





La dernière fois nous avons dit qu'il était plus important de déterminer ce que nous voulons que l'apprentissage automatique fasse que la manière de le faire. Avant d'aborder la construction d'un pipeline d'apprentissage automatique dans la plate-forme d'intégration élastique SnapLogic, parlons de ce que nous sommes en train de faire.
La détection d'anomalies est une application utile dans un grand nombre de secteurs et de cas d'utilisation. Comme son nom l'indique, la détection d'anomalies est conçue pour trouver des données qui sont anormales, ou anormales. Cela peut être utilisé pour trouver des preuves de piratage malveillant, pour identifier les logiciels défaillants, pour mettre en œuvre un contrôle de qualité, pour nettoyer les données provenant de capteurs IoT, etc. Quelle que soit la motivation, la première étape consiste à former le système. (Lorsque vous êtes satisfait des performances du détecteur (en le testant sur des données qu'il n'a pas "vues"), vous déployez le système pour inspecter les données - probablement des données en continu.
Les systèmes de détection d'anomalies sont depuis longtemps mis en œuvre sans apprentissage automatique, généralement à l'aide de règles empiriques. Les widgets dépassant une certaine tolérance sont rejetés ; un serveur dont l'unité centrale est utilisée à 95 % pendant plus d'une minute est examiné à la recherche d'un éventuel processus d'emballement ; un thermostat signalant des températures comprises entre 0 et 120 degrés Fahrenheit est vérifié pour détecter un dysfonctionnement. L'apprentissage automatique permet de créer ces règles automatiquement, avec des compromis plus clairement définis, et avec la possibilité de recycler périodiquement le modèle si nous avons des raisons de croire que le processus changera au fil du temps.
Examinons un signal très simple. Ci-dessous, nous voyons un signal avec un peu de bruit, mais il est assez clair qu'il devrait être d'environ 1, avec une fourchette de six sigmas comprise approximativement entre 0,4 et 1,6. Nous formons ensuite un détecteur d'anomalies à l'aide d'une machine à vecteurs de support (SVM) à classe unique. Les détails du fonctionnement d'un SVM dépassent le cadre de cet article, mais si vous êtes intéressé, O'Reilly Media propose un excellent article interactif de Jake VanderPlas sur le sujetainsi que la documentation de documentation scikit-learn. Dans notre cas, le SVM est entraîné en lui donnant des données normales. Il n'est pas nécessaire de lui fournir des exemples de données anormales. Après l'avoir entraîné, donnons-lui des données plus sales et voyons comment il se comporte :
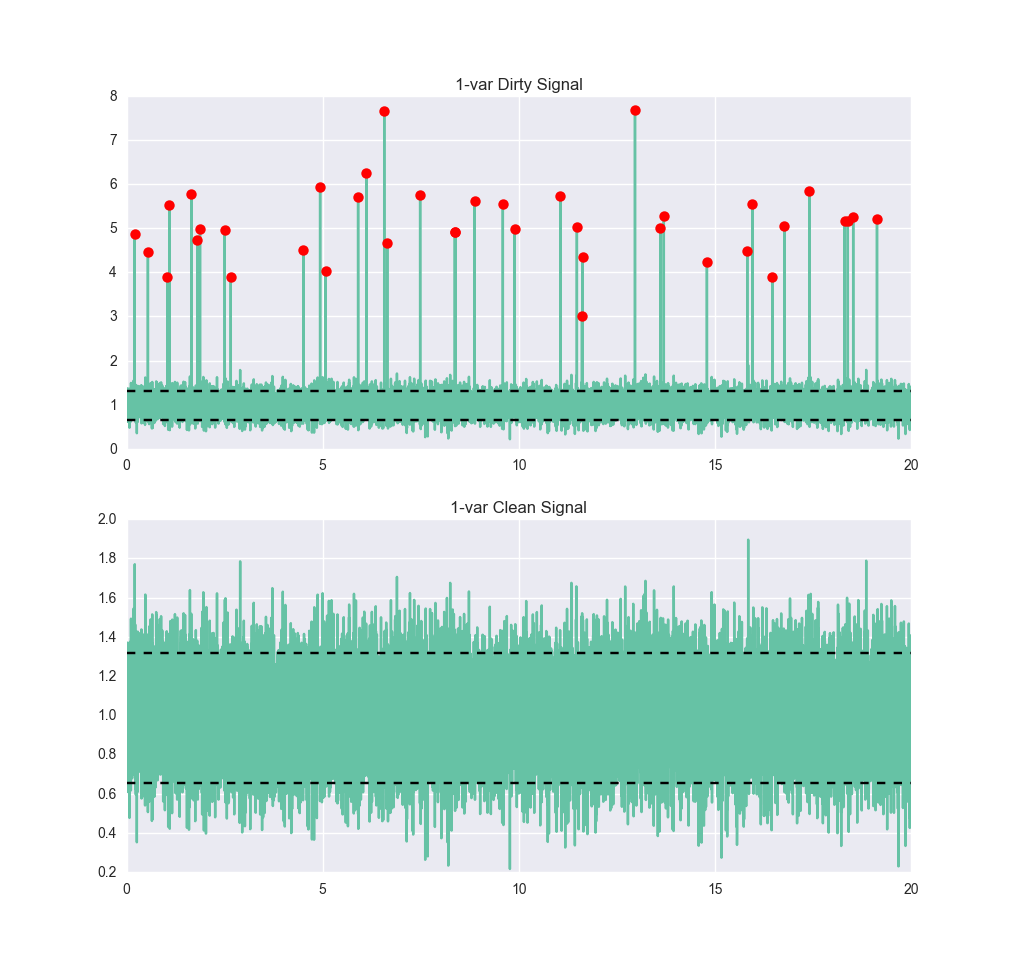
true_pos : 17964 true_neg : 39 false_pos : 1997 false_neg : 0 précision : 0.90015 précision : 0.89995 rappel : 1.0 F1 : 0.94734
Les limites anomalie/non-anomalie ont été tracées sur ce graphique sous forme de lignes horizontales noires. Pour un algorithme standard avec peu de réglages, ce n'est pas si mal. Nous capturons toutes les anomalies, ce qui est une bonne chose, mais nous classons également environ 10 % des points normaux comme des anomalies. Si nous avions utilisé deux classes (c'est-à-dire en nous entraînant sur l'ensemble des anomalies, à condition de pouvoir les identifier), nous aurions probablement obtenu de bien meilleures performances - en particulier, beaucoup moins de faux positifs.
Les détecteurs d'anomalies commencent vraiment à briller lorsque l'anomalie ne se limite pas à une seule variable qui se comporte mal. Imaginons, par exemple, que l'on surveille les connexions entrantes sur un serveur web et l'utilisation de son processeur. Nous nous attendons généralement à ce qu'il y ait une relation linéaire entre ces deux variables. Si l'utilisation de l'unité centrale est élevée alors que les connexions sont faibles, nous nous inquiéterons d'un processus qui a mal tourné ou d'une éventuelle faille de sécurité. Si les connexions sont élevées alors que l'utilisation de l'unité centrale est faible, c'est peut-être parce que notre application principale est tombée en panne et que les utilisateurs ne reçoivent que des pages d'erreur. Quoi qu'il en soit, il ne suffit pas de connaître l'utilisation de l'UC ou les connexions entrantes pour caractériser une anomalie ; nous devons examiner les deux, comme illustré ci-dessous* :
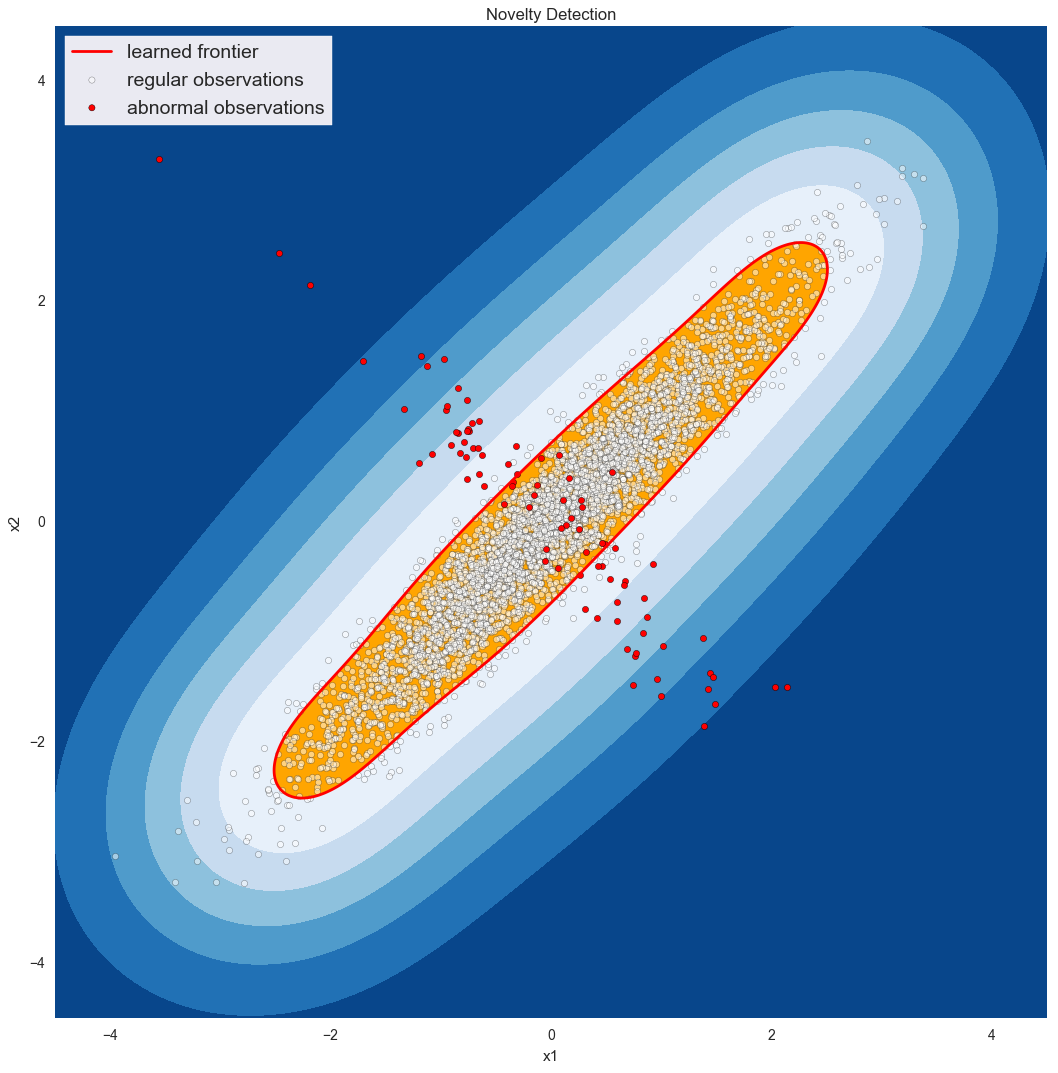
Données de formation (propres) : Ensemble de données de test : true_pos : 18999 true_pos : 4668 true_neg : 0 true_neg : 64 false_pos : 0 false_pos : 23 false_neg : 1001 false_neg : 245 précision : 0.94995 précision : 0.9464 précision : 1.0 précision : 0.99509 rappel : 0.94995 rappel : 0.95013 F1 : 0,97433 F1 : 0,97209
Dans les deux prochaines parties de cette série, nous allons d'abord construire le pipeline de détection d'anomalies en nous basant sur le simple détecteur d'anomalies à une variable. Pour la première partie, nous supposerons que nous disposons d'un Snap de détection d'anomalies, mais nous n'entrerons pas dans les détails. Dans la dernière partie, nous reviendrons sur cette boîte noire Snap et montrerons comment nous pouvons rapidement configurer un détecteur d'anomalies à échelle élastique sur Azure ML qui nous est exposé sous la forme d'un simple service REST. Enfin, si vous êtes curieux des graphiques créés dans ce billet, nous avons publié le code Python dans un dépôt dépôt GitHub pour que vous puissiez le consulter. Il y a deux scripts et un carnet IPython / Jupyter. Les deux sont à l'état brut (les pull requests sont les bienvenues !) mais constituent un bon point de départ pour une exploration plus poussée.
* Vous pourriez également noter que vous vous intéressez au rapport entre les deux variables - appelons-les x1 et x2 - et que vous pourriez donc créer un SVM à variable unique sur x3 en laissant x3 = x1 / x2. C'est vrai, mais notez que (a) vous venez d'injecter manuellement une certaine connaissance du processus dans le système (la relation linéaire) et (b) comme x2 va à 0, x3 va à l'infini, ce qui est toujours problématique.

