






Nel mio precedente post sul blog, ho illustrato il processo e le fasi seguite da SnapLogic per diventare data-driven costruendo un data lake interno cloud .
In questo post condividerò le best practice per la creazione di un'architettura di data lake, gli strumenti necessari per la creazione di un data lake completo e gli insegnamenti tratti dalla costruzione del nostro data lake personale.
Il processo di costruzione di un sistema di dati aziendali cloud
È indispensabile che le organizzazioni comprendano le loro esigenze attuali e future per trovare la giusta soluzione di data lake e seguire il giusto processo di costruzione del data lake. In SnapLogic abbiamo impiegato quasi quattro mesi per costruire la nostra soluzione di data lake cloud sulla base delle seguenti considerazioni:
- Concentrarsi sulle capacità di interrogazione e non sull'archiviazione dei dati. Uno dei motivi principali per cui i data lake falliscono è l'eccessiva priorità data all'archiviazione e non alle capacità di interrogazione.
- Applicare un approccio "query-driven". Abbiamo costruito modelli basati su ciò che dovevamo interrogare dalle fonti iniziali identificate, eliminando il problema di cercare un ago in un pagliaio.
- Identificate le persone che utilizzeranno il data lake e conoscete il tipo di dati che cercano. Le query non sono generiche; ci sono diverse personas e devono essere integrate da diversi modelli di dati.
Di seguito è riportata una panoramica del processo di creazione del data lake, compresi i passaggi che abbiamo seguito per interrogare questo data lake e generare importanti metriche aziendali, in modo che i vari team possano intraprendere azioni pertinenti.
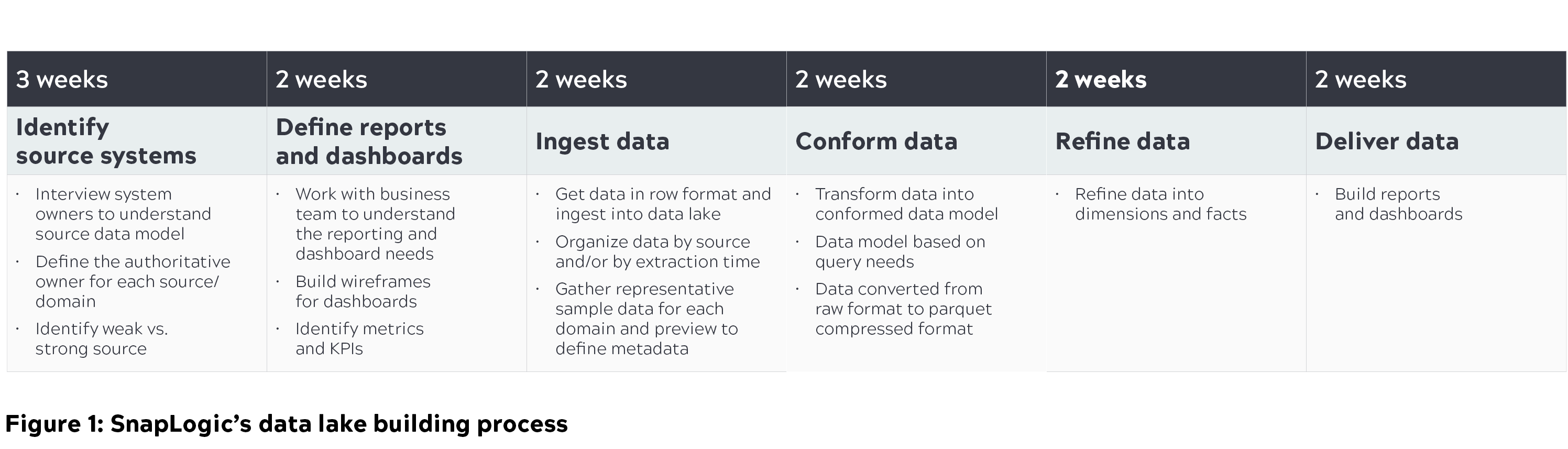
Cloud architettura del data lake
Un'architettura modulare, scalabile e sicura, con prestazioni elevate, è fondamentale per costruire e mantenere un data lake in un'organizzazione. In SnapLogic abbiamo discusso diverse architetture su come costruire e scalare i data lake. Il diagramma seguente illustra l'architettura di base e il nostro processo di pensiero su come abbiamo immaginato un data lake cloud in grado di scalare.
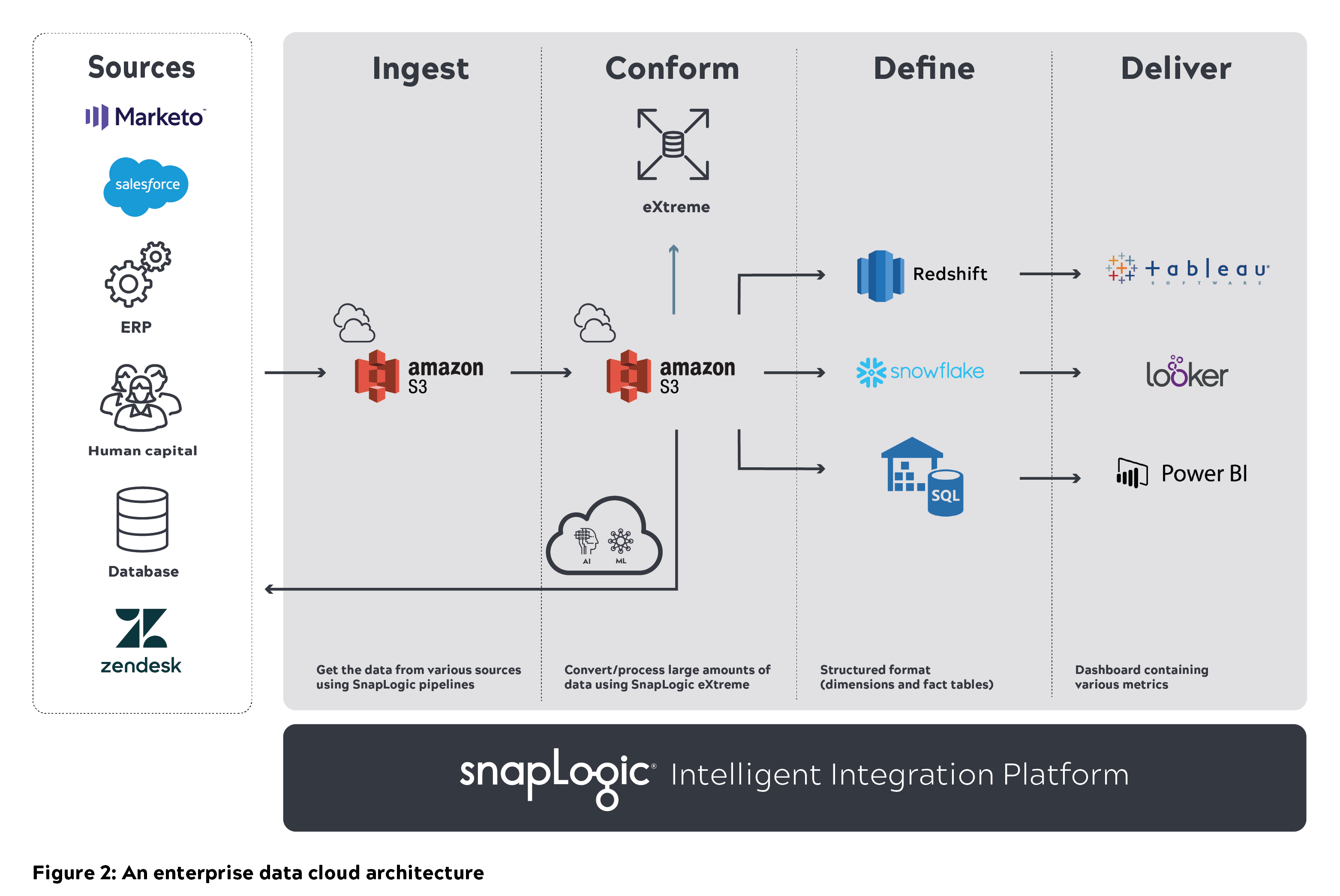
Un'architettura generica di data lake cloud è costituita da varie fonti di dati sulla sinistra. I dati grezzi provenienti da questi sistemi e applicazioni vengono ingeriti in un data lake (ad esempio, Amazon S3). Questi dati devono essere puliti e conformati in modo che gli utenti possano interrogarli direttamente. I dati elaborati vengono poi archiviati in un data warehouse cloud (ad esempio, Amazon Redshift, Snowflake o Azure SQL) che può essere interrogato. Il set di dati raffinato può essere successivamente popolato in strumenti di BI come Tableau, Looker o Power BI.
Strumenti utilizzati per costruire il data lake di SnapLogic:
- Amazon S3 per memorizzare tutti i dati grezzi
- SnapLogic Intelligent Integration Platform (IIP) per l'integrazione e l'elaborazione dei dati.
- Data warehouse Snowflake per memorizzare il set di dati raffinato
- Tableau per la reportistica
Infrastruttura e autorizzazioni degli utenti:
- Dare un accesso adeguato agli utenti per costruire la logica di business ed eseguire le pipeline.
- Dare agli utenti l'accesso ai ruoli IAM per gli ambienti AWS e l'accesso basato sui ruoli per gli altri ambienti da implementare.
Architettura dei dati aziendali SnapLogic cloud
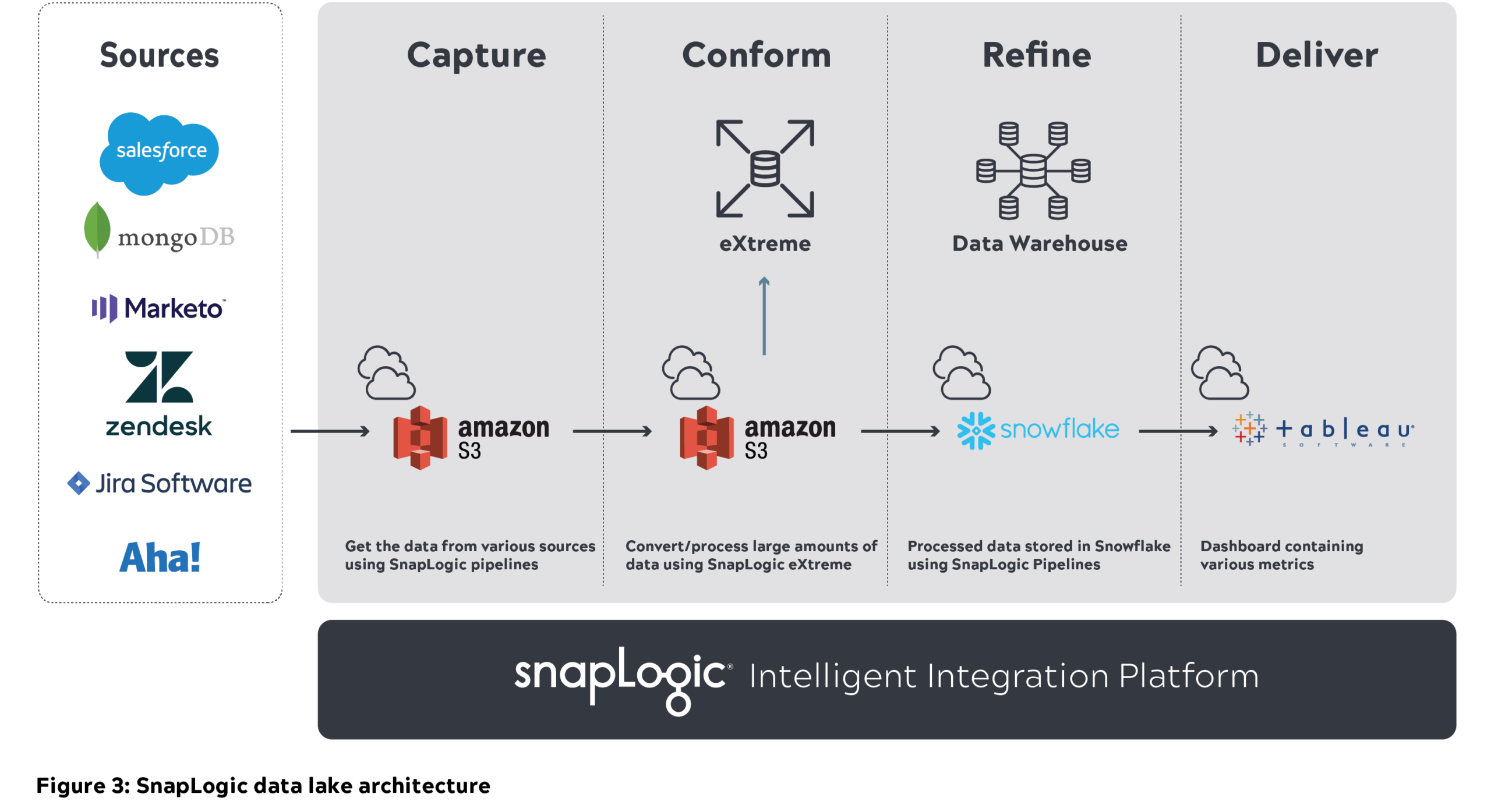
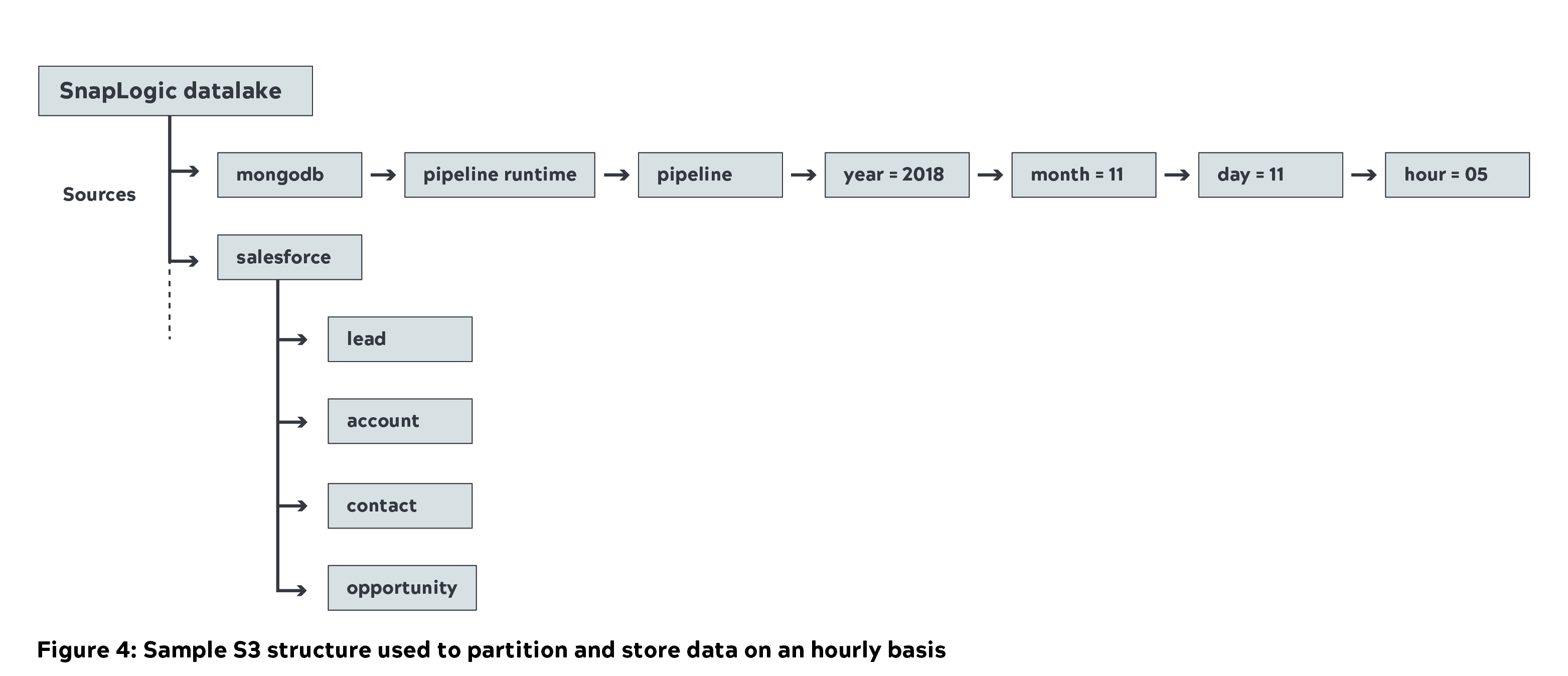
- Abbiamo utilizzato la piattaforma di integrazione unificata di SnapLogic per spostare quasi 1 Petabyte (non compresso) di metadati da varie fonti interne nel data lake Amazon S3 (livello di acquisizione). Di seguito è riportata la struttura S3 di esempio utilizzata da SnapLogic, in cui i dati di origine vengono partizionati e archiviati su base oraria.
- La pulizia è una fase intermedia dopo l'ingestione dei dati. Si tratta di rimuovere i dati duplicati e corrotti. Le pipeline SnapLogic hanno contribuito a rimuovere questi ID duplicati.
- In seguito abbiamo utilizzato Big Data Snaps per convertire i dati grezzi in un formato parquet compresso come parte del livello conformato (è stata ottenuta una compressione del 70%). Di seguito è riportato un esempio di livello conformato S3 e di struttura S3

- L'interrogazione dei dati grezzi e l'identificazione del set di dati rilevanti per le metriche aziendali non è facile. Abbiamo utilizzato il Data Catalog di SnapLogic per ottenere questo risultato e per interrogare i metadati.
- Abbiamo anche fornito agli utenti la flessibilità di interrogare il set di dati conforme utilizzando Amazon Athena.
- SnapLogic eXtreme viene utilizzato per elaborare i big data in cloud e ricavare metriche (esecuzione di pipeline/Snap e conteggio dei documenti) sotto forma di tabella dei fatti. Il cluster viene scalato fino a 21 nodi (di dimensioni m4.16x) per elaborare il carico di lavoro.
- Snowflake è stato utilizzato per memorizzare lo schema a stella (dimensioni e tabelle dei fatti) come parte del livello di raffinazione. Abbiamo utilizzato un'istanza piccola per caricare i dati e un'istanza media per le interrogazioni.
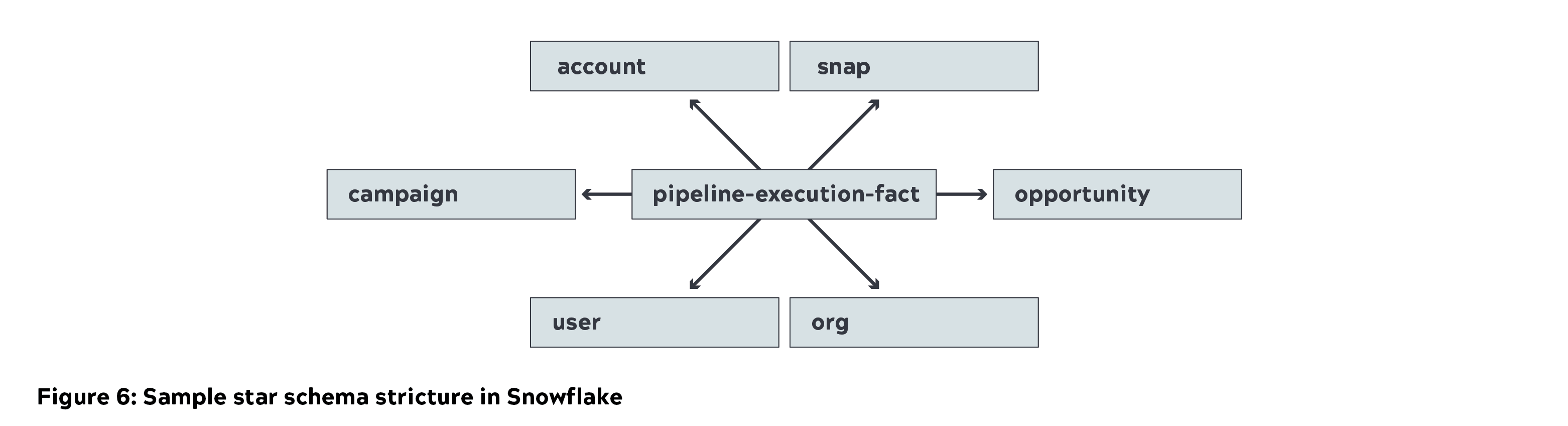
- Tableau è stato utilizzato per acquisire e visualizzare le metriche aziendali. I dati sono stati memorizzati nella cache di Tableau per generare importanti metriche aziendali. I report dettagliati sono stati generati interrogando direttamente Snowflake.
Audit
I dati ricevuti in S3 (data lake) devono essere coerenti rispetto ai dati di origine. Questa verifica deve essere effettuata regolarmente per assicurarsi che non vi siano valori mancanti o duplicati.
- Abbiamo costruito una pipeline automatizzata per convalidare i dati di origine rispetto a quelli archiviati nel data lake (ingest, conform e refine).
- È stato progettato un cruscotto Tableau per monitorare e verificare il carico in tempo quasi reale rispetto ai dati archiviati nel data lake.
- Ogni volta che sono stati trovati dati duplicati o corrotti, abbiamo avvisato il team per correggerli.
Sfide e insegnamenti
Ottenere i dati da varie fonti, in particolare i metadati relativi alla produzione, è stata una delle maggiori sfide che abbiamo incontrato a causa del volume e della complessità dei dati. Inoltre, rendere i dati disponibili in tempo reale per l'analisi era una sfida in salita. Il team di ingegneri di SnapLogic è stato in grado di realizzare questa enorme impresa e di fornirci metadati relativi alla produzione in tempo quasi reale.
La comprensione dei dati ha richiesto tempo e impegno, compreso l'inserimento dei set di dati rilevanti per le metriche aziendali. Una parte dei dati di origine era corrotta e abbiamo dovuto creare una logica di pipeline per escluderla. Abbiamo anche osservato ID di pipeline duplicati nell'origine e abbiamo richiesto un'ulteriore pulizia nel livello di conformità.
Un'adeguata modellazione dei dati è importante con una progettazione efficiente basata sul modo in cui l'utente desidera interrogare i dati. È necessario tenerne conto e creare le tabelle appropriate in Snowflake.
L'esercizio di dimensionamento deve essere pianificato ed eseguito con attenzione. Questo include:
- Nodi SnapLogic per l'elaborazione di set di dati di grandi dimensioni (inizialmente ad alta intensità di memoria e CPU).
- L'elaborazione dei big data in cloud da parte di SnapLogic eXtreme richiede istanze EC2 ad alta intensità di memoria e CPU. Questo può variare anche in base al caso d'uso e alle dimensioni dei dati.
- Allocazione corretta del calcolo e dello storage di Snowflake. L'ingestione dei dati richiederà inizialmente un'istanza di calcolo alta e medio-grande.
- I dati di Tableau vengono memorizzati nella cache per le metriche aziendali più importanti (dashboard esecutivo e report a livello di riepilogo). I report dettagliati possono essere interrogati direttamente su Snowflake.
In pochi mesi siamo riusciti a costruire un data lake con un'attenta pianificazione ed esecuzione utilizzando piattaforme chiave come AWS, SnapLogic, Snowflake e Tableau. E siamo entusiasti di condividere con altre organizzazioni il nostro viaggio nel data lake. Per saperne di più, leggete il nostro white paper "Alleviare il dolore dei big data: la moderna architettura dei dati aziendali".




