





L'un des principes de conception fondamentaux de SnapLogic est simple : un pipeline doit s'exécuter sur la plateforme exécution adaptée à la tâche. Qu'il s'agisse d'un flux d'événements à faible latence, d'un mouvement de données à haut volume ou de transformations complexes, l'architecture doit s'adapter.
Ce billet décrit le fonctionnement interne des pipelines SnapLogic, la gestion de l'exécution dans différents environnements et l'intégration de l'IA dans la structure de la plateforme
Traitement orienté vers les documents
Toutes les données traitées dans les pipelines SnapLogic sont représentées en interne au format JSON, un modèle que nous appelons traitement orienté document. Même les données d'entrée plates et basées sur des enregistrements sont normalisées au format JSON, ce qui permet une prise en charge transparente des structures de données plates et hiérarchiques.
Les pipelines sont composés de Snaps, des composants modulaires qui encapsulent la connectivité ou la logique de transformation. Les Snaps peuvent :
- Connexion à des applications, des bases de données, des API ou des fichiers
- Transformer ou enrichir les enregistrements (filtre, carte, jointure, agrégat)
- Orchestrer les workflows dans des systèmes complexes
Ces pipelines sont construits visuellement dans SnapLogic Designer, notre interface de développement à code bas, basée sur un navigateur. Le Designer permet aux architectes et aux ingénieurs de glisser, déposer et configurer les Snaps, tout en offrant une validation en temps réel, des suggestions automatiques et une assistance pilotée par l'IA pour un développement plus rapide.
Pipelines de flux ou d'accumulation
Nous classons les pipelines en deux catégories : les pipelines de flux et les pipelines d'accumulation :
- Les pipelines de streaming traitent chaque document indépendamment, minimisant l'utilisation de la mémoire et prenant en charge les charges de travail à faible latence et à haut débit.
- Les pipelines d'accumulation exigent que toutes les entrées soient collectées avant la sortie (par exemple, tri, jointure, agrégation), ce qui demande plus de mémoire mais permet des opérations complexes sur de grands ensembles de données.
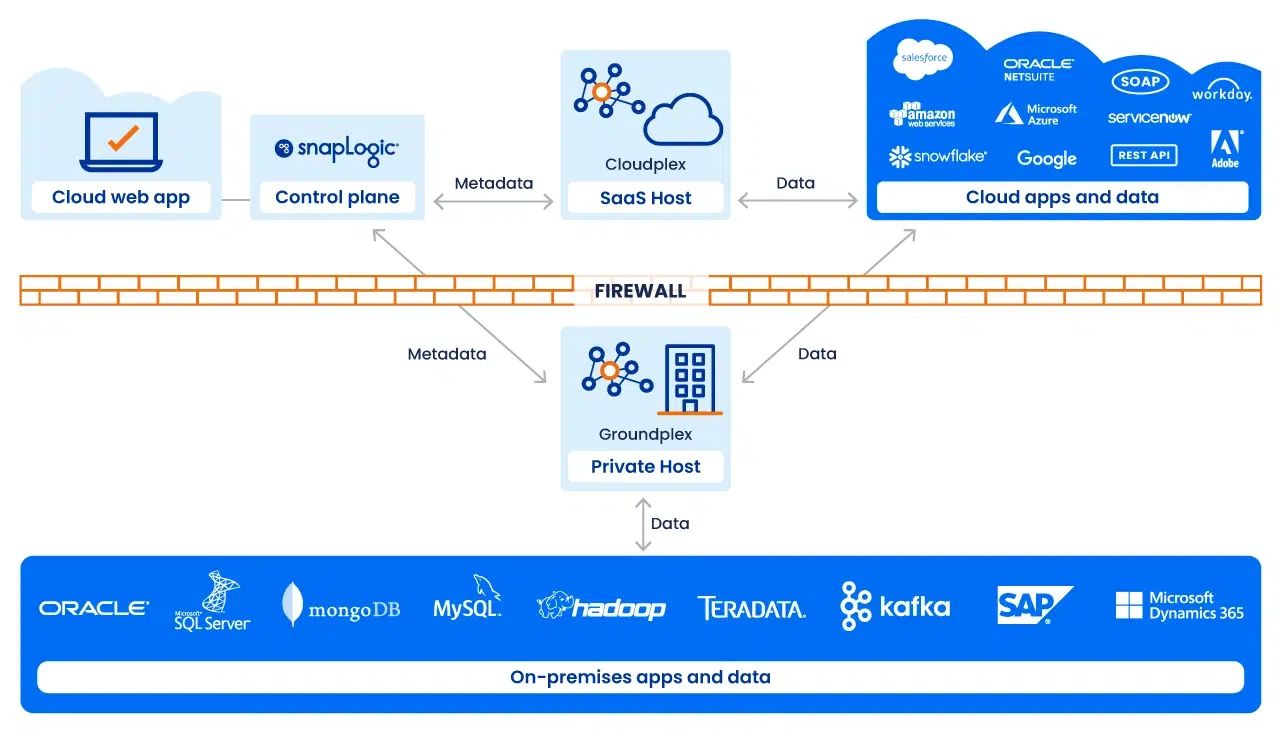
Exécution avec Snaplex
L'exécution des pipelines est assurée par un Snaplex, la structure d'exécution évolutive de SnapLogic. Un Snaplex se compose de nœuds de traitement ou de conteneurs qui exécutent des pipelines.
Nous prenons en charge plusieurs modèles de déploiement :
- Cloudplex: un Snaplex entièrement géré, à mise à l'échelle automatique, hébergé par SnapLogic. Idéal pour les intégrations cloudcloud cloud
- Groundplex: un Snaplex déployé sur site ou dans un VPC, où le traitement s'effectue derrière le pare-feu pour des raisons de conformité ou de souveraineté des données.
- Hybride / Cloud: architectures qui couvrent les deux, permettant de placer l'exécution de manière optimale en fonction de la charge de travail et des exigences de gouvernance.
Chaque Snaplex peut évoluer dynamiquement, ce qui garantit des performances fiables même en cas de charge fluctuante.
Suivi et gouvernance
La visibilité opérationnelle est assurée par SnapLogic Monitor, une console centralisée qui fournit :
- État et santé du pipeline en temps réel
- Mesures d'exécution historiques et suivi des erreurs
- Contrôles d'accès basés sur les rôles pour une administration sécurisée
- Détection d'anomalies assistée par l'IA pour repérer les schémas d'exécution inhabituels
Monitor permet aux responsables informatiques et commerciaux de s'assurer que les pipelines fonctionnent efficacement et en toute sécurité à grande échelle.
La couche IA/agence
L'architecture de SnapLogic est complétée par une intégration agentique : Des agents d'intelligence artificielle qui aident en permanence à construire, optimiser et maintenir les pipelines. Ces agents :
- Proposer des mappings et des transformations dans Designer
- Détecter les inefficacités et proposer des améliorations dans le moniteur
- Adapter les pipelines en fonction de l'évolution des modèles de données, des applications ou des règles commerciales
Plutôt que des intégrations statiques, les pipelines deviennent adaptatifs et s'optimisent d'eux-mêmes, ce qui réduit considérablement les coûts informatiques.
Flexibilité en fonction de la plate-forme
Un principe clé de notre architecture est de découpler la conception des pipelines de leur exécution. Les pipelines conçus dans Designer peuvent être exécutés sur n'importe quel type de Snaplex, qu'il s'agisse d'un cloud, d'un sol ou d'un hybride. Au fur et à mesure que les exigences évoluent (par exemple, les volumes de données augmentent, les attentes en matière de latence se renforcent, des contraintes de conformité apparaissent), le même pipeline peut être réexécuté sur une cible plus appropriée sans qu'il soit nécessaire d'en revoir la conception.
Se préparer à l'IA grâce à une base de données solide
L'architecture de SnapLogic est conçue pour s'adapter. Les pipelines sont modulaires, l'exécution est distribuée et l'IA enrichit chaque étape, de la conception à l'optimisation de l'exécution. En séparant ce que fait un pipeline de l'endroit où il s'exécute, la plateforme offre aux entreprises une base qui peut évoluer avec les exigences technologiques et commerciales.
Prêt à voir comment ça marche ? Contactez-nous dès aujourd'hui pour réserver une démonstration.







