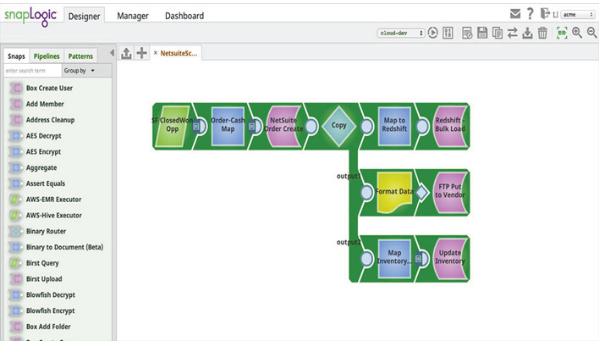
SnapLogic fornisce una piattaforma di integrazione dei big data come servizio (iPaaS) che consente alle aziende clienti di elaborare i dati in modo semplice, intuitivo e potente. SnapLogic fornisce una serie di moduli diversi chiamati Snaps. Un singolo Snap fornisce un modo pratico per ottenere, manipolare o produrre dati e ogni Snap corrisponde a una specifica operazione sui dati. corrisponde a una specifica operazione sui dati. Tutto ciò che il cliente deve fare è trascinare insieme gli Snap corrispondenti e configurarli, creando così una pipeline di dati. I clienti eseguono le pipeline per gestire flussi specifici di integrazione dei dati.
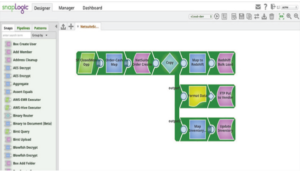
SnapLogic Spark Snap Script: Introduzione
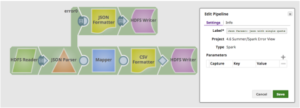
Lo Spark Script Snap consente ai clienti di estendere le funzionalità della piattaforma SnapLogic per gestire i lavori Spark, aggiungendo script personalizzati per la propria logica aziendale che non fanno parte dell'ampia collezione di Snap standard di SnapLogic o riutilizzando gli script esistenti. Il sistema SnapLogic esegue lo script Snap di Spark come un lavoro Spark separato. In sostanza, lo Spark Script Snap consente al cliente di scrivere script Spark all'interno di SnapLogic Designer.
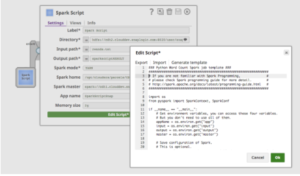
Spark Script Snap supporta anche il passaggio delle proprietà di Spark allo script Spark Python tramite variabili d'ambiente. Ciò consente agli utenti di creare script e configurazioni Spark riutilizzabili, come il nome dell'app, la dimensione della memoria e il master Spark.
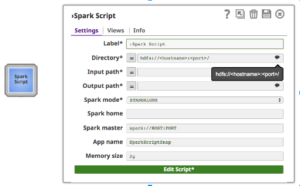
Proprietà:
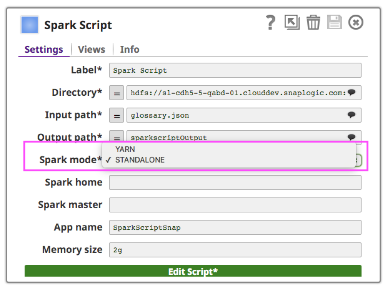
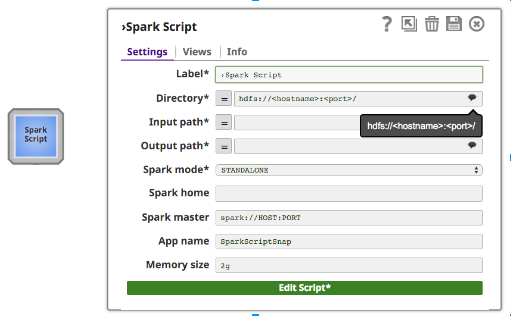
Oltre ai normali campi di Snap, Spark Script Snap fornisce suggerimenti per hdfs "Directory", "Input Path" e "Output Path". Il campo "Directory" mostra solo la directory, ma "Percorso di input" e "Percorso di output" possono mostrare sia file che directory.
Per eseguire Spark Script Snap su un cluster, i clienti possono scegliere tra due tipi di cluster manager (il cluster manager standalone di Spark o YARN), che alloca le risorse tra le applicazioni.
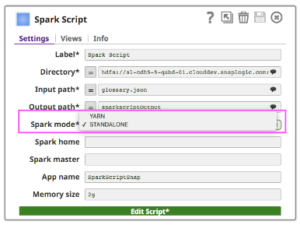
- Standalone - una semplice gestione del cluster associata all'ecosistema Spark
- Hadooop YARN - il gestore di risorse nell'ecosistema Hadoop
Se si utilizza la modalità Standalone, inserire l'URL Master nel campo Master e impostare Master all'interno dello script di Spark, oppure lasciarlo vuoto. Se si utilizza la modalità YARN, non è necessario impostare Master.
Il campo "Spark home" è facoltativo. Se è vuoto, Spark Script Snap utilizzerà il valore predefinito "Spark home", ovvero il percorso in cui i clienti hanno installato spark nel loro cluster. Altrimenti, gli utenti possono specificare la home di Spark del proprio cluster.
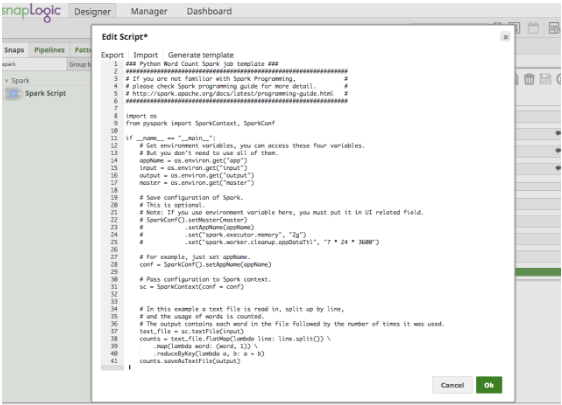
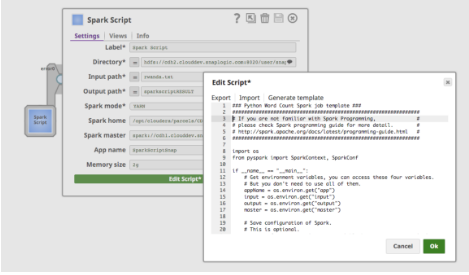
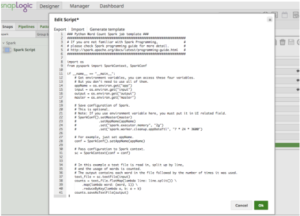
Facendo clic su "Edit Script", lo Spark Script Snap fornirà un modello per eseguire l'esempio del conteggio delle parole. Include anche le modalità di utilizzo delle variabili d'ambiente, come mostra la Figura 4. L'utente può modificare lo script direttamente nella casella o incollare uno script fornito da un collega data scientist.
Collegamenti
È disponibile un video dimostrativo passo-passo di Spark Script Snap qui.
Ci sono molte informazioni su SnapLogic integrazione dei big data e sui servizi integrati di cloud sul nostro sito web, oltre che sui post del blog sull'integrazione dei big data e sulle informazioni iPaaS. blog sull'integrazione dei big data, informazioni su iPaaS, e whitepaper.