





One of SnapLogic’s core design principles is simple: a pipeline should run on the right execution platform for the job. Whether the requirement is low-latency event streaming, high-volume data movement, or complex transformations, the architecture needs to adapt.
This post outlines how SnapLogic pipelines work internally, how execution is managed across different environments, and how AI is now embedded into the fabric of the platform.
Document-oriented processing
All data processed in SnapLogic pipelines is internally represented in JSON format, a model we call document-oriented processing. Even flat, record-based inputs are normalized to JSON, enabling seamless support for both flat and hierarchical data structures.
Pipelines are composed of Snaps, modular components that encapsulate connectivity or transformation logic. Snaps can:
- Connect to applications, databases, APIs, or files
- Transform or enrich records (filter, map, join, aggregate)
- Orchestrate workflows across complex systems
These pipelines are constructed visually in the SnapLogic Designer, our low-code, browser-based development interface. Designer allows architects and engineers to drag, drop, and configure Snaps, while also providing real-time validation, auto-suggestions, and AI-driven assistance for faster development.
Streaming vs. accumulating pipelines
We classify pipelines as either streaming or accumulating:
- Streaming pipelines process each document independently, minimizing memory use and supporting low-latency, high-throughput workloads
- Accumulating pipelines require all input to be collected before output (e.g., sort, join, aggregate), which demand more memory but enable complex operations across large datasets
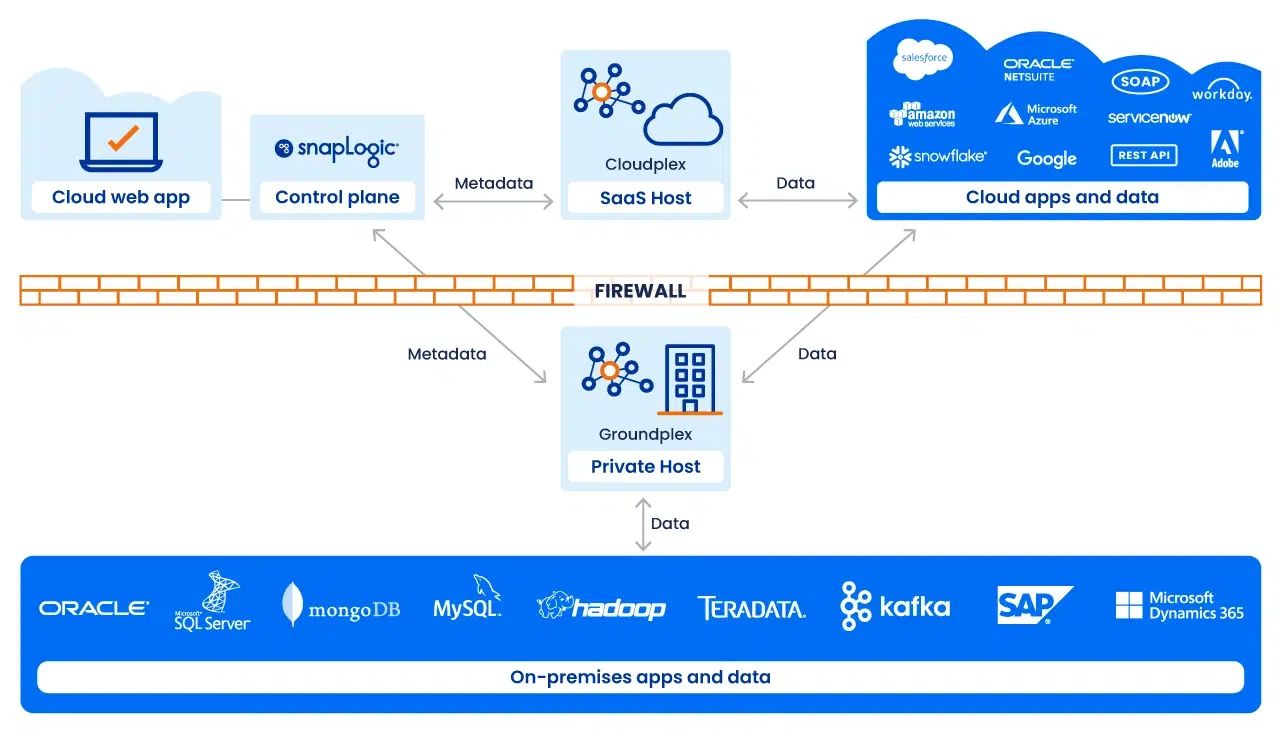
Execution with Snaplex
Pipeline execution is handled by a Snaplex, SnapLogic’s scalable execution fabric. A Snaplex consists of processing nodes or containers that run pipelines.
We support multiple deployment models:
- Cloudplex: a fully managed, auto-scaling Snaplex hosted by SnapLogic. Ideal for cloud-to-cloud integrations
- Groundplex: an on-premises or VPC-deployed Snaplex, where processing occurs behind the firewall for compliance or data sovereignty needs
- Hybrid / Multi-Cloud: architectures that span both, enabling execution to be placed optimally based on workload and governance requirements
Each Snaplex can dynamically scale, ensuring reliable performance even under fluctuating load.
Monitoring and governance
Operational visibility is handled through SnapLogic Monitor, a centralized console that provides:
- Real-time pipeline status and health
- Historical execution metrics and error tracking
- Role-based access controls for secure administration
- AI-assisted anomaly detection to flag unusual execution patterns
Monitor gives both IT and business stakeholders confidence that pipelines are running securely and efficiently at scale.
The AI/Agentic layer
SnapLogic’s architecture is augmented by agentic integration: AI agents that continuously assist in building, optimizing, and maintaining pipelines. These agents:
- Suggest mappings and transformations in Designer
- Detect inefficiencies and propose improvements in Monitor
- Adapt pipelines as data models, applications, or business rules evolve
Rather than static integrations, pipelines become adaptive and self-optimizing, significantly reducing IT overhead.
Platform-agnostic flexibility
A key principle of our architecture is decoupling pipeline design from execution. Pipelines built in Designer can execute on any Snaplex type, whether cloud, ground, or hybrid. As requirements shift (eg, data volumes grow, latency expectations tighten, compliance constraints emerge), the same pipeline can be re-executed on a more suitable target without redesign.
Get AI-ready with a strong data foundation
SnapLogic’s architecture is designed for adaptability. Pipelines are modular, execution is distributed, and AI augments every stage from design to runtime optimization. By separating what a pipeline does from where it runs, the platform gives enterprises a foundation that can evolve with both technology and business demands.
Ready to see how it works? Contact us today to book a demo.







