





Un modello comune a molte aziende per popolare un data lake basato su Hadoop è quello di ottenere i dati da database relazionali e data warehouse preesistenti. Quando si pianifica l'ingestione dei dati nel data lake, una delle considerazioni principali è determinare come organizzare una pipeline di ingestione dei dati e consentire ai consumatori di accedere ai dati. Hive e Impala forniscono un'infrastruttura di dati in cima a Hadoop - comunemente chiamata SQL on Hadoop - che fornisce una struttura ai dati e la possibilità di interrogare i dati utilizzando un linguaggio simile a SQL.
Prima di iniziare a popolare i dati nei database/schemi e nelle tabelle di Hive, è necessario considerare due aspetti fondamentali:
- Quali formati di archiviazione dei dati utilizzare per l'archiviazione dei dati? (HDFS supporta diversi formati di dati per i file, come SequenceFile, RCFile, ORCFile, AVRO, Parquet e altri).
- Quali sono le opzioni di compressione ottimali per i file memorizzati su HDFS? (Gli esempi includono gzip, LZO, Snappy e altri).
Quindi, quando si progettano gli schemi del database Hive, in genere ci si trova di fronte a quanto segue:
- Creare lo schema del database Hive come lo schema del database relazionale. Ciò consente di inserire rapidamente i dati in Hive con un impegno minimo per la mappatura e le trasformazioni nell'ambito delle pipeline del flusso di dati di inserimento.
- Creare un nuovo schema di database diverso dallo schema del database relazionale. Ciò consente di riprogettare lo schema del database Hive e di eliminare alcune delle carenze dell'attuale schema del database relazionale. Questo aumenta anche l'impegno per la mappatura e la trasformazione dei dati nell'ambito delle pipeline del flusso di dati in ingresso.
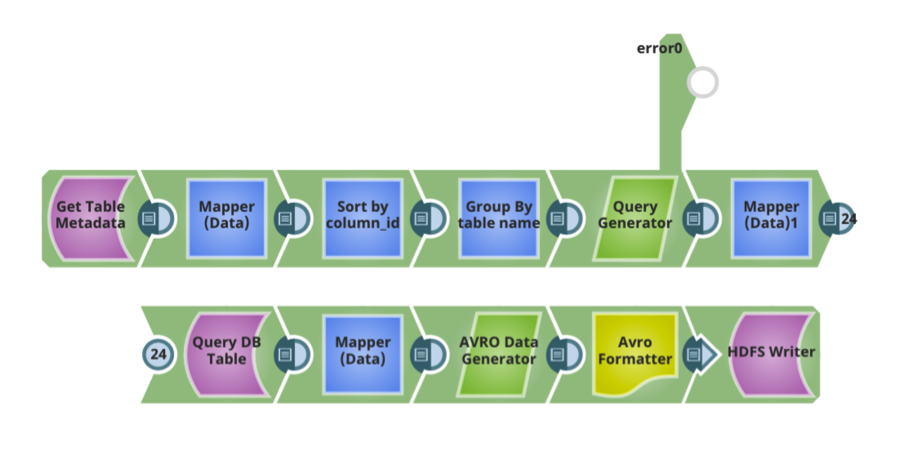 In genere, lo schema di Hive viene creato in modo simile allo schema del database relazionale. Una volta che lo schema di Hive, il formato dei dati e le opzioni di compressione sono stati definiti, ci sono ulteriori configurazioni di progettazione per spostare i dati nel data lake attraverso una pipeline di ingestione dei dati:
In genere, lo schema di Hive viene creato in modo simile allo schema del database relazionale. Una volta che lo schema di Hive, il formato dei dati e le opzioni di compressione sono stati definiti, ci sono ulteriori configurazioni di progettazione per spostare i dati nel data lake attraverso una pipeline di ingestione dei dati:
- La capacità di analizzare i metadati di un database relazionale, come le tabelle, le colonne di una tabella, i tipi di dati per ogni colonna, le chiavi primarie/privilegiate, gli indici, ecc. Ogni database relazionale fornisce un meccanismo per interrogare queste informazioni. Queste informazioni consentono di progettare pipeline di flusso di dati di ingest efficienti.
- I formati di dati utilizzati hanno in genere uno schema associato. Ad esempio, se si utilizza AVRO, è necessario definire uno schema AVRO. Una considerazione fondamentale è la possibilità di generare automaticamente lo schema in base ai metadati del database relazionale o lo schema AVRO per le tabelle di Hive in base allo schema delle tabelle del database relazionale.
- La possibilità di generare automaticamente tabelle Hive per le tabelle del database relazionale di origine.
- Quando si progettano le pipeline del flusso di dati di ingest, considerare quanto segue:
- La capacità di eseguire automaticamente tutte le mappature e le trasformazioni necessarie per spostare i dati dal database relazionale di origine alle tabelle Hive di destinazione.
- Capacità di condividere automaticamente i dati per spostare in modo efficiente grandi quantità di dati.
- La capacità di parallelizzare l'esecuzione su più nodi di esecuzione.
Le attività di cui sopra sono modelli di ingegneria dei dati, che incapsulano le migliori pratiche per gestire il volume, la varietà e la velocità dei dati.
Nel prossimo post, scriverò di un approccio pratico su come utilizzare questi pattern con la piattaforma di integrazione dei big data di SnapLogic come servizio, senza la necessità di scrivere codice. Nel frattempo, per saperne di più sull'integrazione dei big data, visitate questo sito e non perdete l'occasione di leggere altri post sulle pipeline di ingestione dei dati.
Prasad Kona è un Big Data Enterprise Architect e fa parte del team di integrazione dei big data di SnapLogic.

