Ormai tutti conosciamo e stiamo sperimentando l'aumento del volume di dati generati e disponibili per un'organizzazione e i problemi che può causare. È evidente che lo tsunami di dati non ha fine, ed è in gran parte dovuto alla crescente varietà di dati provenienti da fonti mobili, social media e IoT.
Non sorprende quindi che le organizzazioni si trovino ad affogare nei dati. Una recente indagine condotta dalla società indipendente di ricerche di mercato Vanson Bourne ha rivelato che l'80% degli intervistati ritiene che la tecnologia esistente impedisca alla propria organizzazione di trarre vantaggio dalle opportunità offerte dai dati. Lo stesso sondaggio ha anche affermato che solo il 50% dei dati raccolti viene analizzato per ricavarne informazioni di business. Se a tutto questo si aggiunge che le organizzazioni necessitano di approfondimenti dai dati a un ritmo sempre più veloce, la ricetta per il disastro o, nella migliore delle ipotesi, per la perdita di profitti.
Per raccogliere e analizzare i dati per ottenere informazioni aziendali nascoste e abbracciare davvero una cultura data-driven, le organizzazioni hanno bisogno di strumenti che consentano ai data engineer e agli utenti aziendali con conoscenze di dominio di operare in modo più efficiente in questo ambiente, senza richiedere loro competenze tecniche approfondite.
L'ascesa delle tecnologie dei big data
Per raccogliere e analizzare tutti i tipi di dati, le organizzazioni continuano ad adottare tecnologie per i big data e stanno costruendo sempre più spesso data lake basati su cloud. Ciò consente loro di sfruttare i vantaggi offerti da cloud , come ad esempio una riduzione significativa dei costi di investimento (CapEx).
Tuttavia, la gestione dell'ambiente Big Data è spesso impegnativa, in quanto sono necessarie competenze specialistiche per l'installazione, la configurazione e la manutenzione dell'ambiente. Una volta che l'ambiente è pronto e i dipendenti sono pronti a intraprendere il loro progetto, avranno bisogno di sviluppatori Spark che scrivano il codice per eseguire le attività di ingegneria dei dati. Successivamente, dovranno sviluppare un meccanismo per l'invio di lavori di pipeline Spark al cluster di elaborazione. Una volta fatto questo, e se i dipendenti vogliono sfruttare la capacità transitoria offerta dai cluster Big Data as a Service (BDaaS), dovranno sviluppare la gestione del ciclo di vita.
Tutto questo richiede molte centinaia, se non migliaia, di righe di codice che sono complesse, soggette a errori e in genere richiedono mesi per essere scritte. Allo stesso tempo, gli sviluppatori Spark sono molto richiesti e in generale c'è un'enorme carenza di talenti.
Quando i big data incontrano l'eXtreme
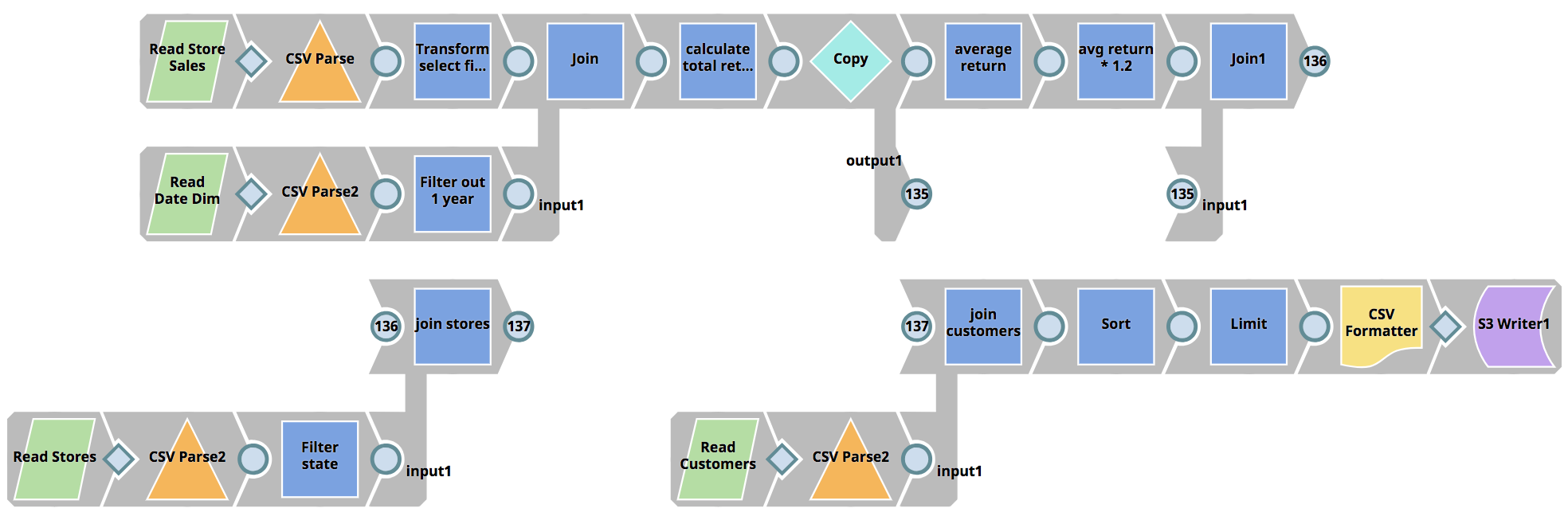
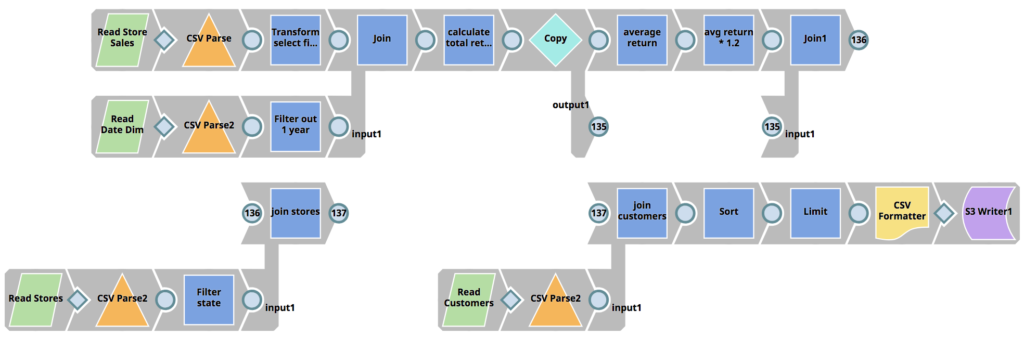
SnapLogic eXtreme affronta la carenza di talenti nel campo dell'ingegneria dei dati migliorando l'Enterprise Integration Cloud e il suo paradigma di progettazione visiva, consentendo alle organizzazioni di costruire pipeline Spark senza dover scrivere lavori Spark in Scala, Python o Java, riducendo così drasticamente le competenze richieste. Un progetto che in genere richiederebbe più sviluppatori e più mesi può essere ridotto a poche ore.
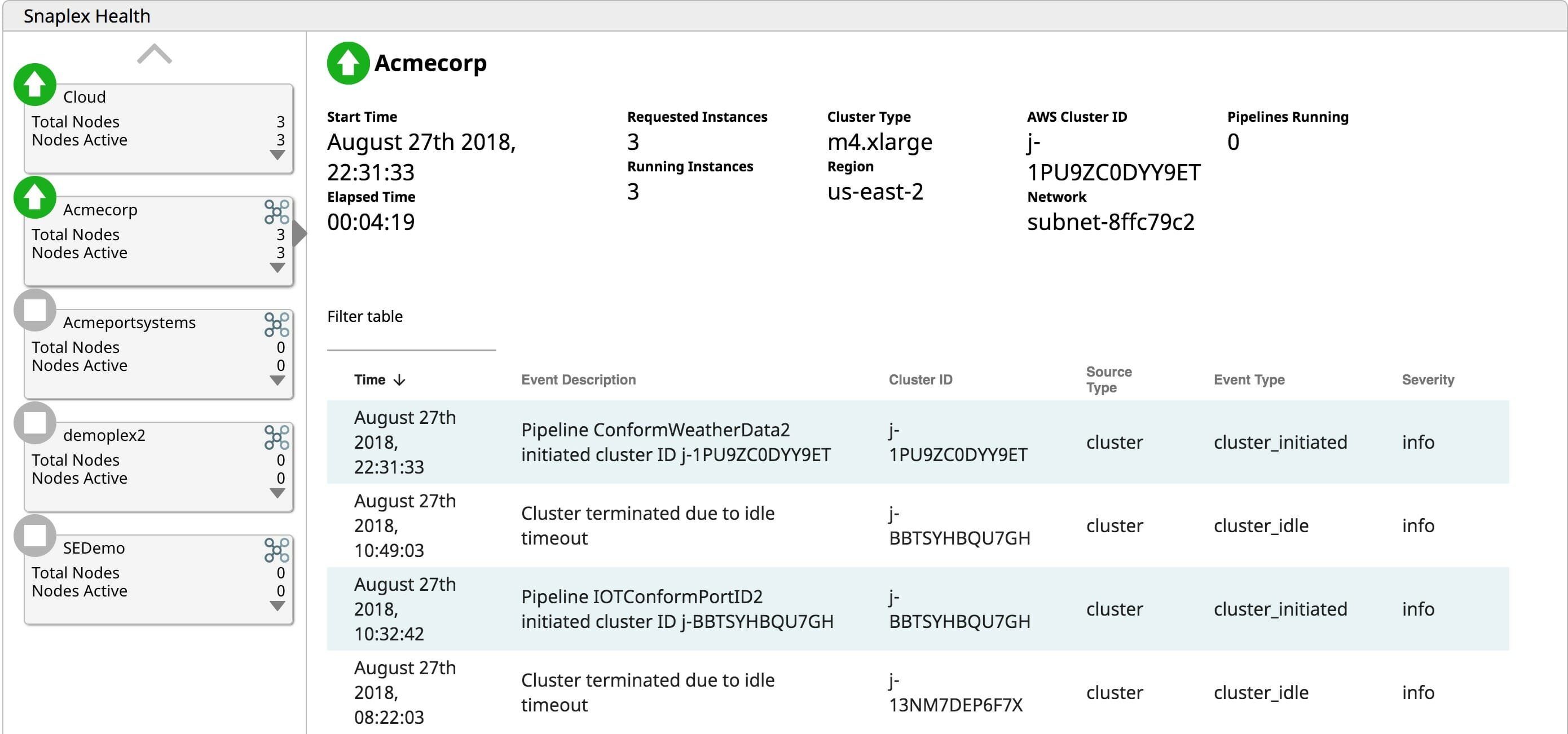
Grazie alla capacità di gestione del ciclo di vita di SnapLogic eXtreme, gli utenti possono attivare i cluster su richiesta quando è necessaria l'elaborazione. Se non è necessario eseguire alcun lavoro, pagare per un cluster inattivo è solo uno spreco di OpEx. SnapLogic eXtreme scala elasticamente i cluster quando è necessario, man mano che l'elaborazione aumenta. La capacità di scalare in modo elastico elimina la necessità di dimensionare i cluster per i picchi di carico. L'aumento della capacità di elaborazione in base alle esigenze consente alle aziende di pagare solo per ciò che utilizzano, evitando sprechi di OpEx sui server inattivi. Infine, eXtreme termina i cluster in esecuzione quando non ci sono lavori in sospeso da elaborare. Perché pagare per mantenere i server in funzione quando non aggiungono valore al business? Fornire un ambiente di runtime per big data completamente gestito e automatizzato basato su cloud consente alle aziende di risparmiare preziosi OpEx.
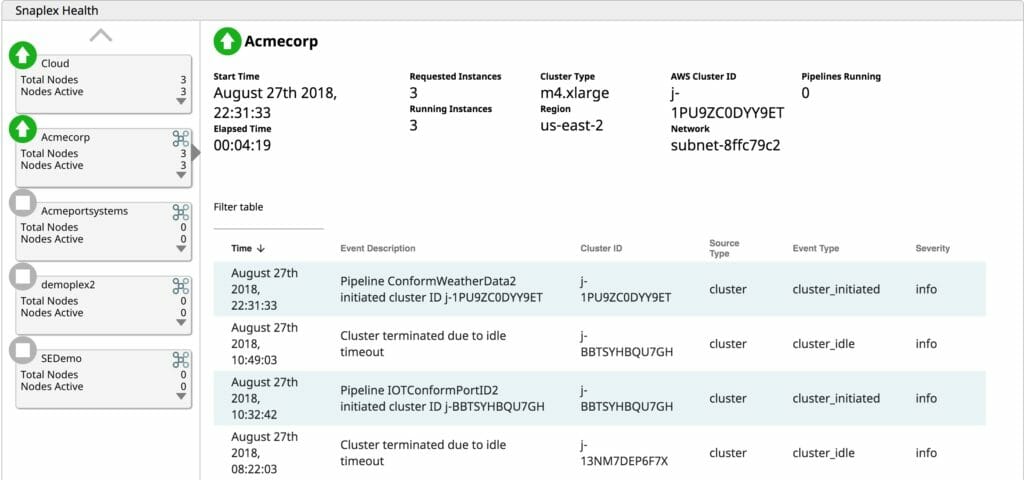
Le iniziative sui big data ricevono aiuto
Le funzionalità di eXtreme garantiscono velocità e agilità all'organizzazione. SnapLogic eXtreme consente alle organizzazioni di fare di più con meno risorse grazie all'uso della sua interfaccia di progettazione visiva. Le funzionalità self-service consentono agli utenti tecnici di lanciare più rapidamente le iniziative sul mercato e di ottenere rapidamente informazioni significative, un aspetto fondamentale nell'ambiente frenetico di oggi. Dopotutto, Forrester prevede che "entro il 2021, le aziende guidate dagli insight ruberanno 1,8 trilioni di dollari all'anno di fatturato ai concorrenti che non lo sono".
Il continuo aumento del volume e della varietà dei dati e la loro analisi per ottenere informazioni commerciali nascoste non accenna a diminuire. Se da un lato le tecnologie dei big data forniscono gli strumenti giusti per il lavoro, dall'altro offrono un ambiente operativo impegnativo che richiede un set di competenze specializzate e difficili da reperire per avere successo. SnapLogic eXtreme offre i mezzi per ridurre il tempo, le risorse e le competenze necessarie per costruire e gestire architetture di big data all'indirizzo cloud. Se la vostra organizzazione sta lottando con la sua iniziativa big data, provate SnapLogic eXtreme.