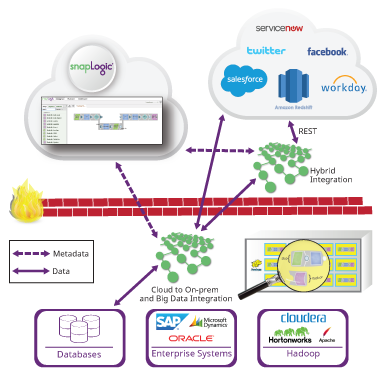
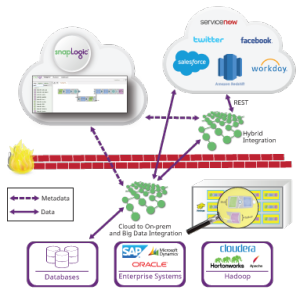
 Uno degli obiettivi di SnapLogic è far coincidere i requisiti di esecuzione del flusso di dati con una piattaforma di esecuzione adeguata. Piattaforme di dati diverse offrono vantaggi diversi. L'obiettivo di questo post è spiegare la natura delle pipeline di flusso di dati e come scegliere l'architettura di integrazione dei dati più adatta. Oltre a classificare le pipeline, spiegherò i target di esecuzione attualmente supportati e il supporto previsto per Apache Spark.
Uno degli obiettivi di SnapLogic è far coincidere i requisiti di esecuzione del flusso di dati con una piattaforma di esecuzione adeguata. Piattaforme di dati diverse offrono vantaggi diversi. L'obiettivo di questo post è spiegare la natura delle pipeline di flusso di dati e come scegliere l'architettura di integrazione dei dati più adatta. Oltre a classificare le pipeline, spiegherò i target di esecuzione attualmente supportati e il supporto previsto per Apache Spark.
Innanzitutto, alcune premesse. Tutti i dati elaborati dalle pipeline SnapLogic sono gestiti in modo nativo in un formato JSON interno. Si tratta di un'elaborazione orientata ai documenti. Anche i dati piatti e orientati ai record vengono convertiti in JSON per l'elaborazione interna. Questo ci permette di gestire senza problemi sia i dati piatti che quelli gerarchici. Le pipeline sono costruite a partire da Snap. Ogni Snap incapsula una specifica applicazione o funzionalità tecnologica. Gli snap sono collegati tra loro per eseguire un processo di flusso di dati. Le pipeline si costruiscono con il nostro Designer visivo. Alcuni Snap forniscono connettività, come la connessione a database o ad applicazioni cloud . Alcuni Snaps consentono la trasformazione dei dati, come il filtraggio dei documenti, l'aggiunta o la rimozione di campi o la modifica di campi. Esistono anche Snaps che eseguono operazioni più complesse come ordinamento, unione e aggregazione.
Data questa impostazione, possiamo classificare le pipeline in due tipi: in streaming e in accumulo. In una pipeline di streaming, i documenti possono scorrere in modo indipendente. L'elaborazione di un documento non dipende da quella di un altro documento che scorre nella pipeline. Queste pipeline di streaming hanno bassi requisiti di memoria perché i documenti possono uscire dalla pipeline una volta raggiunto l'ultimo Snap. Al contrario, una pipeline ad accumulo richiede che tutti i documenti della sorgente di input siano raccolti prima che i documenti risultanti possano essere emessi da una pipeline. Le pipeline con sort, join e aggregate sono pipeline ad accumulazione. In alcuni casi, una pipeline può essere parzialmente ad accumulo. Tali pipeline ad accumulo possono avere requisiti di memoria elevati, a seconda del numero di documenti provenienti da una sorgente di input.
Passiamo ora alle piattaforme di esecuzione. SnapLogic dispone di una piattaforma interna di elaborazione dei dati chiamata Snaplex. Considerate uno Snaplex come un insieme di nodi o contenitori di elaborazione che possono eseguire le pipeline di SnapLogic. Esistono diversi tipi di Snaplex:
- Un Cloudplex è uno Snaplex ospitato nel sito cloud e in grado di autoscalarsi all'aumentare del carico della pipeline.
- Un Groundplex è un insieme fisso di nodi installati in sede o in un VPC del cliente. Con un Groundplex, i clienti possono eseguire tutta l'elaborazione dei dati dietro il loro firewall, in modo che i dati non escano dalla loro infrastruttura.
Stiamo anche ampliando il nostro supporto per le piattaforme di dati esterne. Abbiamo recentemente rilasciato la nostra tecnologia Hadooplex che consente ai clienti SnapLogic di utilizzare Hadoop come target di esecuzione per le pipeline SnapLogic. Un Hadooplex sfrutta YARN per pianificare i container Snaplex sui nodi Hadoop al fine di eseguire le pipeline. In questo modo, possiamo autoscalare all'interno di un cluster Hadoop. Recentemente abbiamo introdotto SnapReduce 2.0, che consente a un Hadooplex di tradurre le pipeline SnapLogic in lavori MapReduce. L'utente costruisce una pipeline SnapReduce designata e specifica i file HDFS, l'input e l'output. Queste pipeline vengono compilate in lavori MapReduce da eseguire su insiemi di dati molto grandi che risiedono in HDFS. (Guardate la dimostrazione nel nostro recente webinarcloud e big data analytics).
Infine, come abbiamo annunciato la scorsa settimana nell'ambito dell'annuncio di Cloudera sullo streaming in tempo reale, abbiamo iniziato a lavorare sul supporto di Spark come piattaforma di big data target. Sparkplex sarà in grado di utilizzare l'ampia connettività di SnapLogic per portare i dati dentro e fuori gli RDD (Resilient Distributed Datasets) di Spark. Inoltre, in modo simile a SnapReduce, consentiremo agli utenti di compilare le pipeline di SnapLogic in codici Spark in modo che le pipeline possano essere eseguite come lavori Spark. Supporteremo lavori Spark sia in streaming che in batch. Includendo Spark nel supporto della nostra piattaforma di dati, offriremo ai nostri clienti una serie completa di opzioni per l'esecuzione delle pipeline.
La scelta della giusta piattaforma di big data dipende da molti fattori: dimensione dei dati, requisiti di latenza, connettività e tipo di pipeline (streaming o accumulo). Ecco alcune linee guida per la scelta di una particolare piattaforma di integrazione dei big data:
Cloudplex
- Cloud-acloud flusso di dati
- Streaming di documenti illimitati
- Pipeline di accumulo in cui i dati accumulati possono essere inseriti nella memoria del nodo
Groundplex
- Flusso di dati terra-terra, terra-cloud e cloud terra-terra
- Streaming di documenti illimitati
- Pipeline di accumulo in cui i dati accumulati possono essere inseriti nella memoria del nodo
Hadooplex
- Flusso di dati terra-terra, terra-cloud e cloud terra-terra
- Streaming di documenti illimitati
- Le pipeline di accumulo possono operare su dati di dimensioni arbitrarie tramite MapReduce
Sparkplex
- Flusso di dati terra-terra, terra-cloud e cloud terra-terra
- Consentire la connettività Spark a tutti gli account SnapLogic
- Streaming di documenti illimitati
- Le pipeline di accumulo possono operare su dati di dimensioni tali da essere contenuti nella memoria del cluster Spark.
 Si noti che il lavoro recente della comunità Spark ha aumentato il supporto per i calcoli out-of-core, come l'ordinamento. Ciò significa che le pipeline di accumulo che attualmente sono adatte solo per l'esecuzione di MapReduce possono essere supportate in Spark man mano che il supporto di Spark out-of-core diventa più generale. Hadooplex e Sparkplex hanno aggiunto vantaggi di esecuzione affidabili, in modo da garantire il completamento delle pipeline di lunga durata.
Si noti che il lavoro recente della comunità Spark ha aumentato il supporto per i calcoli out-of-core, come l'ordinamento. Ciò significa che le pipeline di accumulo che attualmente sono adatte solo per l'esecuzione di MapReduce possono essere supportate in Spark man mano che il supporto di Spark out-of-core diventa più generale. Hadooplex e Sparkplex hanno aggiunto vantaggi di esecuzione affidabili, in modo da garantire il completamento delle pipeline di lunga durata.
L'obiettivo di SnapLogic è quello di consentire ai clienti di creare ed eseguire pipeline di flussi di dati arbitrari sulla piattaforma di dati più appropriata. Inoltre, forniamo un'interfaccia grafica semplice e coerente per lo sviluppo di pipeline che possono essere eseguite su qualsiasi piattaforma supportata. Il nostro approccio agnostico alla piattaforma disaccoppia le specifiche di elaborazione dei dati dall'esecuzione dell'elaborazione dei dati. Quando il volume dei dati aumenta o i requisiti di latenza cambiano, la stessa pipeline può essere eseguita su dati più grandi e a una velocità maggiore semplicemente cambiando la piattaforma di destinazione dei dati. In definitiva, SnapLogic vi permette di adattarvi ai vostri requisiti di dati e non vi vincola a una specifica piattaforma di big data.