





L'ultima volta abbiamo detto che capire cosa vogliamo che faccia l'apprendimento automatico è più importante di come farlo. Quindi, prima di passare a come costruire una pipeline di apprendimento automatico in SnapLogic Elastic Integration Platform, parliamo di ciò che stiamo facendo.
Un'applicazione utile in diversi settori e casi d'uso è il rilevamento delle anomalie. Come suggerisce il nome, il rilevamento delle anomalie è progettato per trovare dati anomali, o anormali. Questo può essere utilizzato per trovare prove di hacking dannoso, per identificare software difettosi, per implementare il controllo di qualità, per pulire i dati provenienti da sensori IoT, ecc. Qualunque sia la motivazione, il primo passo è l'addestramento del sistema. (Quando si è soddisfatti delle prestazioni del rilevatore (testandolo su dati che non ha "visto"), si distribuisce il sistema per ispezionare i dati, probabilmente in streaming.
I sistemi di rilevamento delle anomalie sono stati a lungo implementati senza l'apprendimento automatico, generalmente con regole empiriche. I widget al di fuori di una certa tolleranza vengono scartati; un server la cui CPU è al 95% di utilizzo per più di un minuto viene esaminato per un possibile processo di fuga; un termostato che segnala temperature al di fuori di 0-120 gradi Fahrenheit viene controllato per un malfunzionamento. L'apprendimento automatico aggiunge la capacità di creare queste regole automaticamente, con compromessi più chiaramente definiti e con la possibilità di riqualificare periodicamente il modello se abbiamo ragione di credere che il processo cambierà nel tempo.
Osserviamo un segnale molto semplice. Qui di seguito vediamo un segnale che presenta un po' di rumore, ma è abbastanza chiaro che dovrebbe essere circa 1, con un intervallo di sei-sigma compreso tra 0,4 e 1,6 circa. Ora addestriamo un rilevatore di anomalie su di esso, utilizzando una macchina vettoriale di supporto a classe singola (SVM). I dettagli su come funziona una SVM esulano dallo scopo di questo post, ma se siete interessati, O'Reilly Media ha un eccellente post interattivo di Jake VanderPlas sull'argomentocosì come la documentazione di documentazione di scikit-learn. Per i nostri scopi, la SVM viene addestrata fornendole dati normali. Non è necessario fornirgli esempi di dati anomali. Dopo averlo addestrato, forniamogli dei dati più sporchi e vediamo come si comporta:
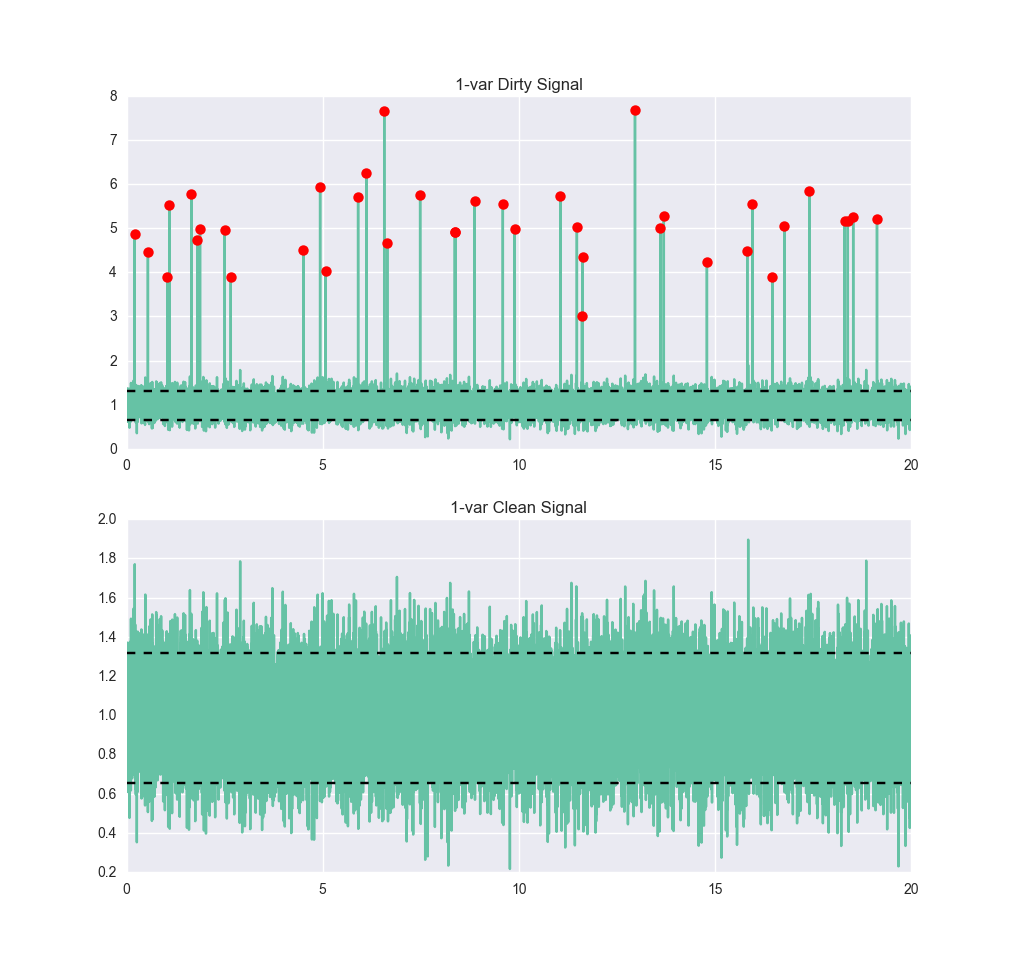
true_pos: 17964 vero_neg: 39 false_pos: 1997 falso_neg: 0 precisione: 0,90015 precisione: 0,89995 richiamo: 1.0 F1: 0.94734
I confini tra anomalia e non anomalia sono stati tracciati su questo grafico come linee nere orizzontali. Per un algoritmo standard con poche regolazioni, non è male. Abbiamo individuato tutte le anomalie, il che è positivo, ma stiamo anche classificando circa il 10% dei punti normali come anomalie. Se avessimo usato due classi (cioè addestrandoci sull'insieme con le anomalie, a condizione di poterle identificare) probabilmente avremmo ottenuto prestazioni molto migliori, in particolare molti meno falsi positivi.
I rilevatori di anomalie iniziano a brillare quando l'anomalia non è solo una variabile che si comporta male. Ad esempio, immaginiamo di monitorare le connessioni in entrata a un server web e il suo utilizzo della CPU. In genere ci aspettiamo che siano correlati in modo lineare. Se l'utilizzo della CPU è elevato quando le connessioni sono basse, ci preoccupiamo di un processo andato male o di una possibile violazione della sicurezza. Se le connessioni sono alte ma l'utilizzo della CPU è basso, forse è perché la nostra applicazione principale si è bloccata e agli utenti vengono servite solo pagine di errore. In ogni caso, la conoscenza dell'utilizzo della CPU o delle connessioni in entrata non è sufficiente per caratterizzare un'anomalia; dobbiamo esaminarle entrambe, come illustrato di seguito*:
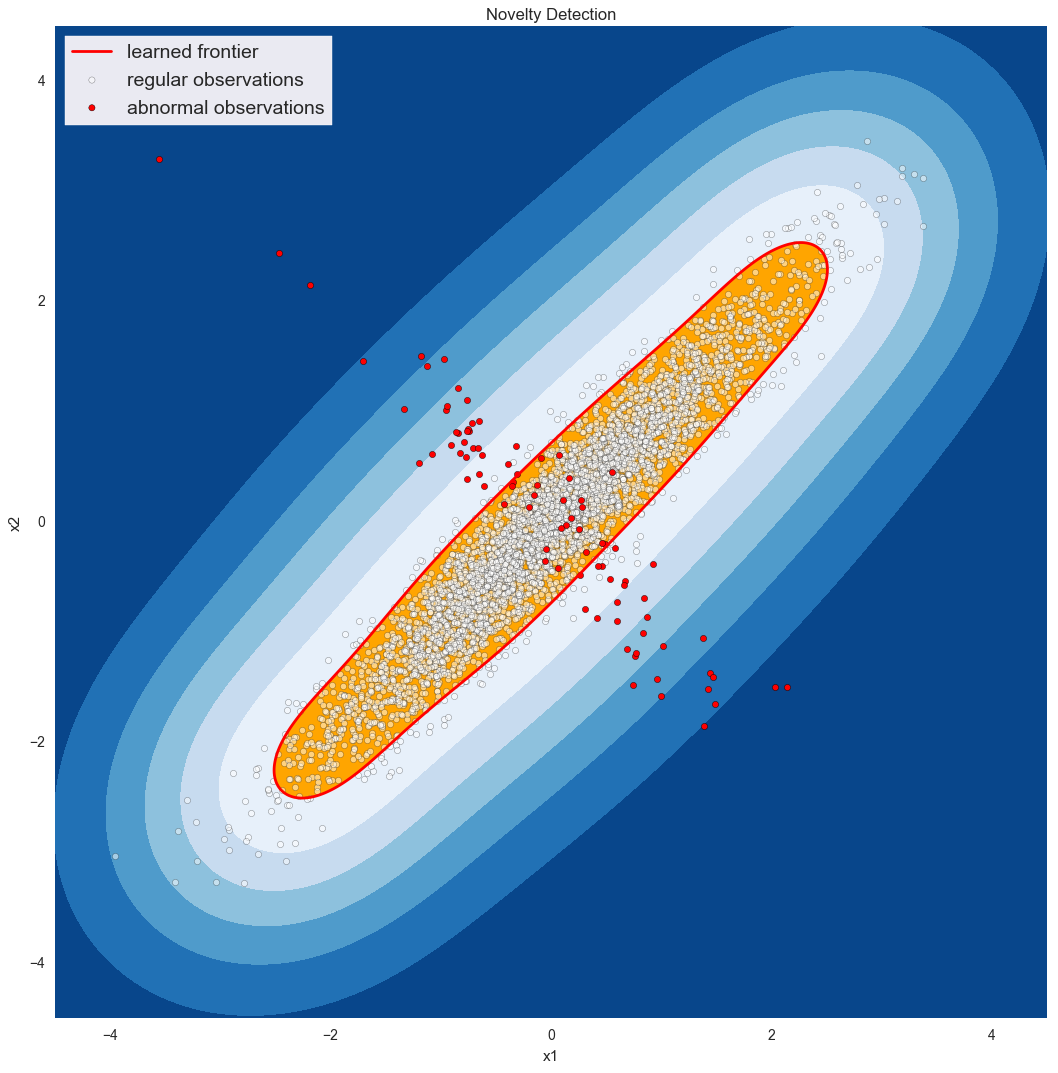
Dati treno (puliti): Set di dati di prova: true_pos: 18999 true_pos: 4668 true_neg: 0 true_neg: 64 falso_pos: 0 false_pos: 23 falso_neg: 1001 falso_neg: 245 precisione: 0,94995 precisione: 0,9464 precisione: 1,0 precisione: 0,99509 richiamo: 0,94995 richiamo: 0.95013 F1: 0,97433 F1: 0,97209
Nelle prossime due puntate di questa serie, costruiremo innanzitutto la pipeline per il rilevamento delle anomalie basandoci sul semplice rilevatore di anomalie a una variabile. Per la prima parte, supporremo di avere uno Snap per il rilevamento delle anomalie, ma non entreremo nei dettagli. Nell'ultima parte, torneremo a questo Snap black-box e mostreremo come possiamo configurare rapidamente un rilevatore di anomalie a scalabilità elastica su Azure ML, esposto come semplice servizio REST. Infine, se siete curiosi di conoscere i grafici creati in questo post, abbiamo pubblicato il codice Python in un repository repository GitHub per darvi un'occhiata. Ci sono due script e un notebook IPython/Jupyter. Entrambi sono in forma grezza (le richieste di pull sono benvenute!) ma sono un buon punto di partenza per ulteriori esplorazioni.
* Si potrebbe anche notare che ci interessa il rapporto tra le due variabili - chiamiamole x1 e x2 - e quindi si potrebbe creare un SVM a variabile singola su x3 lasciando che x3 = x1 / x2. Questo è vero, ma si noti che (a) si è appena inserita manualmente una conoscenza del processo nel sistema (la relazione lineare) e (b) quando x2 va a 0, x3 va all'infinito, il che è sempre problematico.

