





In unserem letzten Beitrag haben wir uns ausführlich mit Anomaliedetektoren befasst und gezeigt, wie einige einfache Modelle funktionieren würden. Jetzt werden wir eine Pipeline für die Erkennung von Streaming-Anomalien aufbauen.
Für diese Aufgabe werden wir eine getriggerte Pipeline verwenden. Eine getriggerte Pipeline wird instanziiert, sobald eine Anforderung eingeht. Die Instanziierung kann einige Sekunden dauern, weshalb sie nicht für Situationen mit geringer Latenz oder hohem Datenverkehr empfohlen wird. Wenn wir Daten häufiger erhalten oder eine geringere Latenzzeit wünschen, sollten wir eine Ultra-Pipeline verwenden. Eine Ultra-Pipeline wird ständig ausgeführt, so dass die Latenzzeit zwischen Eingabe und Ausgabe deutlich geringer ist.
In diesem Beitrag gehen wir davon aus, dass wir einen Anomaly-Detector-as-a-Service Snap haben. Im nächsten Beitrag werden wir zeigen, wie wir diesen Snap mit Azure ML erstellen. Unsere Pipeline wird wie folgt aussehen:
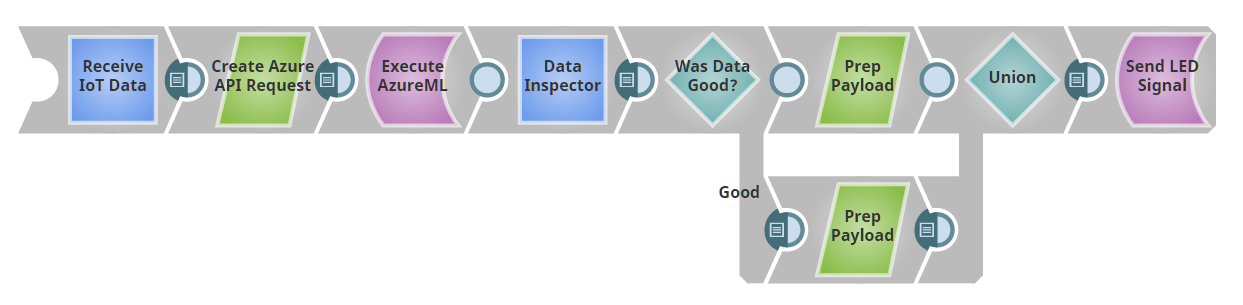
Unser erster Snap dient als REST-Endpunkt, d. h., die Pipeline stellt im Grunde einen Webserver bereit. Wenn Sie eine Nachricht mit einer JSON-Nutzlast an die angegebene URL posten, wird die Ausgabe dieses Snap die gesendete JSON als Dokument sein. (Tatsächlich verwenden wir hier einen Record Replay Snap, um Eingabedaten zwischenzuspeichern. Sobald wir also eine Eingabe an die Pipeline senden, haben wir sie gespeichert und können sie bei der Entwicklung wiederverwenden, ohne ständig neue Daten posten zu müssen).
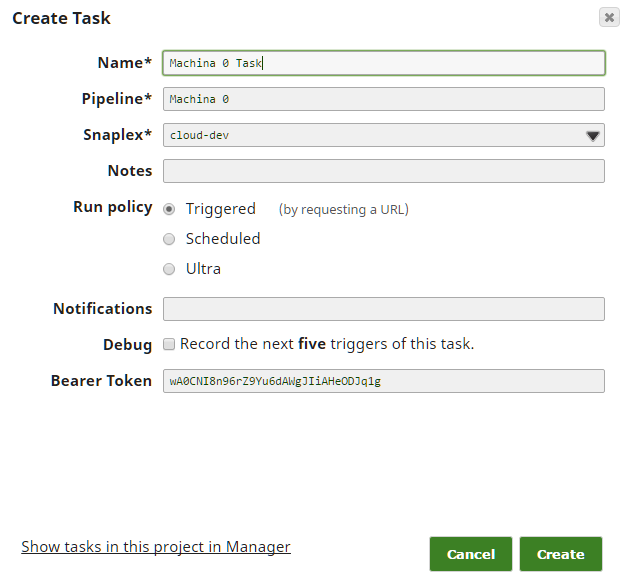
Wenn Sie in SnapLogic verfolgenverfolgen, werden Sie feststellen, dass der Record Replay-Snap keinen Eingang hat, wie auf dem Bild zu sehen ist. Um ihn hinzuzufügen, klicken Sie auf den Snap, auf "Views" und dann auf das Pluszeichen "+" neben Input, um einen Input hinzuzufügen. Als Nächstes, bevor wir es vergessen, richten wir den Triggered Task ein, damit wir POST an diese Pipeline zu senden. Klicken Sie auf die Schaltfläche "Aufgabe erstellen", die unten grün umrandet ist.

Als Nächstes füllen Sie die Felder aus - in den meisten Fällen sollten die Standardeinstellungen funktionieren; vergewissern Sie sich nur, dass Sie als "Ausführungsrichtlinie" die Option "Ausgelöst" gewählt haben.
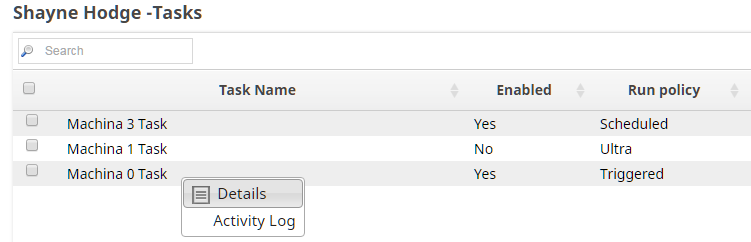
Finally, we need to take a quick detour to Manager to get the URL and Authorization Token for this Task. Drill down on the side navigation pane to Projects -> <Your Project> -> Tasks. In the right hand task pane, click the dropdown arrow and then Details. You’ll be taken to the page with the URL and token you need, as well as a Task Status log. You’ll want to come back here if things seem not to be working right to see if there are failures in the execution of the pipeline.
Jetzt können Sie diese URL und das Authentifizierungstoken nehmen und der Anwendung oder dem Gerät, das Ihnen Daten senden soll, übergeben. Für dieses Projekt haben wir ein Python-Skript erstellt, das nach dem Zufallsprinzip Daten (im JSON-Format) generiert und sie an die Pipeline sendet. Im Allgemeinen ist es am einfachsten, "Stubs" wie dieses zu verwenden zu verwenden und erst dann zur eigentlichen Quelle zu wechseln, wenn Sie wissen, dass alles andere korrekt eingerichtet ist.
Wir speisen die von unserem REST-Endpunkt eingehenden Daten in unseren Blackbox-Anomaliedetektor ein. Der Detektor bewertet jeden Punkt entweder als "gut" oder "schlecht". Wir haben einen Router Snap, der gute und schlechte Punkte über verschiedene Verarbeitungspfade weiterleitet. Wenn Sie die der IoT-Serieverfolgt haben, werden Sie gesehen haben, dass wir eine Pipeline gebaut haben, in der eine LED in einer anderen Farbe blinkt, je nachdem, welche Nutzdaten an sie gepostet werden. Hier haben wir diese Leuchte wiederverwendet, indem wir die "guten" in eine "Farbe: 'grün'"-Nutzlast und die schlechten in eine "Farbe: 'rot'"-Nutzlast umgewandelt und an die Leuchte zurückgeschickt haben.
Wir könnten stattdessen anomale Punkte in einer Datenbank protokollieren, einen Dienst wie PagerDuty auslösen oder eine Meldung in einem Slack-Kanal veröffentlichen. (Oder wir könnten alle diese Möglichkeiten nutzen oder je nach Datum und Tageszeit unterschiedliche Benachrichtigungskanäle wählen). Zu beachten ist, dass diese Pipeline aus zwei Hauptkomponenten besteht: (1) die Fähigkeit, Daten als POST-Endpunkt aufzunehmen und (2) die Fähigkeit, diese Daten an eine REST-API zu übergeben und die Ausgabe wie jedes andere Dokument in SnapLogic zu verarbeiten. Die Snaplogic REST-Snaps ermöglichen es uns, beliebige Webservices wie einen weiteren Snap in einer Pipeline zu behandeln.
Im letzten Teil dieser Serie werfen wir einen Blick in die Black Box der AzureML Anfrage Snap und sehen, wie wir sie implementieren.


