans la section de publication/accès aux données (qui pourrait être la même que celle des services d'acquisition de données) où les utilisateurs peuvent utiliser les outils suivants pour interroger les données :
- U-SQL de Microsoft
- Amazon Athena
- Ruche
- Presto
- Autres etc.
En fin de compte, un lac de données peut servir de plateforme pour effectuer des analyses afin d'offrir une meilleure expérience client, des recommandations, etc.
Où les données sont-elles stockées dans Azure ?
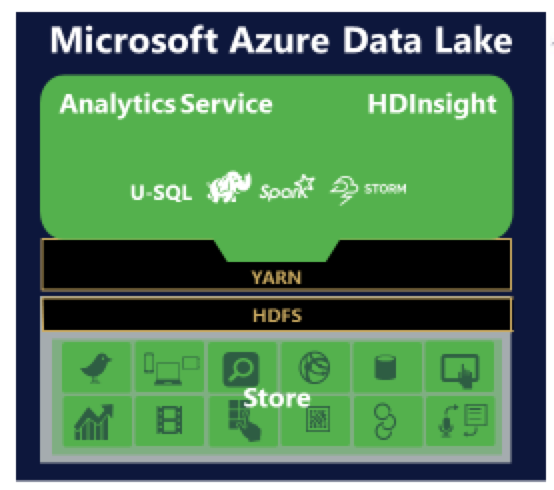
Azure Data Lake est l'un de ces lacs de données de Microsoft et le référentiel utilisé pour stocker toutes les données est Azure Data Lake Store. Les utilisateurs peuvent exécuter Analytics Service, HDInsight ou utiliser U-SQL - un langage de requête big data - au-dessus de ce magasin de données pour obtenir de meilleures informations commerciales.
Azure Data Lake Store (ADLS) peut stocker n'importe quelle donnée dans son format natif. L'un des objectifs de ce magasin de données est de rassembler des données provenant de sources disparates. Snaplogic Enterprise Integration Cloud et ses connecteurs prédéfinis appelés Snaps permettent de déplacer rapidement les données de différents systèmes vers le magasin de données.
ADLS fournit une API complexe, que les applications utilisent pour stocker des données dans ADLS. Snaplogic a fait abstraction de toutes ces complexités par le biais de Snaps, de sorte que les utilisateurs savent où les données sont stockées dans Azure et peuvent maintenant facilement déplacer les données de divers systèmes vers ADLS sans avoir besoin de connaître les complexités de ces API.
Cas d'usages
Une entreprise a besoin de suivre et d'analyser le contenu pour mieux recommander des produits ou des services à ses clients. Ses données - provenant de diverses sources telles qu'Oracle, des fichiers, Twitter, etc. - doivent être stockées dans un référentiel central tel qu'ADLS afin que les utilisateurs professionnels puissent effectuer des analyses dessus pour mesurer le comportement d'achat des clients, leurs centres d'intérêt et les produits achetés.
Voici un exemple de pipeline qui peut répondre à ce cas d'utilisation à l'aide de Snaps :
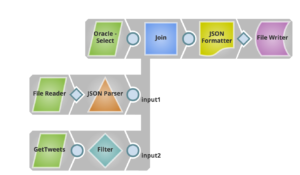
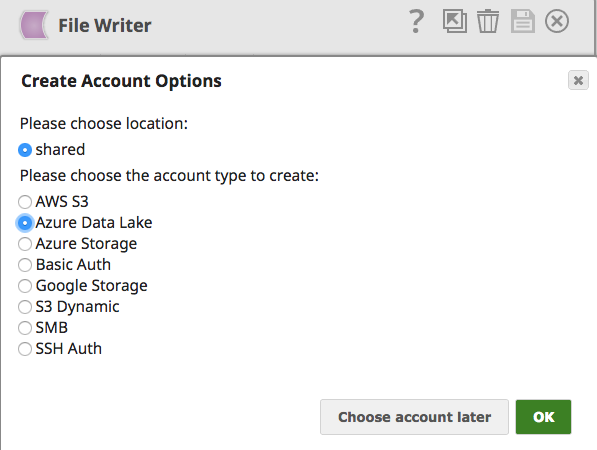
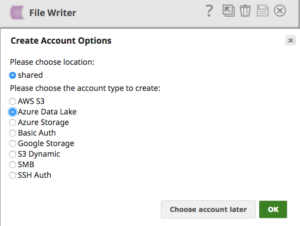
En utilisant File Writer Snap et en choisissant le compte Azure Data Lake comme indiqué ci-dessous, il est possible de stocker facilement les données fusionnées à partir de différents systèmes dans Azure Data Lake.
Dans l'ensemble, le lac de données peut être un magasin de stockage unique pour toutes les données, offrant aux utilisateurs davantage de moyens de tirer des enseignements de sources de données multiples. SnapLogic est prêt à faciliter le déplacement des données vers le lac de données (dans ce cas, un Azure Data Lake Store) de manière simple et rapide.
Pavan Venkatesh est chef de produit senior chez SnapLogic. Suivez-le sur Twitter @pavankv.