Di Pavan Venkatesh
Flussi di dati con Confluent e migrazione a Hadoop: Nel mio precedente post sul blog, ho spiegato come le future tendenze di movimento dei dati saranno. In questo post, approfondirò alcune delle cose interessanti che abbiamo annunciato come parte della release Snaps dell'inverno 2017 (4.8). In questo modo affronteremo anche le future tendenze di movimento dei dati per i clienti che desiderano spostare i dati su cloud da sistemi diversi o migrare verso Hadoop.
I punti salienti della versione invernale 2017 (4.8) includono:
- Supporto di Confluent Kafka - Un sistema di messaggistica distribuita per lo streaming dei dati
- Da Teradata a Hadoop - Un modo semplice e veloce per migrare i dati
- Miglioramenti al Teradata Snap Pack: Sul fronte del TPT, i clienti possono caricare/aggiornare/cancellare rapidamente i dati in Teradata
- RedShift Multi-Execute Snap - Consente l'esecuzione sequenziale di più istruzioni, in modo che i clienti possano mantenere la logica aziendale.
- Miglioramenti al pacchetto Snap di MongoDB (Delete e Update) e al pacchetto Snap di DynamoDB (Delete e Delete-item)
- Miglioramenti all'output di Workday Read - Ora è più facile per i sistemi a valle consumare i dati.
- Miglioramenti di Netsuite Snap Pack - Gli utenti possono ora inviare operazioni asincrone
- Miglioramenti delle funzioni di sicurezza - Incluso SSL per MongoDB Snap Pack e invalidazione dei pool di connessione al database quando vengono modificate le proprietà dell'account.
- Gli utenti possono ora configurare una dimensione del buffer in Snap, in modo che i blocchi più grandi vengano inviati rapidamente a S3.
Pacchetto snap Confluent Kafka
Kafka è un sistema di messaggistica distribuita basato sul modello publish/subscribe con un elevato throughput e scalabilità. Viene utilizzato principalmente per l'ingestione di dati da più fonti e il successivo invio a più sistemi a valle. I casi d'uso includono il monitoraggio delle attività dei siti web, l'analisi delle frodi, l'aggregazione dei log, l'analisi delle vendite e altri. Confluent è l'azienda che fornisce le funzionalità e le offerte aziendali per Kafka open source.
Qui a SnapLogic abbiamo realizzato gli snap Kafka Producer e Consumer come parte del Confluent Snap Pack. Un approfondimento sull'architettura di Kafka e sul suo funzionamento sarà un buon passo avanti prima di entrare nei dettagli dello Snap Pack o della pipeline.
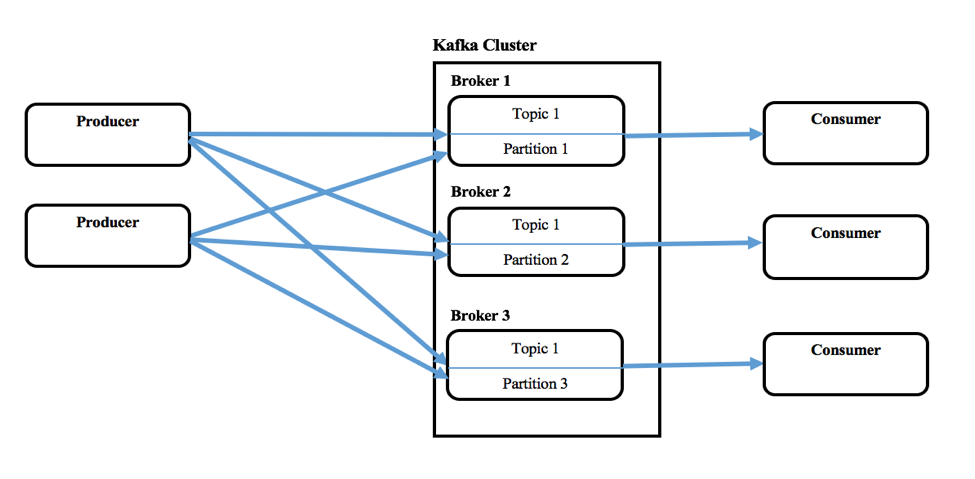
Kafka è costituito da produttori singoli o multipli che possono produrre messaggi da uno o più sistemi a monte, e da consumatori singoli o multipli che consumano messaggi come parte di sistemi a valle. Un cluster Kafka è costituito da uno o più server chiamati Broker. I messaggi (chiave e valore o solo il valore) vengono inseriti in astrazioni di livello superiore chiamate Argomenti. Ogni argomento può contenere più messaggi provenienti da diversi produttori. L'utente può anche definire argomenti diversi per nuove categorie di messaggi. I produttori scrivono i messaggi negli argomenti e i consumatori li consumano da uno o più argomenti. Inoltre, gli argomenti sono partizionati, replicati e persistenti tra i broker. I messaggi nei Topic sono ordinati all'interno di una partizione e ognuno di essi ha un numero ID sequenziale chiamato offset. Zookeeper di solito mantiene questi offset, ma Confluent chiama il kernel di coordinamento.
Kafka permette anche di configurare un gruppo di consumatori di cui fanno parte più consumatori, quando si consuma da un argomento.
Con oltre 400 Snap che supportano vari prodotti on-prem (database relazionali, file, database nosql e altri) e cloud (Netsuite, SalesForce, Workday, RedShift, Anaplan e altri), Snaplogic Elastic Integration Cloud in combinazione con Confluent Kafka Snap Pack sarà una combinazione potente per spostare i dati a diversi sistemi in modo veloce e in streaming. I clienti possono ottenere vantaggi e generare risultati di business in modo rapido.
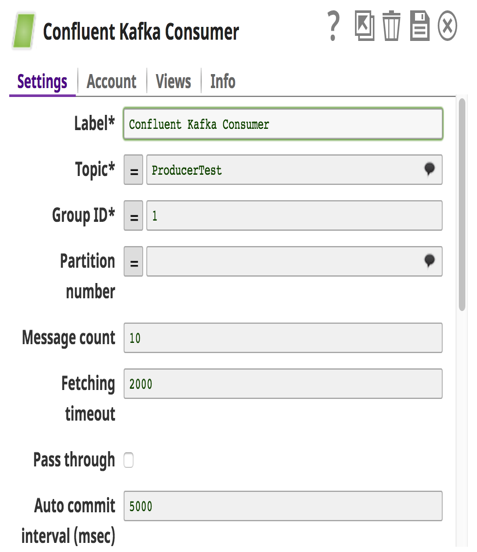
Per quanto riguarda il Confluent Kafka Snap Pack, supportiamo la versione 3.0.1 di Confluent (Kafka v0.9). Questi Snap astraggono le complessità e gli utenti devono solo fornire i dettagli di configurazione per costruire una pipeline che sposta i dati in modo semplice. Una cosa da notare è che quando in una pipeline vengono utilizzati più Consumer Snap e sono stati configurati con lo stesso gruppo di consumatori, a ogni Consumer Snap verrà assegnato un sottoinsieme diverso di partizioni nel Topic.
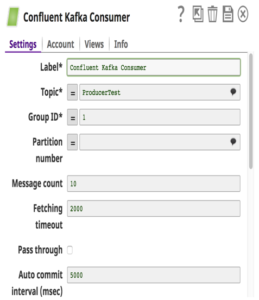
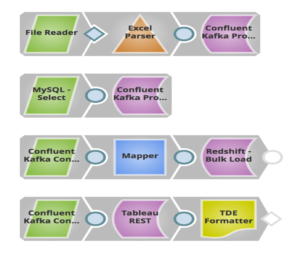
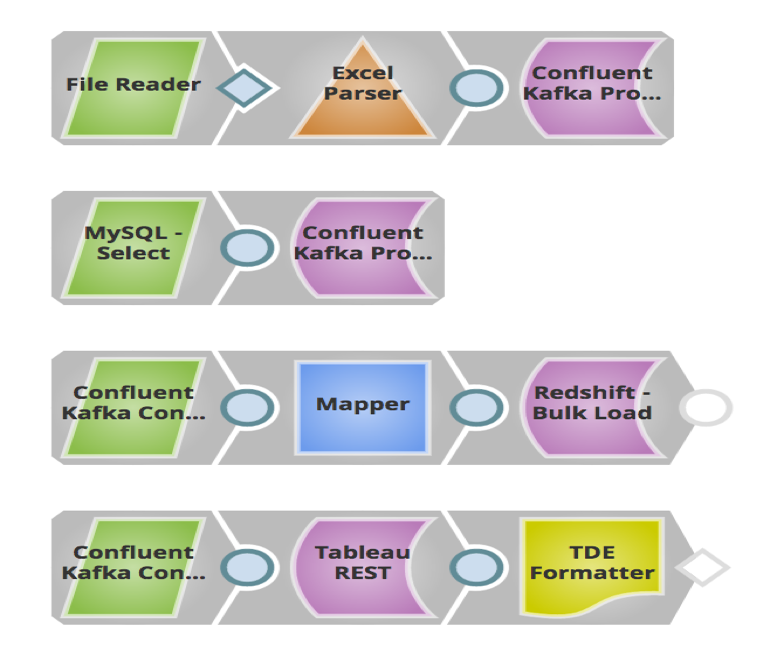
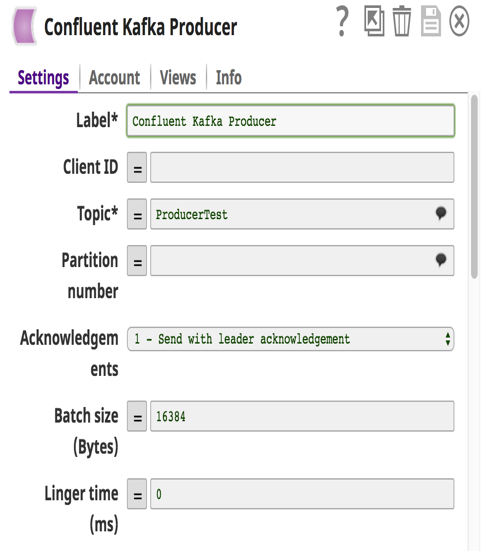
Nell'esempio precedente, ho costruito una pipeline in cui i lead di vendita (messaggi) memorizzati in file locali e MySQL vengono inviati a un Topic in Confluent Kafka tramite Confluent Kafka Producer Snap. Il sistema a valle Redshift consumerà questi messaggi da quel Topic tramite il Confluent Kafka Consumer Snap e li caricherà in blocco su RedShift per esigenze storiche o di auditing. Questi messaggi vengono inviati anche a Tableau come altro consumatore per eseguire analisi sul numero di lead generati quest'anno, in modo che il cliente possa confrontarli con quelli dell'anno scorso.
Migrazioni semplici da Teradata a Hadoop
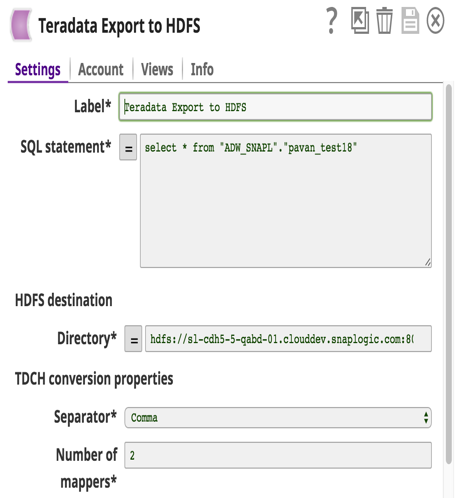
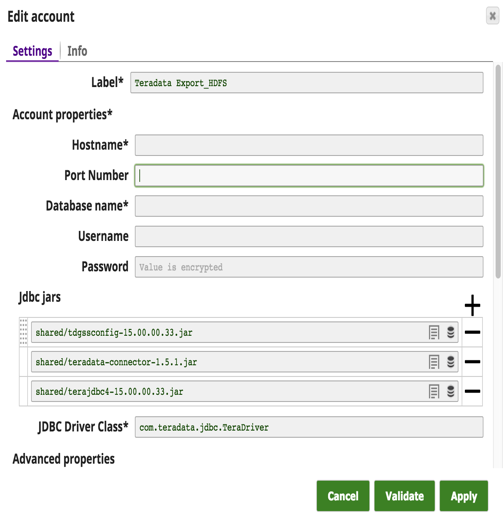
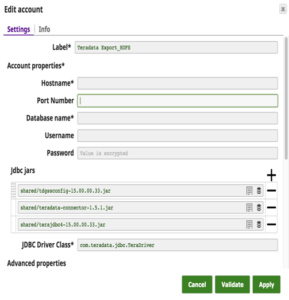
C'è stato un grande cambiamento: i clienti stanno passando dalle costose soluzioni Teradata ad Hadoop o ad altri data warehouse. Finora non esisteva una soluzione semplice per trasferire grandi quantità di dati da Teradata a Hadoop. Con questa release abbiamo sviluppato Teradata Export to HDFS Snap con due obiettivi in mente: 1) facilità d'uso e 2) alte prestazioni. Questo Snap utilizza il Teradata Connector for Hadoop (TDCH v1.5.1). I clienti devono solo scaricare questo connettore dal sito web di Teradata. Teradata oltre ai normali jdbc jar. Non è richiesta alcuna installazione né sui nodi Teradata né su quelli Hadoop.
TDCH utilizza MapReduce (MR) come motore di esecuzione: le query vengono inviate a questo framework e i processi distribuiti lanciati dal framework MapReduce effettuano connessioni JDBC al database Teradata. I dati recuperati vengono caricati direttamente nella posizione HDFS definita. Il grado di parallelismo di questi lavori TDCH è definito dal numero di mapper (una configurazione Snap) utilizzati dal lavoro MapReduce. Il numero di mapper definisce anche il numero di file creati nella posizione HDFS.
Di seguito sono riportati i dettagli dell'account Snap con una query di esempio per estrarre i dati da Teradata e caricarli su HDFS.
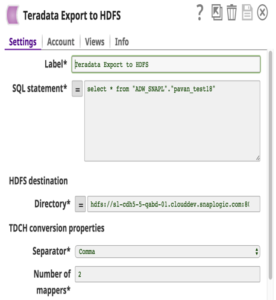
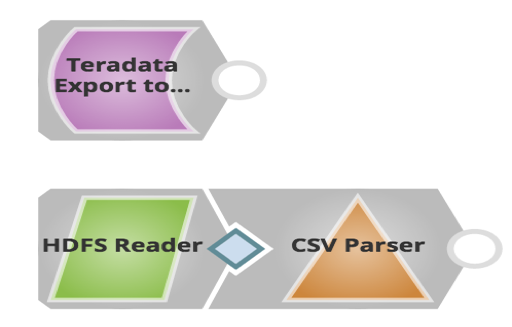
La pipeline a questo scopo è la seguente:
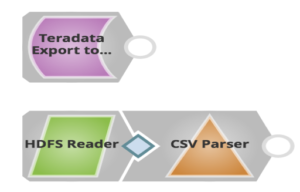
Come si può vedere sopra, si usa un solo Snap per esportare i dati da Teradata e caricarli in HDFS. I clienti possono poi usare HDFS Reader Snap per leggere i file esportati.
La release Winter 2017 ha fornito ai clienti molti vantaggi, dai flussi di dati, alla facilità di migrazione, al potenziamento delle funzionalità di sicurezza e ai vantaggi in termini di prestazioni. Maggiori informazioni sulla release SnapLogic Winter 2017 (4.8) sono disponibili nelle note di rilascio.
Pavan Venkatesh è Senior Product Manager di SnapLogic. Seguitelo su Twitter @pavankv.