





Eines der wichtigsten Designprinzipien von SnapLogic ist einfach: Eine Pipeline sollte auf der richtigen Ausführungsplattform für die jeweilige Aufgabe laufen. Unabhängig davon, ob es sich um Ereignis-Streaming mit niedriger Latenz, Datenbewegungen mit hohem Volumen oder komplexe Transformationen handelt, muss sich die Architektur anpassen.
In diesem Beitrag wird beschrieben, wie SnapLogic-Pipelines intern funktionieren, wie die Ausführung in verschiedenen Umgebungen verwaltet wird und wie KI jetzt in die Plattform integriert ist.
Dokumentenorientierte Verarbeitung
Alle in SnapLogic-Pipelines verarbeiteten Daten werden intern im JSON-Format dargestellt, ein Modell, das wir dokumentenorientierte Verarbeitung nennen. Sogar flache, datensatzbasierte Eingaben werden in JSON normalisiert, was eine nahtlose Unterstützung für flache und hierarchische Datenstrukturen ermöglicht.
Pipelines bestehen aus Snaps, modularen Komponenten, die Konnektivität oder Transformationslogik kapseln. Snaps können:
- Verbindung zu Anwendungen, Datenbanken, APIs oder Dateien
- Datensätze umwandeln oder anreichern (filtern, zuordnen, verbinden, aggregieren)
- Orchestrierung von Arbeitsabläufen über komplexe Systeme hinweg
Diese Pipelines werden visuell im SnapLogic Designer erstellt, unserer browserbasierten Low-Code-Entwicklungsoberfläche. Der Designer ermöglicht Architekten und Ingenieuren das Ziehen, Ablegen und Konfigurieren von Snaps und bietet gleichzeitig Echtzeit-Validierung, automatische Vorschläge und KI-gesteuerte Unterstützung für eine schnellere Entwicklung.
Streaming vs. akkumulierende Pipelines
Wir klassifizieren Pipelines entweder als Streaming oder als akkumulierend:
- Streaming-Pipelines verarbeiten jedes Dokument unabhängig voneinander, minimieren die Speichernutzung und unterstützen Arbeitslasten mit niedriger Latenz und hohem Durchsatz
- Akkumulierende Pipelines erfordern, dass alle Eingaben vor der Ausgabe gesammelt werden (z. B. Sortieren, Verknüpfen, Aggregieren), was mehr Speicherplatz erfordert, aber komplexe Operationen in großen Datensätzen ermöglicht.
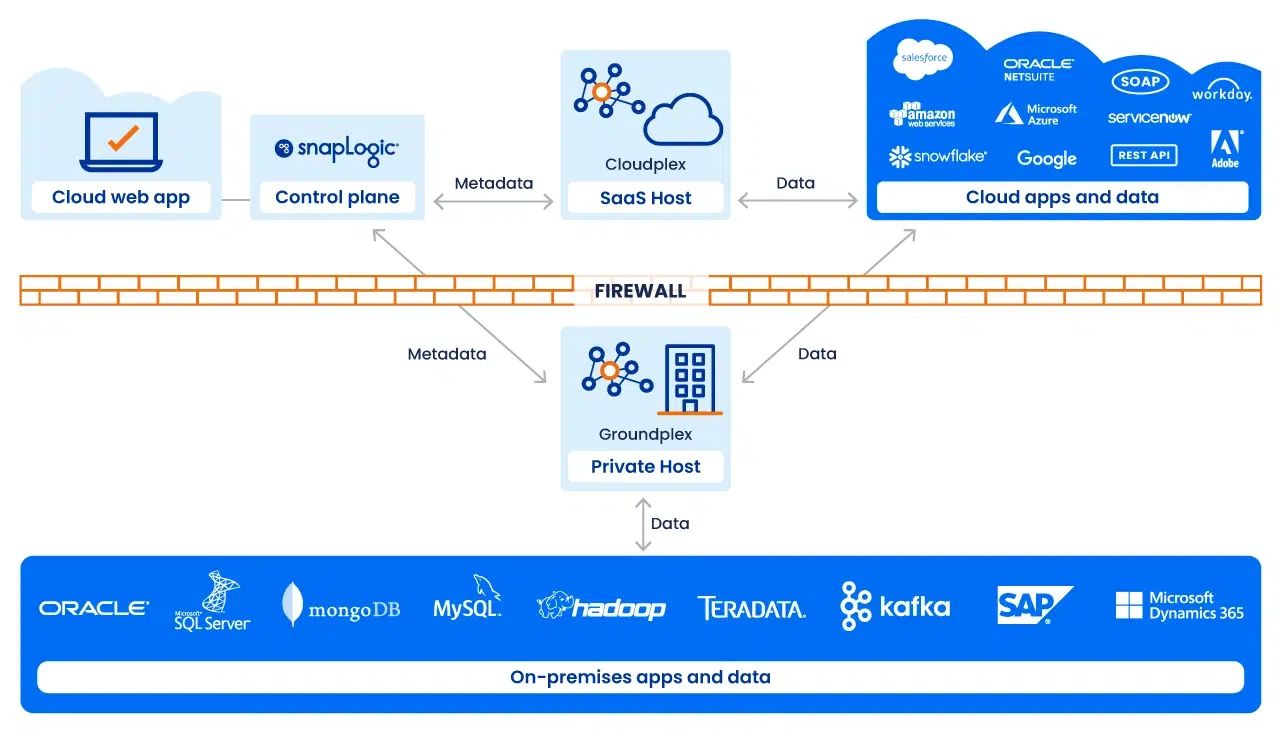
Ausführung mit Snaplex
Die Ausführung von Pipelines erfolgt über einen Snaplex, die skalierbare Ausführungsstruktur von SnapLogic. Ein Snaplex besteht aus Verarbeitungsknoten oder Containern, die Pipelines ausführen.
Wir unterstützen mehrere Bereitstellungsmodelle:
- Cloudplex: ein vollständig verwalteter, automatisch skalierender Snaplex, der von SnapLogic gehostet wird. Ideal für Cloud-to-Cloud-Integrationen
- Groundplex: ein vor Ort oder im VPC installierter Snaplex, bei dem die Verarbeitung aus Gründen der Compliance oder der Datensouveränität hinter der Firewall erfolgt
- Hybrid / Multi-Cloud: Architekturen, die beide Bereiche umfassen und eine optimale Ausführung je nach Arbeitslast und Governance-Anforderungen ermöglichen
Jeder Snaplex kann dynamisch skaliert werden, was eine zuverlässige Leistung auch bei schwankender Last gewährleistet.
Überwachung und Steuerung
Die Betriebstransparenz wird über SnapLogic Monitor, eine zentrale Konsole, gewährleistet:
- Status und Zustand der Pipeline in Echtzeit
- Historische Ausführungsmetriken und Fehlerverfolgung
- Rollenbasierte Zugriffskontrollen für eine sichere Verwaltung
- KI-gestützte Anomalieerkennung zur Erkennung ungewöhnlicher Ausführungsmuster
Monitor gibt sowohl der IT als auch den Unternehmensverantwortlichen die Gewissheit, dass die Pipelines sicher und effizient im großen Maßstab laufen.
Die KI/Agentenschicht
Die Architektur von SnapLogic wird durch die Integration von Agenten ergänzt: KI-Agenten, die kontinuierlich bei der Erstellung, Optimierung und Wartung von Pipelines helfen. Diese Agenten:
- Mappings und Transformationen im Designer vorschlagen
- Ineffizienzen aufdecken und Verbesserungen in Monitor vorschlagen
- Anpassung der Pipelines an die Entwicklung von Datenmodellen, Anwendungen oder Geschäftsregeln
Anstelle von statischen Integrationen werden Pipelines adaptiv und selbstoptimierend, was den IT-Overhead erheblich reduziert.
Plattformunabhängige Flexibilität
Ein wichtiges Prinzip unserer Architektur ist die Entkopplung von Pipeline-Design und Ausführung. In Designer erstellte Pipelines können auf jedem Snaplex-Typ ausgeführt werden, egal ob Cloud, Boden oder Hybrid. Wenn sich die Anforderungen ändern (z. B. wachsende Datenmengen, höhere Erwartungen an die Latenzzeit, neue Konformitätsanforderungen), kann dieselbe Pipeline auf einem geeigneteren Ziel ohne erneutes Design ausgeführt werden.
Machen Sie sich mit einer soliden Datengrundlage fit für KI
Die Architektur von SnapLogic ist auf Anpassungsfähigkeit ausgelegt. Pipelines sind modular, die Ausführung ist verteilt und KI unterstützt jede Phase vom Entwurf bis zur Laufzeitoptimierung. Durch die Trennung dessen, was eine Pipeline tut, von dem, wo sie ausgeführt wird, bietet die Plattform Unternehmen eine Grundlage, die sich sowohl mit der Technologie als auch mit den Geschäftsanforderungen weiterentwickeln kann.
Möchten Sie sehen, wie es funktioniert? Kontaktieren Sie uns noch heute, um eine Demo zu buchen.







