





Uno dei principi fondamentali di progettazione di SnapLogic è semplice: una pipeline deve essere eseguita sulla piattaforma di esecuzione giusta per il lavoro. Che si tratti di uno streaming di eventi a bassa latenza, di un movimento di dati ad alto volume o di trasformazioni complesse, l'architettura deve adattarsi.
Questo post illustra come funzionano internamente le pipeline di SnapLogic, come viene gestita l'esecuzione in ambienti diversi e come l'intelligenza artificiale è ora integrata nel tessuto della piattaforma.
Elaborazione orientata al documento
Tutti i dati elaborati nelle pipeline SnapLogic sono rappresentati internamente in formato JSON, un modello che chiamiamo elaborazione orientata ai documenti. Anche gli input piatti e basati su record vengono normalizzati in JSON, consentendo il supporto continuo di strutture di dati sia piatte che gerarchiche.
Le pipeline sono composte da Snaps, componenti modulari che incapsulano la logica di connettività o di trasformazione. Gli snap possono:
- Collegarsi ad applicazioni, database, API o file.
- Trasformare o arricchire i record (filtrare, mappare, unire, aggregare)
- Orchestrare i flussi di lavoro attraverso sistemi complessi
Queste pipeline sono costruite visivamente in SnapLogic Designer, la nostra interfaccia di sviluppo a basso codice e basata su browser. Designer consente ad architetti e ingegneri di trascinare, rilasciare e configurare Snap, fornendo al contempo convalida in tempo reale, suggerimenti automatici e assistenza guidata dall'intelligenza artificiale per uno sviluppo più rapido.
Streaming e pipeline di accumulo
Classifichiamo le pipeline come streaming o accumulo:
- Le pipeline di streaming elaborano ogni documento in modo indipendente, riducendo al minimo l'uso della memoria e supportando carichi di lavoro a bassa latenza e ad alta velocità.
- Le pipeline di accumulo richiedono la raccolta di tutti gli input prima dell'output (ad esempio, sort, join, aggregate), che richiedono più memoria ma consentono di eseguire operazioni complesse su grandi insiemi di dati.
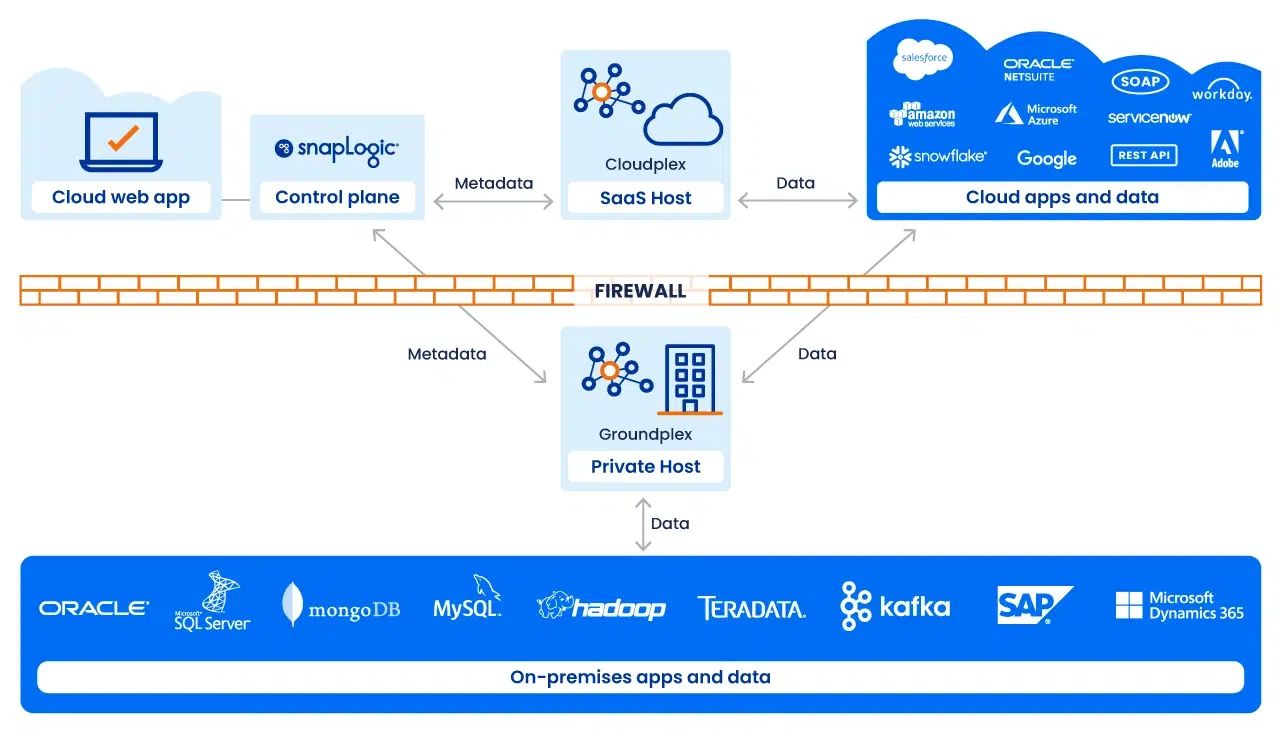
Esecuzione con Snaplex
L'esecuzione delle pipeline è gestita da uno Snaplex, il fabric di esecuzione scalabile di SnapLogic. Uno Snaplex è costituito da nodi di elaborazione o container che eseguono le pipeline.
Supportiamo diversi modelli di distribuzione:
- Cloudplex: uno Snaplex completamente gestito e a scalabilità automatica ospitato da SnapLogic. Ideale per le integrazioni cloud
- Groundplex: uno Snaplex distribuito in sede o in VPC, in cui l'elaborazione avviene dietro il firewall per esigenze di conformità o di sovranità dei dati.
- Ibrido / Cloud: architetture che abbracciano entrambi, consentendo di posizionare l'esecuzione in modo ottimale in base ai requisiti di carico di lavoro e di governance.
Ogni Snaplex è in grado di scalare dinamicamente, garantendo prestazioni affidabili anche in condizioni di carico fluttuante.
Monitoraggio e governance
La visibilità operativa è gestita attraverso SnapLogic Monitor, una console centralizzata che fornisce:
- Stato e salute della pipeline in tempo reale
- Metriche di esecuzione storiche e tracciamento degli errori
- Controlli di accesso basati sui ruoli per un'amministrazione sicura
- Rilevamento delle anomalie assistito dall'intelligenza artificiale per segnalare modelli di esecuzione insoliti
Monitor dà agli stakeholder IT e aziendali la certezza che le pipeline funzionino in modo sicuro ed efficiente su scala.
Il livello AI/Agentico
L'architettura di SnapLogic è arricchita dall'integrazione agenziale: Agenti di intelligenza artificiale che assistono continuamente nella creazione, nell'ottimizzazione e nella manutenzione delle pipeline. Questi agenti:
- Suggerite mappature e trasformazioni in Designer
- Rilevare le inefficienze e proporre miglioramenti al Monitor
- Adattare le pipeline all'evoluzione dei modelli di dati, delle applicazioni o delle regole aziendali.
Invece di integrazioni statiche, le pipeline diventano adattive e auto-ottimizzanti, riducendo in modo significativo i costi generali dell'IT.
Flessibilità indipendente dalla piattaforma
Un principio chiave della nostra architettura è il disaccoppiamento della progettazione delle pipeline dall'esecuzione. Le pipeline costruite in Designer possono essere eseguite su qualsiasi tipo di Snaplex, sia esso cloud, terrestre o ibrido. Quando i requisiti cambiano (ad esempio, i volumi di dati crescono, le aspettative di latenza si inaspriscono, emergono vincoli di conformità), la stessa pipeline può essere rieseguita su un target più adatto senza doverla riprogettare.
Preparatevi all'IA con una solida base di dati
L'architettura di SnapLogic è progettata per l'adattabilità. Le pipeline sono modulari, l'esecuzione è distribuita e l'intelligenza artificiale aumenta ogni fase, dalla progettazione all'ottimizzazione del runtime. Separando ciò che una pipeline fa da dove viene eseguita, la piattaforma offre alle aziende una base in grado di evolvere con le esigenze tecnologiche e aziendali.
Siete pronti a vedere come funziona? Contattateci oggi stesso per prenotare una demo.







