






Wenn wir uns die Landschaft dessen ansehen, was heute als Definition eines modernen Datenstapels gilt, stellen wir bei SnapLogic die Frage: Sind die aktuellen Definitionen modern genug?
Dies ist eine wichtige Frage, denn bei der Entwicklung einer Datenarchitektur wollen Unternehmen vorausschauend sein und an den Datenbedarf der Zukunft denken und nicht nur an den Datenbedarf von heute.
Wenn sie nicht modern genug sind, laufen Unternehmen daher Gefahr, eine Lösung einzusetzen, die ihren Datenanforderungen im gesamten Unternehmen nicht gerecht wird, im Laufe der Zeit ins Stocken gerät (d. h. nicht zukunftssicher ist), die Komplexität durch weitere Tools zum Ausgleich erhöht, die Kosten steigert und die Zeit bis zur Wertschöpfung aus Datenprodukten verlangsamt.
Was macht eine moderne Datenarchitektur aus?
Im Folgenden finden Sie eine kurze Zusammenfassung dessen, was typischerweise bei der Suche nach der Definition eines modernen Datenstapels oder einer modernen Datenarchitektur gefunden wird. Moderne Datenarchitekturen sind:
- Cloud-nativ - gehostet in der Cloud für schnelle Bereitstellung und einfache Skalierbarkeit
- Leichter Zugang zu den Daten für einen breiten Nutzerkreis, der über die IT oder die Technik hinausgeht
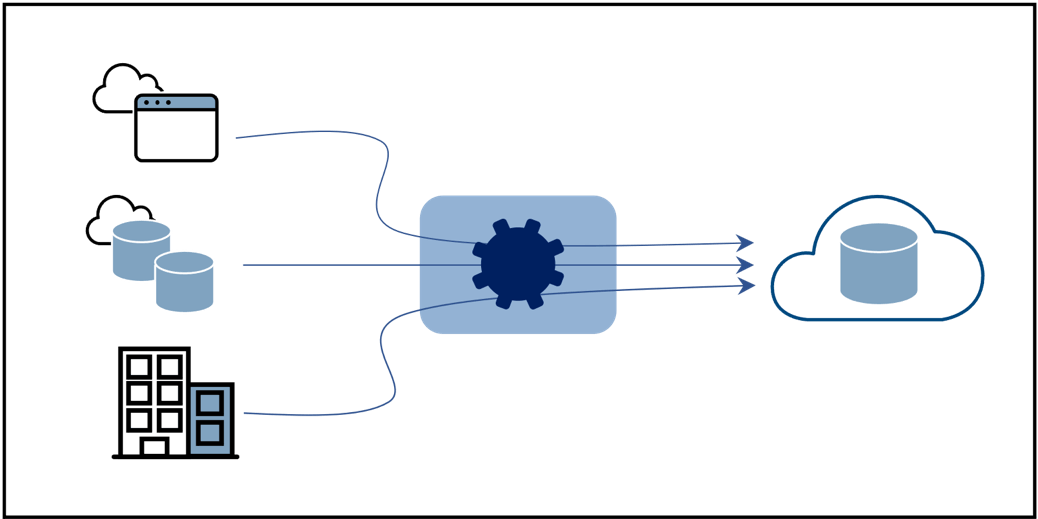
- Fokus auf Datenintegration - alle integrierten Daten werden an ein Cloud Data Warehouse, eine Cloud Data Platform oder einen Data Lake weitergeleitet
- Zentralisierte Bereitstellung - die meisten Anwendungsfälle beziehen sich auf Analysen und Business Intelligence
Dies ist zwar eine solide Liste mit einem repräsentativen Architektur-Blockdiagramm in Abbildung 1, aber sie hat ihre Grenzen und Risiken. Lesen Sie weiter.
Datenintegration allein ist nicht modern genug - Kombinieren Sie App-to-App-Integration
Die Übertragung von Daten in ein Cloud Data Warehouse (CDW) oder eine Cloud-Datenplattform wie BigQuery, Redshift, Snowflake usw. oder in einen Data Lake erhöht zweifellos die Agilität, Schnelligkeit und die Fähigkeit zur schnellen Skalierung von Datenanalyse-Workloads. Die Herausforderung besteht darin, dass Datenanalyse zwar eine dominante Arbeitslast ist, aber nicht die einzige. Nicht alle Anwendungsfälle sind zentralisiert, insbesondere wenn man bedenkt, dass Data Mesh/Data Fabric weiterhin ein heißes Diskussionsthema unter Unternehmensarchitekten ist.
Hinzu kommt, dass Analyse-Workloads ihrem Wesen nach nachproduktiv und nicht operativ sind. Bei operativen Datensystemen handelt es sich um Anwendungen, die Daten auf Datensatzebene bearbeiten oder gemeinsam nutzen (im Gegensatz zur Analyse von Datensätzen), und zwar nahezu in Echtzeit. Die spaltenbasierte Datenintegration eignet sich gut für Analysen, aber nicht so gut für die gemeinsame Nutzung von Daten in Echtzeit, von Anwendung zu Anwendung. Die zeilenbasierte Integration, die die CDW umgeht, ist in der Regel schneller.
Carrie Craig, Director of Enterprise Business Applications bei der WD-40 Company, meint dazu: "Wir übertragen unsere CRM-Daten direkt in unser ERP-System über die SnapLogic-AnwendungApplication Integration , weil es für unsere Datenwissenschaftler schneller und einfacher ist, auf die benötigten Daten zuzugreifen. Für uns ist es ein Wettbewerbsvorteil, über Just-in-Time-Daten für die Entscheidungsfindung zu verfügen."
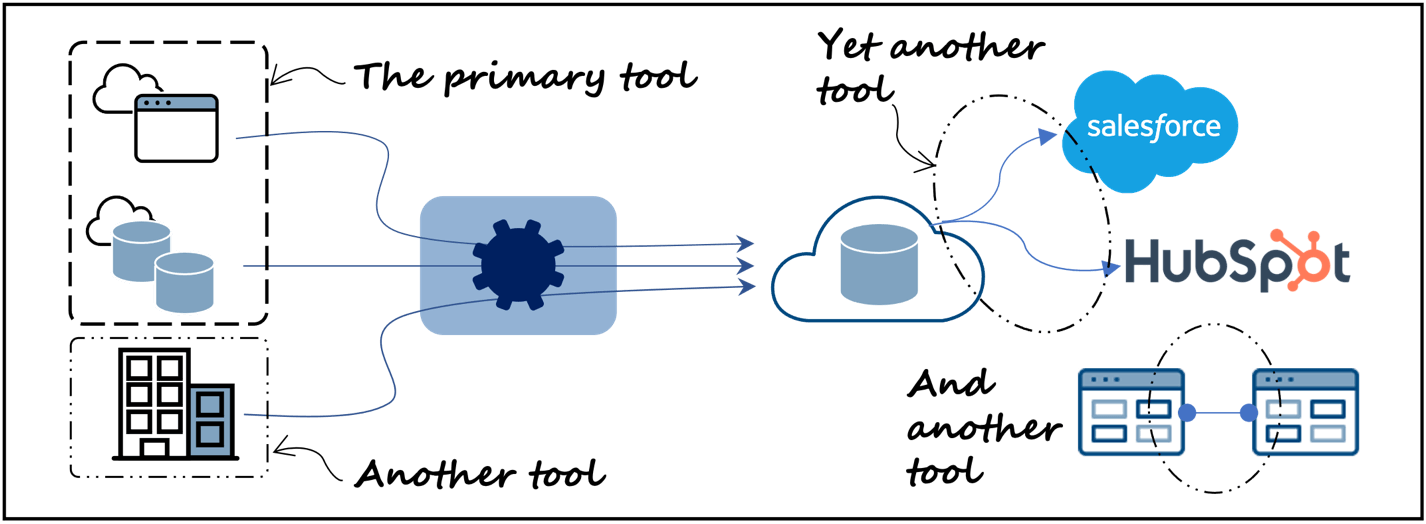
Um dies zu erreichen, müssten Sie ein weiteres Integrationstool von Anwendung zu Anwendung (Abbildung 2, unten rechts) zu Ihrem Stack hinzufügen, wenn Sie Datenintegrationstools wie Fivetran, Matillion, Informatica oder ähnliche verwenden. Dies führt zu einer höheren Komplexität und möglicherweise zu höheren Kosten.
Moderne Datenprodukte mit bidirektionalem Sync - Unkompliziert
Wenn Sie ein Unternehmen sind, das Datenprodukte herstellt, oder eine Analysegruppe, die Daten anreichert, möchten Sie vielleicht, nachdem Sie Ihre Arbeit im Data Warehouse oder Data Lake erledigt haben, das Datenprodukt oder die angereicherten Daten in ein operatives System oder eine Anwendung zurückführen. Nehmen Sie zum Beispiel einen Anwendungsfall, der das Risiko der Abwanderung eines Kunden berechnet. Die Kundendaten werden aus einem CRM-System wie Hubspot oder Salesforce gezogen und dann in das Data Warehouse geladen, um die Abwanderungsanalyse oder andere Anreicherungen durchzuführen. Cool ist, dass die Daten zum Kundenabwanderungsrisiko anschließend wieder in das CRM-System zurückgeführt werden, um Führungskräften und Vertriebsmitarbeitern, die zusätzliche Einblicke in die Kunden erhalten möchten, einen konsistenten Zugriff und eine einheitliche Anzeige zu ermöglichen. Dies ist ein besseres und benutzerfreundlicheres Erlebnis als der Zugriff auf das CRM-System für eine Reihe von Anforderungen und eine separate Anfrage an die IT-Abteilung oder das Datenanalyseteam für den Zugriff auf die Informationen zum Kundenabwanderungsrisiko.
Die Durchführung einer solchen Aufgabe für diesen Anwendungsfall erfordert das Entladen von Daten aus dem Data Warehouse und das anschließende Laden der Daten zurück in das CRM-System, d. h. einen bidirektionalen Synchronisations- oder Reverse-ETL-Auftrag (Extrahieren, Transformieren, Laden) mit anderen Worten. Die moderne Datenarchitektur, wie sie in Abbildung 1 dargestellt ist, würde ein weiteres Tool wie Hightouch, Census oder Hevo erfordern, um dies zu bewerkstelligen (Abbildung 2, oben rechts). Das heißt, wie gehabt, ein weiteres Tool, mehr Komplexität.
Fairerweise muss man sagen, dass sich einige reine Datenintegrations-Tools weiterentwickelt haben, um bidirektionale/reverse-ETL-Anwendungsfälle zu unterstützen. Sie müssen jedoch einen Blick unter die Haube werfen, um zu verstehen, inwieweit die bidirektionale Synchronisierung unterstützt wird.
Verarbeitung von sowohl vor Ort als auch in der Cloud gespeicherten Daten ohne zusätzliche Tools
Es ist eine Sache zu sagen, dass ein moderner Datenstapel oder eine moderne Architektur in der Cloud gehostet wird, aber das bedeutet nicht (oder sollte unserer Meinung nach nicht bedeuten), dass die Daten, mit denen gearbeitet wird, in der Cloud liegen müssen. Moderne Finanzunternehmen, Versicherungsgesellschaften und Behörden haben beispielsweise eine Vielzahl von Anforderungen und verfügen möglicherweise über Sicherheitsrichtlinien, die vorschreiben, dass sensible Daten vor Ort bleiben müssen. Die Übertragung sensibler Daten zur Bearbeitung in die Cloud und die anschließende Rückkehr zu einem lokalen Repository stellt ein Sicherheitsrisiko dar.
Wenn ein in der Cloud gehostetes Datenintegrationstool oder eine Datenplattform Schwierigkeiten hat, in lokale Umgebungen einzudringen, hinter einer Firewall zu arbeiten und Datenoperationen auszuführen, die vor Ort bleiben müssen, wird ein anderes Tool benötigt (Abbildung 2, unten links). Dies erhöht wiederum die Komplexität und kann die Betriebserfahrung verändern.
Eine bessere Lösung ist die Trennung der Cloud-Steuerung von der Ausführung vor Ort innerhalb desselben Integrationstools.
Moderner werden, schneller ausführen mit weniger technischen Schulden und Komplexität
In diesem Blog habe ich drei Bereiche aufgezeigt, in denen ein auf Datenintegration ausgerichteter moderner Stack zu kurz greift und zusätzliche Tools erfordert, was zu mehr technischen Schulden und zusätzlicher Komplexität führt.
Wenn von einem modernen Daten-Stack oder einer modernen Datenarchitektur die Rede ist, dann häufig aus der Perspektive der Datenintegration. Dies ist von Natur aus einschränkend, wenn man bedenkt, welche Reichweite ein moderner Daten-Stack oder eine moderne Datenarchitektur haben muss, um die breiteren Anforderungen moderner Unternehmen in ihren Unternehmen zu erfüllen.
Um Ihre moderne Architektur moderner zu gestalten, kombinieren Sie App-to-App-Integration, bidirektionalen Datenabgleich/Reverse ETL und Funktionen zur Datenausführung vor Ort in derselben Integrationsplattform, anstatt sie als einzelne Tools in Ihrer Datenarchitektur einzusetzen. Die Vorteile sind ein geringerer technischer Aufwand, eine geringere Komplexität, d. h. Einfachheit, und eine schnellere Wertschöpfung aus Integrationen.
Dazu ein Kommentar von Geoff Shakespeare, Chief Operating Officer bei National Broadband Ireland (NBI), einem Unternehmen mit einer ehrgeizigen Initiative zur Versorgung großer Teile des ländlichen Irlands mit Breitbandanschlüssen: "Nachdem wir uns eine Reihe von Integrationslösungen angesehen hatten, organisierten wir einen Eignungstest, bei dem wir die Anbieter baten, innerhalb eines Vormittags eine Funktion zu entwickeln, die eine Postleitzahl nachschlagen und einen negativen oder positiven Wert darüber liefern konnte, ob wir diese Postleitzahl mit Breitband versorgen können. SnapLogic hat diese Aufgabe in beeindruckender Weise in zweieinhalb Stunden erledigt. Die Zeit bis zur Markteinführung ist für dieses Projekt von größter Bedeutung, und SnapLogic hat uns dabei geholfen, die wichtigsten Ziele zu erreichen."
Teil zwei dieser Blogserie ist jetzt erschienen! Wir behandeln zwei weitere wichtige Bereiche, um Ihre modernen Daten moderner zu machen.








