





Un paio di anni fa, ho scritto un articolo, "REST GET e le API pubbliche di SnapLogic per le esecuzioni di pipeline", che illustra come utilizzare sia le API pubbliche di SnapLogic per le informazioni sull'esecuzione delle pipeline, sia la funzione di iterazione su REST GET. Solo un paio di settimane fa, un collega mi ha chiesto se fosse disponibile un pattern SnapLogic per questo caso d'uso. Gli ho risposto che non ci ero mai riuscito (sigh).
La domanda del mio collega mi ha ispirato a costruire uno SnapLogic Pattern, un modello di pipeline di integrazione, che sfrutta le API pubbliche di SnapLogic e REST GET. Quindi, ecco qui:
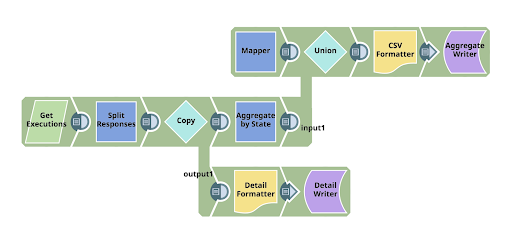
In sintesi, la pipeline utilizza le API pubbliche di SnapLogic per leggere il riepilogo delle esecuzioni, quindi esegue due operazioni: innanzitutto scrive il dettaglio delle righe recuperate in un file e, contemporaneamente, scrive anche un riepilogo in un file, in modo da poter vedere cosa contiene l'output. Lungo il percorso sto utilizzando varie tecniche:
- Utilizzando la funzione di iterazione di REST Get Snap, in modo da consumare le richieste iterative multiple necessarie per recuperare i dettagli dalle API pubbliche di SnapLogic.
- Configurazione dinamica degli URL utilizzati con l'operatore ternario del linguaggio di espressione
- Utilizzo di un'espressione per ottenere il nome dell'organizzazione (da utilizzare negli URL)
- Mettere più dati di formato diverso in un unico flusso di uscita, con un'implicazione di ordine
REST Ottenere la configurazione dell'URL:
Per prima cosa, analizziamo il modo in cui ho definito l'URL da chiamare:
| 'https://elastic.snaplogic.com/api/1/rest/public/runtime/' + pipe.plexPath.split('/')[1] + '?level=summary' + (_state == null || _state =="" ? " : '&state='+ _state) + (_hours == null || _hours =="" ? " : '&last_hours='+ _hours) + (_batchsize == null || _batchsize =="" ? " : '&limit='+ _batchsize) |
Sembra un'espressione un po' complessa, ma vediamo di scomporla:
L'API principale si trova all'indirizzo
https://elastic.snaplogic.com/api/1/rest/public/runtime/.
Dopo aver individuato l'API principale, occorre specificare il nome dell'organizzazione. Per rendere il nome dinamico e in grado di funzionare in qualsiasi organizzazione, ho usato un'espressione per estrarre l'organizzazione dall'unico posto disponibile nel percorso di Snaplex utilizzato. L'espressione:
pipe.plexPath.split('/')[1]
cattura il primo elemento del percorso Snaplex, che è il nome dell'organizzazione.
La successiva serie di espressioni valuta lo stato dei parametri della pipeline e configura le opzioni per la richiesta API: l'insieme degli stati richiesti, il numero di ore da recuperare e la dimensione del batch da utilizzare. In modo condizionato, possiamo 1) configurare ogni parametro in base al fatto che sia vuoto o nullo (nel qual caso, non è necessario inserire un valore); 2) inserire il valore configurato, che verrà prelevato dai parametri passati alla pipeline; oppure 3) utilizzare i valori predefiniti definiti nelle proprietà della pipeline.
La configurazione "Has Next
Il campo "Has Next" è il modo in cui si decide se, dopo il primo recupero, è necessario eseguire altre iterazioni per ottenere l'intero set. Un'espressione booleana dovrebbe determinarlo. In questo caso, nella prima risposta alla richiesta, SnapLogic fornisce i dati su ciò che è disponibile: il numero totale disponibile, l'offset e il limite (il limite corrisponde al numero nel batch). Quindi controllo la somma di ciò che ho già e del numero disponibile, ottenendo un risultato booleano.
| $entity.response_map.offset + $entity.response_map.limit < $entity.response_map.total |
L'"URL successivo"
Questo URL potrebbe essere simile al primo, ma dobbiamo anche dirgli da dove iniziare il recupero (evidenziato nel codice sottostante):
| 'https://elastic.snaplogic.com/api/1/rest/public/runtime/' + pipe.plexPath.split('/')[1] + '?level=summary' + (_state == null || _state =="" ? " : '&state='+ _state) + (_hours == null || _hours =="" ? " : '&last_hours='+ _hours) + '&offset=' + ($entity.response_map.offset+$entity.response_map.limit) + (_batchsize == null || _batchsize =="" ? " : '&limit='+ _batchsize) |
Mettere più dati di formato diverso in un unico flusso di uscita con un'implicazione di ordine
L'altra tecnica che ho utilizzato in questa pipeline è un costrutto che mi ha permesso di scrivere il file di output riassuntivo utilizzando due flussi di dati. Questa tecnica mi ha permesso di inserire i dati nel file nel modo desiderato.
Innanzitutto, ho il Mapper Snap, che, durante l'esecuzione della pipeline, non attende alcun input e quindi produce immediatamente un singolo documento. Ho creato un'espressione per catturare i parametri di esecuzione e formattarli in una stringa:
| “Execution statistics for State: ” + ( _state == null || _state ==”” ? ‘UnSpecified/all’ : _state) + “, Hours: ” + ( _hours == null || _hours ==”” ? ‘UnSpecified/1 Hr’ : _hours) + “, batchsize:” + ( _batchsize == null || _batchsize ==”” ? ‘UnSpecified/10’ : _batchsize) + ” at ” + Date.now().toLocaleDateTimeString(‘{“format”:”yyyy-MM-dd HH:mm:ss”}’) |
Anche in questo caso, ho cercato di formattare i dati in un formato ragionevole, in modo che, quando si visualizzano con il visualizzatore di campi, si possano vedere facilmente i risultati e la configurazione che li ha ottenuti.
È molto probabile che l'output del mapper sia il primo documento dell'Union Snap che lo segue, quindi è sempre la prima parte del flusso di dati scritto nel file di output.
Quando il REST GET ha fatto il suo dovere, l'Aggregate Snap aggrega il conteggio delle esecuzioni in ogni stato, che viene poi passato nel file.
Il risultato è il riepilogo delle informazioni mostrato di seguito, visualizzato utilizzando l'anteprima del File Writer:
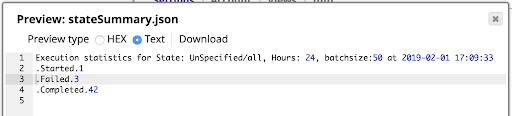
Non dimenticare che il REST GET Snap richiede un account REST Basic Auth con credenziali valide per effettuare la richiesta alla piattaforma. Il risultato includerà solo i risultati delle esecuzioni che tali credenziali hanno l'autorità di vedere. Utilizzare un account di tipo Admin se si desidera vedere tutte le esecuzioni in un'organizzazione.
Se volete provare la pipeline di SnapLogic descritta in questo post, potete scaricarla dalla Community di SnapLogic.





