






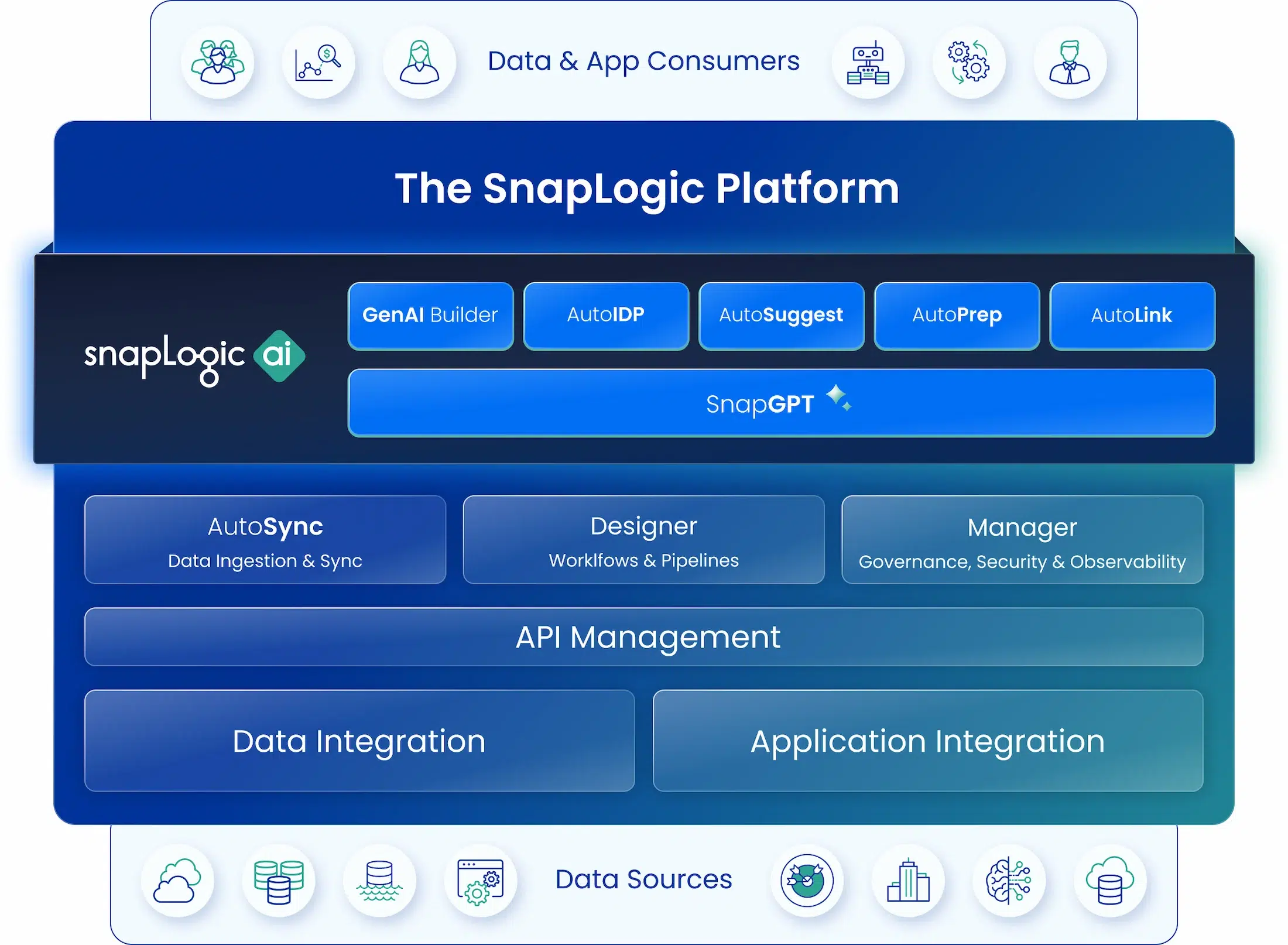

SnapLogic AI
Browse our suite of generative integration tools built to help you integrate, automate, and orchestrate 100X faster.
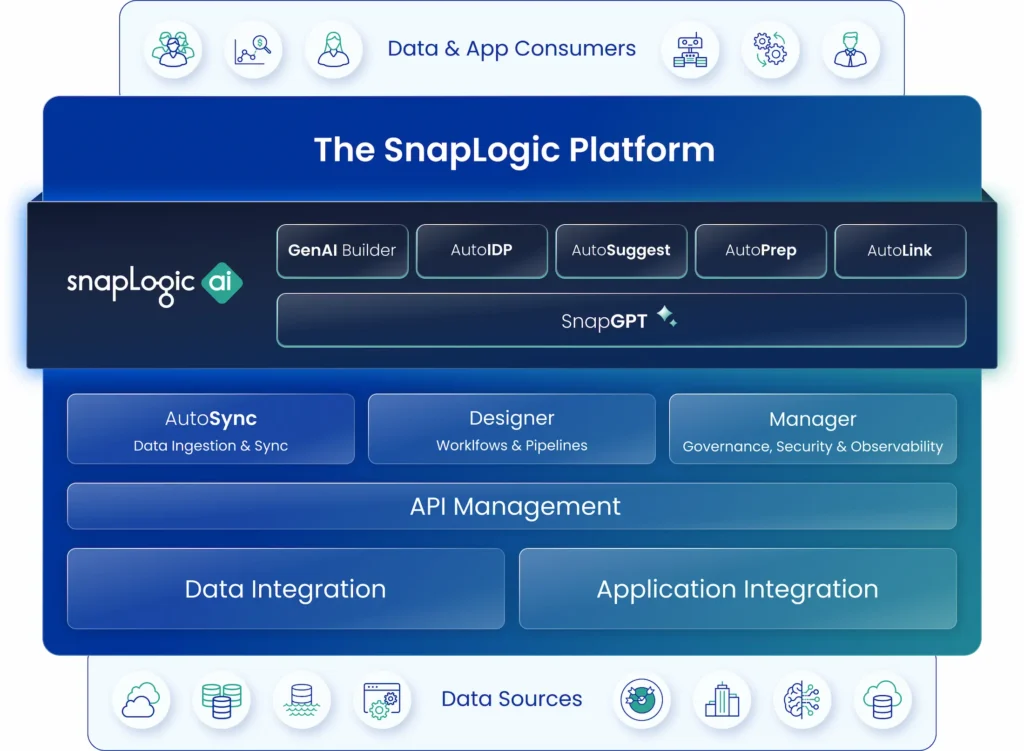
Platform Features
Security & privacy
Built with enterprise-level security and governance in mind, SnapLogic protects customer data through a combination of access controls and encryption.
Flexible deployment
Connects with existing technology ecosystems, including on-premises installs, cloud-hosted applications, and hybrid data environments.
One platform
Enables the configuration and management of data and application integrations and automation through a single pane of glass.
Pre-built connectors
The SnapLogic iPaaS includes 700+ pre-built connectors, Snaps, and integration templates for common business processes and workflows.
AI-enhanced
Powered with a suite of AI tools for LLM-powered application development, data transformation, and integrations without coding.
Business insights
The platform’s intuitive interface makes it easy for business users to access data analytics and real-time reporting, and activate automation.





SnapLogic Products
Effortless integration for every innovator, from the business visionary to the architect of data.
Data Integration and Automation
Mobilize data to the cloud with visual ETL or ELT and use reverse ETL to send data to your apps. Orchestrate data flows across your organization with ease and accelerate your data analytics projects for everyone.
Explore Data Integration
SnapLogic AutoSync
Accelerate time to value and boost business agility. SnapLogic AutoSync delivers automated ingestion of data from SaaS applications into popular cloud data warehouses.
Explore AutoSync
Application Integration
Connect every application, at scale, without the complexity.
Say goodbye to manually integrating countless applications with a no-code/low-code iPaaS that includes hundreds of Snaps (pre-built connectors) to enterprise apps.
Explore App Integration
API Management and Development
Efficiently create, manage, and secure all your API integrations with one self-service solution. Unleash the potential of an agile composable enterprise powered by your microservices to your consumers.
Explore APIM
All the tools you love, integrated in a Snap
Snaps are pre-built connections that make code-free integrations possible.
With over 700 Snaps to choose from, SnapLogic makes it easy to create simple workflows or complex business processes between cross-functional work groups. Enable your organization to automate entire ecosystems of applications, databases, APIs, data warehouses, devices, and more.
It takes us minutes to deploy integrations across 1,800 applications with SnapLogic. We’ve also been able to reduce support overhead and costs by over 25%.
Swati Oza
Director of IT Emerging Technology, Data Integration, and ML at HPE
CASE STUDY
How Global Payments Company Vitesse Banked On SnapLogic To Turn a Complex Integration Process Into Success
“We’re looking at developing different kinds of Snaps for different kinds of processes, allowing for different options for clients to utilise in their transfer journey. Flexibility is core to our game plan, and SnapLogic offers just that.”
Craig Walter
Principal Solutions Manager at Vitesse
CASE STUDY
Guild Streamlines Customer Onboarding Process with SnapLogic
Highlights
- Reduced customer onboarding time for engineers by 70%
- Consolidated 1,000+ lines of code, 5 projects and 2 teams to a single configuration file
- Expanded a multimillion-dollar partnership with API-based sources
CASE STUDY
Catalyzing Connectivity:
SnapLogic Fuels Rhodes College’s Workday Digital Transformation
Highlights
- Saved 50% on implementation cost vs. using a third party
- Reduced legacy on-premises ERP and SIS systems from 22 to 1
- Now have access to business and student resourcing analytics
FAQs
An iPaaS (Integration Platform as a Service) is a suite of cloud services enabling the development, execution, and governance of application integration, API management, and data integration with the goal of integrating both on-premises and cloud-based systems, services, cloud applications, on-premises apps, and other data sources. These services are typically designed with low-code visual interfaces and templates. Unlike Enterprise Service Bus (ESB) of the past, they are built on a cloud-based infrastructure such as AWS, Azure, and Google Cloud to serve as a platform for the automation of workflows and to share data between all applications and data sources both within an organization as well as outside. Organizations can use iPaaS to integrate the technology across their whole software ecosystem.
SnapLogic is the only iPaaS solution to include:
- Native AI with petabytes of metadata
- An easy-to-use interface for both technical and business users
- ETL, ELT and reverse ETL processes managed in one platform
- App-to-app integration
- Full lifecycle APIM and developer portals
- Separate control and data planes for security
- Scalability for 1,000s of IT and non-IT users
The SnapLogic iPaaS is used by global enterprises and organizations in a variety of industries, including manufacturing, retail, financial services, higher education, food service, healthcare, and technology. Though typically managed by IT, multiple departments can leverage the SnapLogic iPaaS for workflow automation, analytics and reporting, from HR to sales, marketing and finance. Additionally, the SnapLogic iPaaS works as an OEM/embeddable solution that enables independent software providers (ISV), managed services practices (MSP), and professional services organizations (PSO) to offer a standardized, efficient, and reliable data integration solution for interoperability with their customers.
Integration platforms gather data from all sources, which helps to reduce information silos. If you use a data warehouse or multiple data lakes, integration platforms help improve data accuracy because they make it easier to include data from all sources. If a customer interacts with the support team about an issue, and you only analyze data about their interaction with the sales or marketing team, you are not getting the complete picture. Data gathered from all sources results in a more accurate analysis. Additionally, an iPaaS makes it easier to add and remove applications as needed, save time through automation, and strengthen data governance.