





Nell'ultimo post abbiamo analizzato in dettaglio i rilevatori di anomalie e abbiamo mostrato come funzionano alcuni semplici modelli. Ora costruiremo una pipeline per il rilevamento delle anomalie in streaming.
Per questo compito utilizzeremo una pipeline triggered. Una pipeline triggered viene istanziata ogni volta che arriva una richiesta. L'istanziazione può richiedere un paio di secondi, quindi non è consigliata per situazioni di bassa latenza o alto traffico. Se si ricevono dati con una frequenza maggiore o se si vuole una latenza minore, si dovrebbe utilizzare una pipeline utilizzare una pipeline Ultra. Una pipeline Ultra rimane in esecuzione, quindi la latenza di ingresso e uscita è significativamente inferiore.
Ai fini di questo post, supporremo di avere uno Snap Anomaly-Detector-as-a-Service. Nel prossimo post, mostreremo come creare questo Snap utilizzando Azure ML. La nostra pipeline avrà questo aspetto:
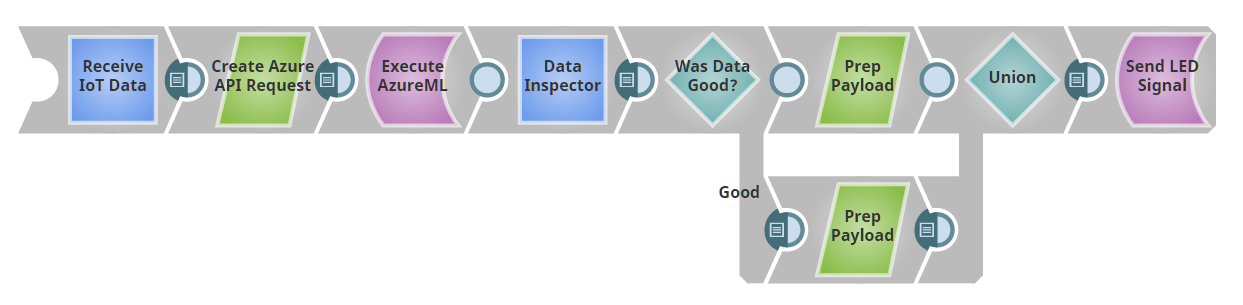
Il nostro primo Snap funge da endpoint REST; in pratica, la pipeline fornisce un server web. Se si invia un messaggio con un payload JSON all'URL fornito, l'output di questo Snap sarà il JSON inviato come documento. (In realtà, stiamo usando uno Snap Record Replay per memorizzare i dati in cache, in modo che una volta inviato un input alla pipeline, questo venga memorizzato per essere riutilizzato durante lo sviluppo, senza dover continuare a inviare nuovi dati).
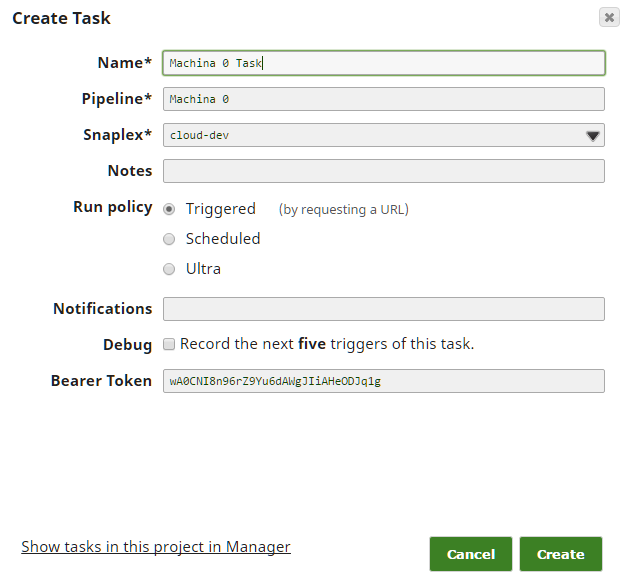
Se si sta seguendo SnapLogicnoterete che lo snap Record Replay non ha un input come mostrato nell'immagine. Per aggiungerlo, fate clic sullo snap, su "Visualizzazioni" e poi sul segno più "+" accanto a input per aggiungere un input. Quindi, prima di dimenticarcene, impostiamo l'attività attivata in modo da poter fare il POST a questa pipeline. pipeline. Fare clic sul pulsante "Crea attività", evidenziato in verde.

Quindi, compilate i campi: nella maggior parte dei casi, i valori predefiniti dovrebbero funzionare; assicuratevi solo di aver selezionato il "Criterio di esecuzione" di "Triggered".
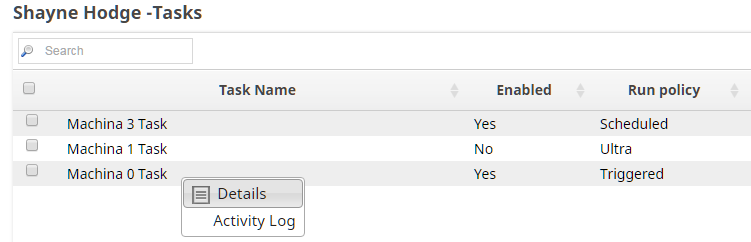
Finally, we need to take a quick detour to Manager to get the URL and Authorization Token for this Task. Drill down on the side navigation pane to Projects -> <Your Project> -> Tasks. In the right hand task pane, click the dropdown arrow and then Details. You’ll be taken to the page with the URL and token you need, as well as a Task Status log. You’ll want to come back here if things seem not to be working right to see if there are failures in the execution of the pipeline.
Ora è possibile prendere l'URL e il token di autenticazione e fornirli all'applicazione o al dispositivo che si desidera inviare i dati. Per questo progetto, abbiamo creato uno script Python che genera casualmente i dati (in formato JSON) e li invia alla pipeline. In generale, è più semplice usare "stub" come questo e passare alla sorgente vera e propria quando si sa che tutto il resto è impostato correttamente.
I dati in arrivo dal nostro endpoint REST vengono inviati al nostro rilevatore di anomalie a scatola nera. Il rilevatore restituisce un giudizio su ogni punto come "buono" o "cattivo". Abbiamo un router Snap che invia i punti buoni e cattivi lungo percorsi di elaborazione diversi. Se avete seguito la serie IoTavrete visto che abbiamo costruito una pipeline che fa lampeggiare un LED di colore diverso a seconda del payload inviato. Qui abbiamo riutilizzato quella luce, trasformando il 'buono' in un payload 'color: 'green' e il cattivo in un payload 'color: 'red', per poi rimandarlo alla luce.
Potremmo invece registrare i punti anomali in un database, attivare un servizio come PagerDuty o pubblicare un annuncio in un canale Slack. (Oppure potremmo fare tutte queste cose, o scegliere canali di notifica diversi a seconda della data e dell'ora). La cosa principale da notare è che questa pipeline ha due componenti principali: (1) la capacità di ingerire i dati agendo come endpoint POST e (2) la capacità di passare i dati a un'API REST ed elaborare l'output come qualsiasi altro documento in SnapLogic. Gli snap REST di Snaplogic ci permettono di trattare servizi web arbitrari come un altro snap in una pipeline.
Nell'ultima puntata di questa serie, daremo uno sguardo all'interno della scatola nera di AzureML. scatola nera della richiesta AzureML e vedremo come implementarlo.


