





In diesem letzten Beitrag dieser Serie von Mark Madsen's Whitepaper: Will the Data Lake Drown the Data Warehouse? fasse ich die Rolle von SnapLogic im Enterprise Data Lake zusammen.
SnapLogic ist die einzige einheitliche Daten- und Application Integration Plattform als Service(iPaaS). Die SnapLogic Elastic Integration Platform verfügt über mehr als 350 vorgefertigte intelligente Konnektoren - Snaps genannt -, um alles von AWS Redshift bis Zuora zu verbinden, und eine Streaming-Architektur, die Echtzeit-, ereignisbasierte und latenzarme Unternehmensintegrationsanforderungen sowie das hohe Volumen, die Vielfalt und die Geschwindigkeit der Big-Data-Integration in derselben benutzerfreundlichen, selbstverwalteten Oberfläche unterstützt.
Die verteilte, weborientierte Architektur von SnapLogic eignet sich hervorragend für die Nutzung und Verschiebung großer Datensätze, die sich vor Ort, in der Cloud oder in beiden Umgebungen befinden, und für die Bereitstellung dieser Daten im und aus dem Data Lake. Die SnapLogic Elastic Integration Platform bietet viele der Kerndienste eines Data Lake, einschließlich Workflow-Management, Datenfluss, Datenbewegung und Metadaten.
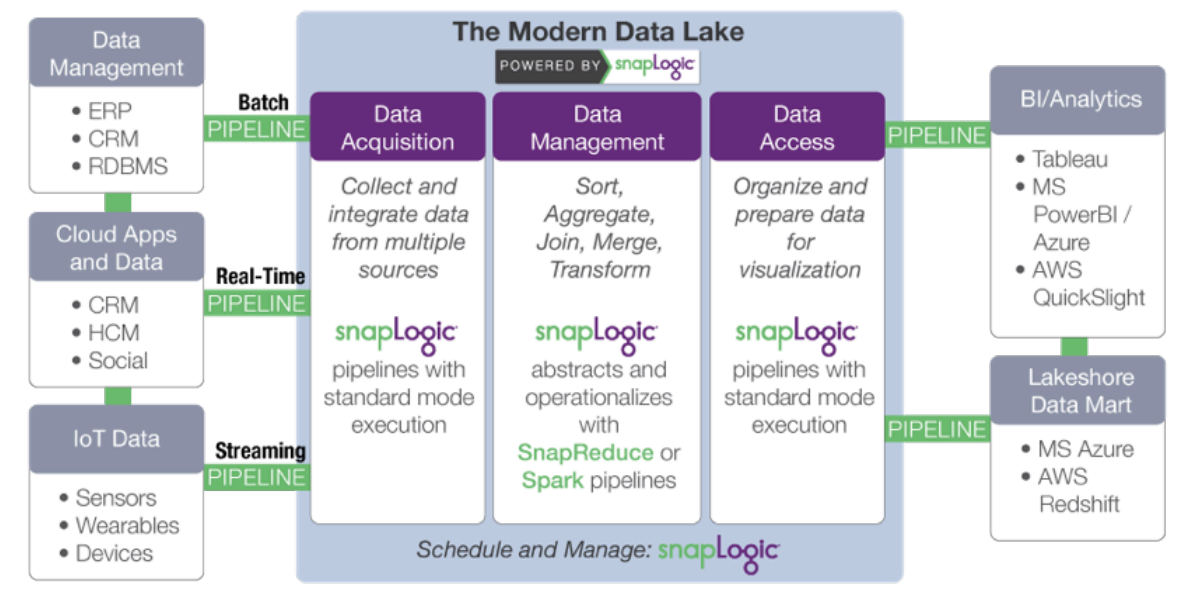
Genauer gesagt beschleunigt SnapLogic die Entwicklung eines modernen Data Lake durch:
- Datenerfassung: Sammeln und Integrieren von Daten aus verschiedenen Quellen. SnapLogic geht mit einem cloudbasierten visuellen Pipeline-Designer und vordefinierten Konnektoren für mehr als 350 strukturierte und unstrukturierte Datenquellen, Unternehmensanwendungen und APIs über Entwickler-Tools wie Sqoop und Flume hinaus.
- Datenumwandlung: Hinzufügen von Informationen und Umwandeln von Daten. Minimieren Sie den manuellen Aufwand bei der Datenaufbereitung (
) und steigern Sie die Effizienz von Datenwissenschaftlern und Analysten. SnapLogic bietet Snaps für Aufgaben wie Umwandlungen, Verknüpfungen und Vereinigungen ohne Skripterstellung. - Datenzugriff: Organisation und Aufbereitung von Daten für die Bereitstellung und Visualisierung. Stellen Sie Daten, die auf Hadoop-
oder Spark verarbeitet wurden, Anwendungen und Datenspeichern außerhalb des Clusters – wie Statistikpaketen und Business-Intelligence-Tools – problemlos zur Verfügung.
Der plattformunabhängige Ansatz von SnapLogic entkoppelt die Spezifikation der Datenverarbeitung von der Ausführung. Wenn sich das Datenvolumen oder die Latenzanforderungen ändern, kann dieselbe Pipeline verwendet werden, indem einfach die Zieldatenplattform gewechselt wird. Mit SnapReduce kann SnapLogic nativ auf Hadoop als YARN-verwaltete Ressource ausgeführt werden, die elastisch skaliert, um Big-Data-Analysen durchzuführen, während Spark Snap den Benutzern hilft, Spark-basierte Datenpipelines zu erstellen, die ideal für speicherintensive, iterative Prozesse geeignet sind. Unabhängig davon, ob MapReduce, Spark oder ein anderes Big-Data-Verarbeitungsframework zum Einsatz kommt, ermöglicht SnapLogic den Kunden die Anpassung an sich verändernde Data-Lake-Anforderungen, ohne sich auf ein bestimmtes Framework festlegen zu müssen.
Wir nennen es "Hadoop für Menschen " .
Nächste Schritte:
- Laden Sie das Whitepaper herunter: Wie man einen Enterprise Data Lake aufbaut: Wichtige Überlegungen, bevor Sie loslegen. Sie können auch das aufgezeichnete Webinar und die Folien im SnapLogic-Blog ansehen.
- Laden Sie das Whitepaper herunter: Wird der Data Lake das Data Warehouse ertränken?
- Sehen Sie sich diese Demonstration von SnapReduce und SnapLogic Hadooplex an und erfahren Sie mehr über unseren "Hadoop für Menschen"-Ansatz zur Big Data-Integration.





