





Il y a quelques années, j‘ai écrit un article intitulé "REST GET and the SnapLogic Public APIs for Pipeline Executions" ( REST GET et les API publiques de SnapLogic pour les exécutions de pipeline), qui illustre comment utiliser les API publiques de SnapLogic pour les informations d‘exécution de pipeline ainsi que la fonction d‘itération de REST GET. Il y a quelques semaines, un collègue m‘a demandé s‘il existait un modèle SnapLogic pour ce cas d‘utilisation. Je lui ai répondu que je n‘avais jamais eu l‘occasion de le faire (soupir).
La question de mon collègue m‘a incité à créer un SnapLogic Pattern - un modèle de pipeline d‘intégration - qui exploite les API publiques SnapLogic et REST GET. Voici donc ce qu‘il en est :
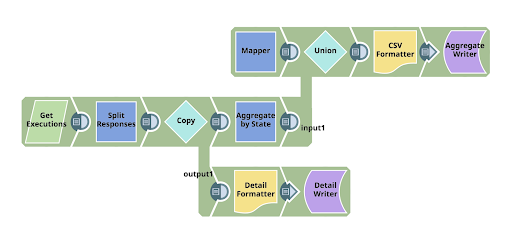
En résumé, le pipeline utilise les API publiques de SnapLogic pour lire le résumé des exécutions, puis fait deux choses avec elles : il écrit d‘abord le détail de la ligne récupérée dans un fichier, et simultanément, il écrit également un résumé dans un fichier, de sorte que vous puissiez voir ce que la sortie contient. En cours de route, j‘utilise diverses techniques :
- Utilisation de la fonction d‘itération du REST Get Snap, de sorte que les multiples requêtes itératives requises pour récupérer les détails des API publiques SnapLogic sont consommées.
- Configuration dynamique des URL utilisées avec l‘opérateur ternaire du langage d‘expression
- Utilisation d‘une expression pour obtenir le nom de l‘organisation (à utiliser dans les URL)
- Placer plusieurs données de formats différents dans un seul flux de sortie, avec une implication de l‘ordre.
Configuration de l‘URL d‘obtention REST :
Tout d‘abord, examinons la manière dont j‘ai défini l‘URL à appeler :
| ‘https://elastic.snaplogic.com/api/1/rest/public/runtime/‘ + pipe.plexPath.split(‘/‘)[1] + ‘?level=summary‘ + (_state == null || _state =="" ? " : ‘&state=‘+ _state) + (_hours == null || _hours =="" ? " : ‘&last_hours=‘+ _hours) + (_batchsize == null || _batchsize =="" ? " : ‘&limit=‘+ _batchsize) |
L‘expression semble un peu complexe, mais décomposons-la :
L‘API de base se trouve à l‘adresse suivante
https://elastic.snaplogic.com/api/1/rest/public/runtime/.
Après avoir localisé l‘API de base, nous devons spécifier le nom de l‘organisation. Pour que le nom soit dynamique et puisse fonctionner dans n‘importe quelle organisation, j‘ai utilisé une expression pour extraire le nom de l‘organisation du seul endroit que j‘ai pu trouver dans le chemin d‘accès du Snaplex utilisé. L‘expression :
pipe.plexPath.split(‘/‘)[1]
capture le premier élément du chemin Snaplex, qui est le nom de l‘organisation.
La série d‘expressions suivante évalue l‘état des paramètres du pipeline et configure les options de la requête API - l‘ensemble des états requis, le nombre d‘heures à récupérer et la taille du lot à utiliser. De manière conditionnelle, nous pouvons soit 1) configurer chaque paramètre selon qu‘il est vide ou nul (dans ce cas, je n‘ai pas besoin de passer une valeur) ; 2) passer la valeur configurée qui sera récupérée à partir des paramètres passés au pipeline ; ou, 3) utiliser les valeurs par défaut définies dans les propriétés du pipeline.
La configuration "Has Next
Le champ "A la suite" permet de décider si, après la première extraction, nous devons procéder à d‘autres itérations pour obtenir l‘ensemble des données. Une expression booléenne doit le déterminer. Dans ce cas, dans la première réponse à la requête, SnapLogic fournit des données sur ce qui est disponible : le nombre total disponible, le décalage et la limite (la limite correspond au nombre dans le lot). Je vérifie ensuite la somme de ce que j‘ai déjà et du nombre disponible, ce qui me donne un résultat booléen.
| $entity.response_map.offset + $entity.response_map.limit < $entity.response_map.total |
L‘"URL suivant"
Cette URL pourrait être similaire à la première, mais nous devons en plus lui indiquer où commencer la recherche (mis en évidence dans le code ci-dessous) :
| ‘https://elastic.snaplogic.com/api/1/rest/public/runtime/‘ + pipe.plexPath.split(‘/‘)[1] + ‘?level=summary‘ + pipe.plexPath.split(‘/‘)[1] + ‘?level=summary‘ + (_state == null || _state =="" ? " : ‘&state=‘+ _state) + (_hours == null || _hours ==" ? " : ‘&state=‘+ _state) + (_hours == null || _hours =="" ? " : ‘&last_hours=‘+ _hours) + ‘&offset=‘ + ($entity.response_map.offset+$entity.response_map.limit) + (_batchsize == null || _batchsize =="" ? " : ‘&limit=‘+ _batchsize) |
Mettre plusieurs données de formats différents dans un seul flux de sortie avec une implication d‘ordre
L‘autre technique que j‘ai utilisée dans ce pipeline est une construction qui m‘a permis d‘écrire le fichier de sortie du résumé en utilisant deux flux de données. Cette technique m‘a permis d‘introduire les données dans le fichier comme je le souhaitais.
Tout d‘abord, j‘ai le Snap Mapper qui, lors de l‘exécution du pipeline, n‘attend aucune entrée et produit donc immédiatement un document unique. J‘ai créé une expression pour capturer les paramètres d‘exécution et les formater dans une chaîne :
| “Execution statistics for State: ” + ( _state == null || _state ==”” ? ‘UnSpecified/all’ : _state) + “, Hours: ” + ( _hours == null || _hours ==”” ? ‘UnSpecified/1 Hr’ : _hours) + “, batchsize:” + ( _batchsize == null || _batchsize ==”” ? ‘UnSpecified/10’ : _batchsize) + ” at ” + Date.now().toLocaleDateTimeString(‘{“format”:”yyyy-MM-dd HH:mm:ss”}’) |
Là encore, j‘ai essayé de présenter les données dans un format raisonnable afin que, lorsqu‘elles sont visualisées à l‘aide du visualiseur de champ, vous puissiez facilement voir les résultats et la configuration qui a permis d‘obtenir ces résultats.
La sortie du mappeur a de fortes chances d‘être le premier document dans l‘Union Snap qui le suit, de sorte qu‘il s‘agit toujours de la première partie du flux de données écrites dans le fichier de sortie.
Lorsque le REST GET a fait son travail, le Snap Aggregate agrège le nombre d‘exécutions dans chaque état, que nous transmettons ensuite au fichier.
Le résultat est le résumé des informations présenté ci-dessous, visualisé à l‘aide de l‘aperçu du File Writer :
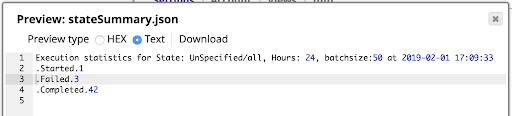
N‘oubliez pas que le REST GET Snap nécessite un compte REST Basic Auth avec des informations d‘identification valides pour effectuer la requête à l‘adresse plateforme. Le résultat ne comprendra que les résultats des exécutions que ces informations d‘identification ont le droit de voir. Utilisez un compte de type Admin si vous voulez voir toutes les exécutions dans une organisation.
Si vous souhaitez essayer le pipeline SnapLogic présenté dans ce billet de blog, vous pouvez le télécharger dans la communauté SnapLogic.







