





Microsoft Azure HDInsight ist eine Apache-Hadoop-Distribution, die über die Cloud betrieben wird. Intern nutzt HDInsight die Datenplattform von Hortonworks. HDInsight unterstützt eine große Anzahl von Apache-Big-Data-Projekten wie Spark, Hive, HBase, Storm, Tez, Sqoop, Oozie und viele mehr. Die Suite von HDInsight-Projekten kann über Apache Ambari verwaltet werden.
 In diesem Beitrag werden die Schritte für das Einrichten eines HDInsight-Clusters, das Einrichten von SnapLogic's Hadooplex auf HDInsight und das Erstellen und Ausführen einer Spark-Datenflusspipeline auf HDInsight. Wir beginnen mit dem Einrichten eines HDInsight-Clusters über das MS Azure-Portal.
In diesem Beitrag werden die Schritte für das Einrichten eines HDInsight-Clusters, das Einrichten von SnapLogic's Hadooplex auf HDInsight und das Erstellen und Ausführen einer Spark-Datenflusspipeline auf HDInsight. Wir beginnen mit dem Einrichten eines HDInsight-Clusters über das MS Azure-Portal.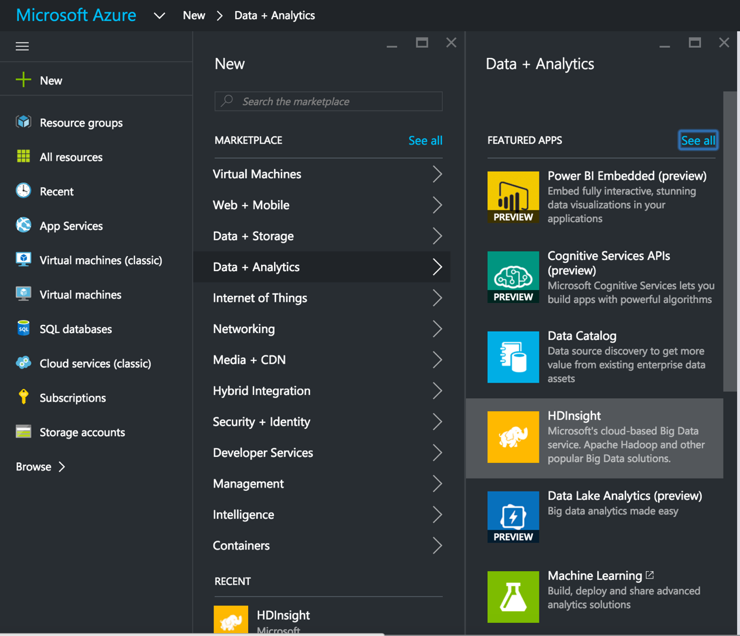
Nachdem Sie HDInsight ausgewählt haben, geben Sie den Clusternamen, den Clustertyp und andere erforderliche Details ein, um den HDInsight-Cluster zu starten. Für die Ausführung von Spark-Pipelines wählen Sie Clustertyp als Spark, Betriebssystem als Linux und Version als Spark 1.6.1 (HDI 3.4).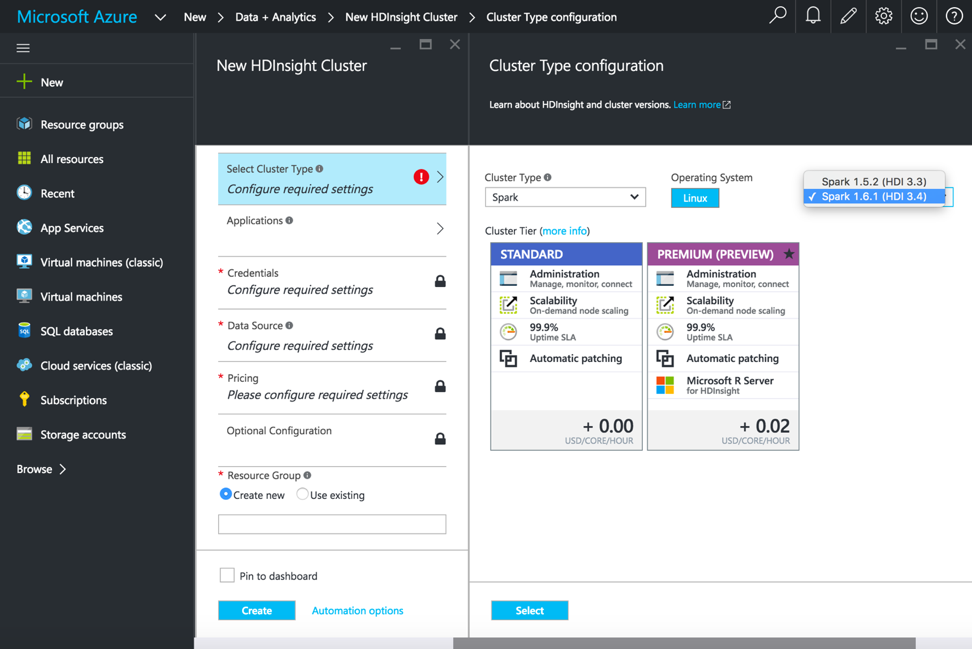
Sobald der HDInsight-Cluster eingerichtet ist und läuft, melden Sie sich an der Konsole an, um einen SnapLogic Hadoooplex zu erstellen und zu konfigurieren.
Vergewissern Sie sich über das Dashboard, dass der Hadooplex-Master und der Knoten in der SnapLogic-Kontrollebene registriert sind.
An diesem Punkt sind wir bereit, eine Spark-Pipeline auf HDInsight zu erstellen und auszuführen. Hier werde ich eine sehr einfache Spark-Pipeline erstellen, um zu demonstrieren, wie eine Datei gelesen und mit einer einfachen Transformation im Azure-Speicher-Blob abgelegt wird.
Von der SnapLogic-Entwickler Fenster erstelle ich eine neue Spark-Pipeline.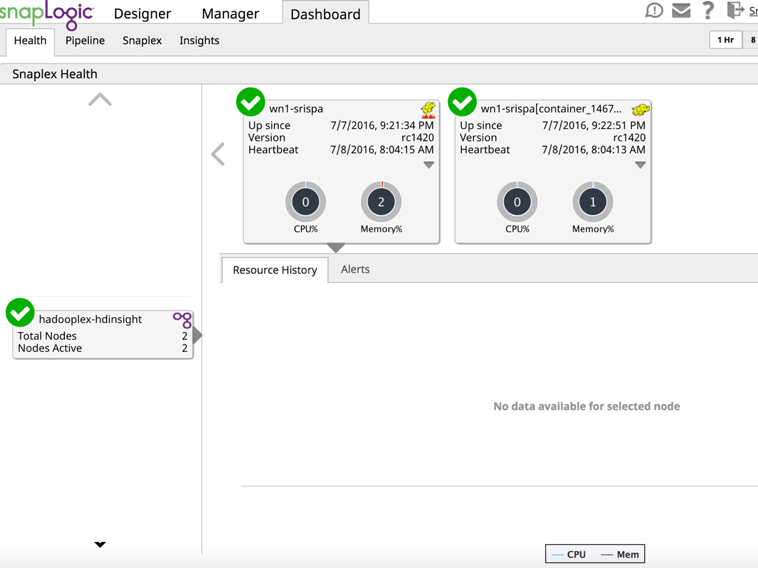
An diesem Punkt sind wir bereit, eine Spark-Pipeline auf HDInsight zu erstellen und auszuführen. Hier werde ich eine sehr einfache Spark-Pipeline erstellen, um zu demonstrieren, wie eine Datei gelesen und mit einer einfachen Transformation im Azure-Speicher-Blob abgelegt wird.
Im SnapLogic Designer-Fenster erstelle ich eine neue Spark-Pipeline.
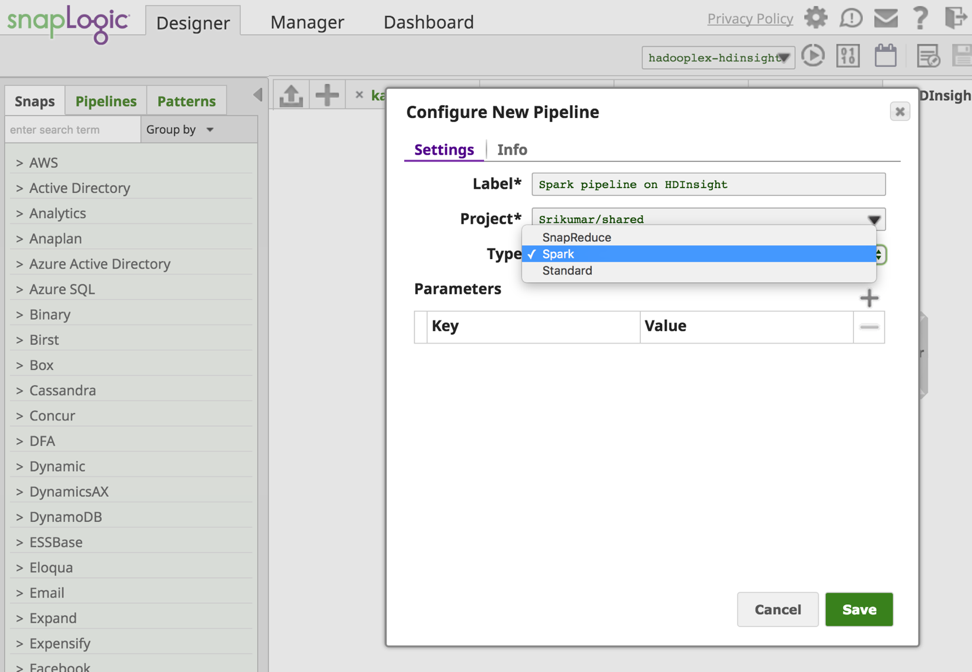
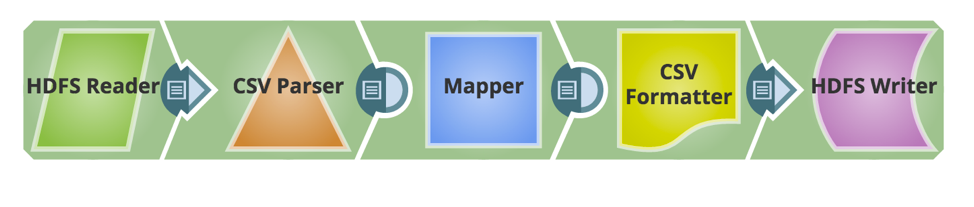
Jetzt werden die erforderlichen Snaps hinzugefügt, um die Pipeline zu erstellen. Nachfolgend sehen Sie den Schnappschuss der Pipeline.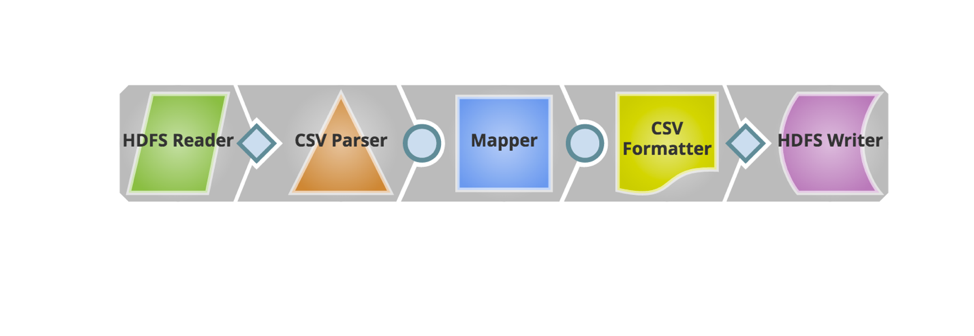
HDInsight verwendet Azure Blob Storage als Big Data-Speicher für HDFS. SnapLogic unterstützt das Windows Azure Storage Blob (WASB)-Protokoll, eine Erweiterung, die auf der HDFS-API aufbaut.
Der nächste Schritt ist die Einrichtung eines Azure-Storage-Kontos und das Lesen/Schreiben von Daten aus dem Azure-Storage-Blob mit dem HDFS Reader & Writer.
Auf der Registerkarte "Konten" von HDFS Reader (oder HDFS Writer) klicken wir auf die Schaltfläche "Konto hinzufügen", um die Kontodetails zu konfigurieren. Wählen Sie unter "Create Account Options" den Speicherort für die Kontoeinrichtung aus, wählen Sie den Kontotyp "Azure Storage" und klicken Sie auf die Schaltfläche "OK". 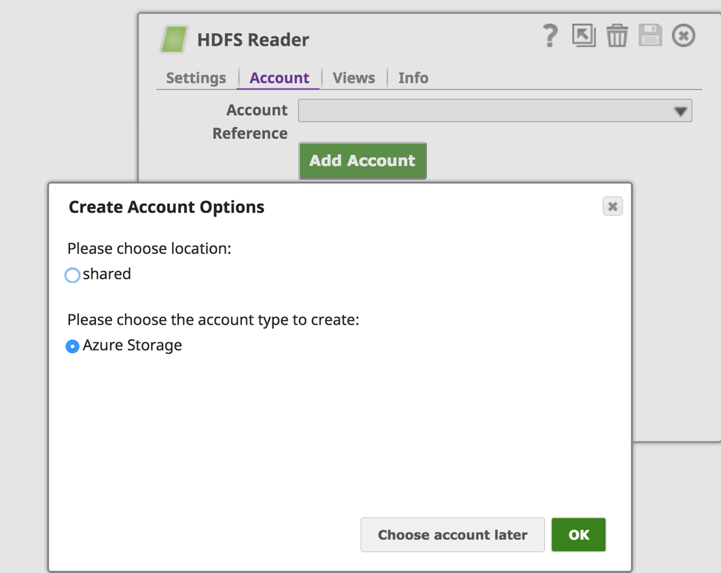
Geben Sie im Dialogfeld "Konto erstellen" den Namen des Azure-Kontos und den primären Zugriffsschlüssel ein. Diese Angaben finden Sie im Azure-Portal -> Speicherkonto -> Einstellungen -> Zugriffsschlüssel
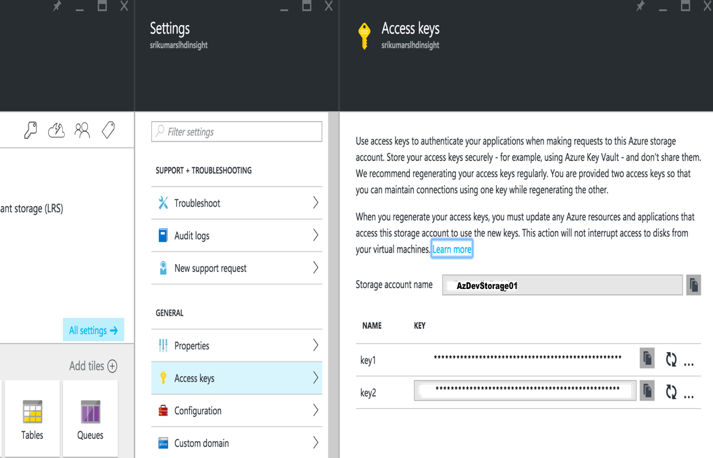
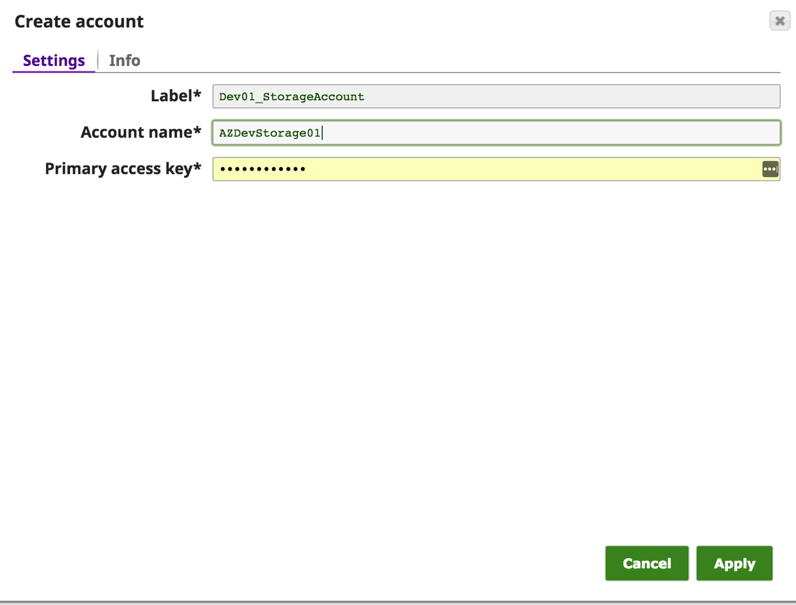
Speichern Sie das Konto, und jetzt können Sie mit wasb:///containername/path_to_file auf Daten aus dem Azure-Blob zugreifen
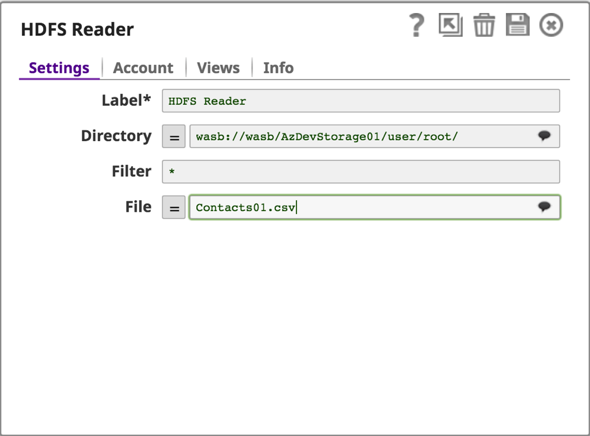
Konfigurieren Sie den Rest der Pipeline, um die Daten zu transformieren und in einem Ausgabeordner auf dem Azure Storage Blob zu landen.
Lassen Sie uns nun die Pipeline validieren und ausführen. Der folgende Screenshot zeigt die erfolgreiche Validierung und Ausführung der Spark-Pipeline.
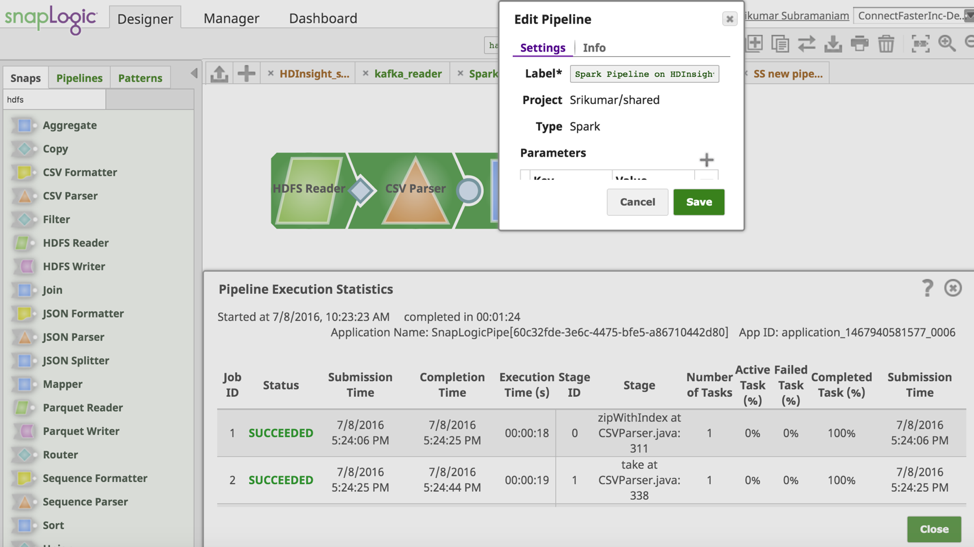
Durch die Unterstützung von HDInsight können Sie die Leistung der SnapLogic Elastic Integration Platform nutzen, um Ihre Integrationen auf der Microsoft Azure-Plattform zu beschleunigen. Erfahren Sie mehr über SnapLogic für Microsoft Azure hier.