Nel mondo competitivo di oggi, le aziende capiscono l'importanza dell'innovazione e della modernizzazione e come la migrazione a Cloud possa aiutarle a raggiungere il successo. Molte aziende sono alla ricerca di modi ottimali per ingerire e migrare i propri dati da diverse fonti, compresi i sistemi legacy on-premises, ad AWS.
I progetti di ri-piattaforma sono tra i più complicati, perché a differenza delle iniziative per costruire qualcosa di nuovo, bisogna mantenere operativo qualcosa che già funziona per gli utenti e supporta l'azienda, mentre si fa un lavoro piuttosto importante dietro le quinte.
SnapLogic ha lavorato con diversi clienti per aiutarli a realizzare queste migrazioni, in stretta collaborazione con AWS. A questo punto, la tecnologia di calcolo cloud non è più in discussione: è stata dimostrata più e più volte, in produzione e su scala. Grandi aziende si affidano a cloud ogni giorno. Il piano di controllo di SnapLogic - fondamentale per l'esistenza della nostra azienda, per non parlare delle migliaia di utenti che vi accedono ogni giorno - è ospitato in AWS, sfruttando la sua resilienza incorporata tra le diverse zone di disponibilità di una regione e tra regioni diverse, per consentire a noi e ai nostri clienti di concentrarsi sulla gestione delle nostre attività.
Caso d'uso: Migrazione dei dati da sistemi legacy on-premises a tabelle Apache Iceberg in Amazon S3
Recentemente i team di SnapLogic e AWS hanno lavorato insieme per supportare un'azienda agtech globale, che si è posta la missione di aiutare milioni di agricoltori in tutto il mondo a coltivare cibo sicuro e nutriente, prendendosi cura del pianeta. Per sostenere questa missione, l'azienda aveva un piano ambizioso per passare dai propri sistemi legacy on-premise a un approccio nuovo, più moderno e meno gravoso in termini di sviluppo e manutenzione per le proprie capacità di analisi dei dati centrali a livello aziendale.
Sfida commerciale
La sfida consisteva nel fatto che la centralizzazione dell'analisi dei dati avrebbe richiesto l'accesso a un panorama informatico estremamente eterogeneo e complesso, composto da servizi cloud , applicazioni on-premise e database di molti tipi diversi, oltre ad applicazioni legacy e personalizzate. Questa situazione è comune a molte aziende consolidate, che hanno accumulato sistemi e archivi di dati nel corso degli anni per molti scopi diversi, ma che ora si trovano di fronte a scelte difficili.
Il processo di ingestione dei dati di questa particolare azienda era diventato complesso e costoso a causa di approcci e tecnologie di integrazione legacy diversi e storicamente sviluppati che richiedevano una manutenzione sempre più difficile e costosa. I data engineer dedicavano fino al 50% del loro tempo allo sviluppo e alla manutenzione delle integrazioni di dati, invece di potersi concentrare su un lavoro più produttivo.
Molti progetti di migrazione di cloud come questo sono falliti nel corso degli anni a causa dell'incapacità di abbracciare il potenziale delle nuove piattaforme e tecnologie. I primi tentativi dell'azienda in questa direzione sono stati deludenti, con centinaia di lavori cloud necessari solo per mantenere lo stato. Peggio ancora, il nuovo sistema era poco flessibile e non supportava operazioni granulari sui dati, richiedendo agli utenti di sovrascrivere i dati a ogni nuovo periodo.
Questo progetto di integrazione non si limitava alla semplice connettività, ma doveva anche garantire livelli di throughput e prestazioni adeguati alla scala globale e alle ambizioni aziendali del cliente. Alcune delle tabelle più grandi dei sistemi aziendali chiave che dovevano essere esposte per l'analisi integrata erano dell'ordine di decine di miliardi di righe. Alcune API restituivano decine di milioni di oggetti a una singola query, richiedendo al livello di integrazione SnapLogic di suddividere le richieste per garantire la consegna completa e la visibilità aziendale. Inoltre, alcune colonne contenevano dati sensibili che dovevano essere crittografati.
Panoramica della soluzione
La piattaforma iPaaS di SnapLogic, alimentata dall'AI e priva di codice, è stata in grado di integrare, trasformare e caricare facilmente i dati da diversi sistemi alle tabelle Apache Iceberg di Amazon S3, grazie a oltre 750 connettori nativi per un'ampia gamma di applicazioni. SnapLogic supporta sia le metodologie ETL che ELT, il che significa che le trasformazioni dei dati possono essere eseguite sia sulla piattaforma SnapLogic che sul sistema di destinazione dove i dati saranno archiviati per ulteriori analisi.
Una parte fondamentale del successo di questa integrazione è stata la collaborazione con una suite completa di tecnologie e partner.
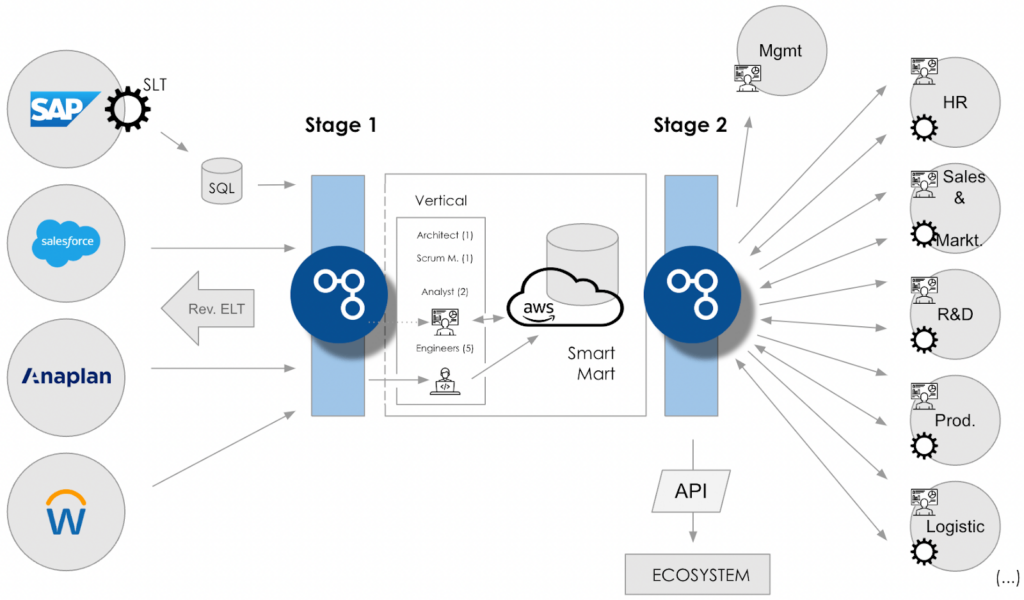
Una tecnologia particolarmente importante quando si trattava di soddisfare i requisiti dell'azienda era Apache Iceberg, che consente un data base transazionale. SnapLogic ha utilizzato Amazon Athena per caricare ed eseguire operazioni sui dati contenuti nelle tabelle Iceberg su Amazon S3. Le tabelle Iceberg potevano inoltre essere consultate per l'analisi dei dati e l'apprendimento automatico tramite servizi AWS come Amazon Athena, Amazon Quicksight, Amazon Redshift o altri strumenti di BI, visualizzazione e dashboard.
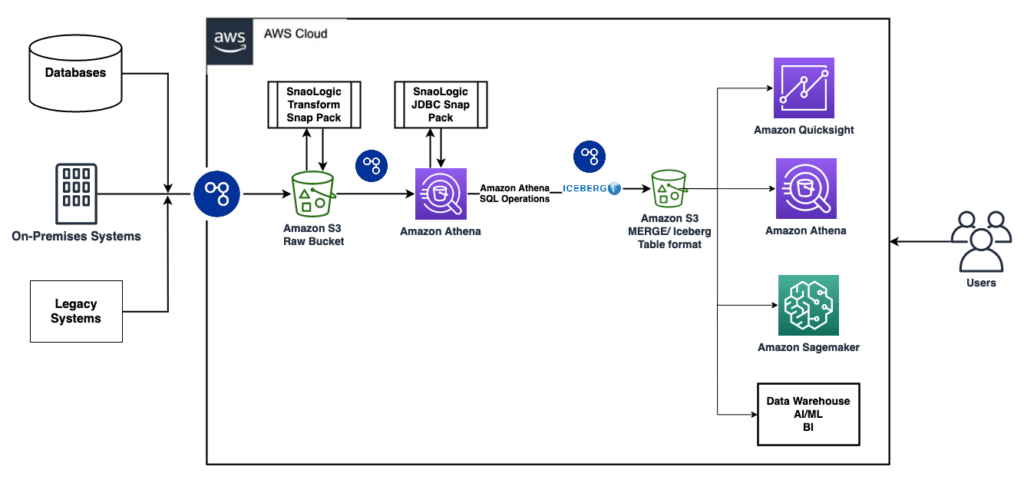
Caratteristiche principali
- Lo snap Encrypt ha consentito la crittografia dei dati sensibili.
- Il supporto per pipeline annidate tramite la funzionalità Pipeline Execute di SnapLogic è stato sfruttato per ottenere efficienza e modularità.
- Il supporto di SnapLogic per i parametri porta avanti questa flessibilità. Ad esempio, le pipeline padre possono passare iterativamente diversi valori di parametri alle pipeline figlio.
- Più pipeline parallele ingeriscono ed elaborano i dati in pezzi separati per accelerare l'ingestione di grandi volumi di dati da più sistemi di origine.
- La trasformazione dei dati in volo è stata realizzata tramite mapper che trasformano i dati ingeriti dai sistemi di origine.
- La flessibilità della piattaforma SnapLogic è dimostrata dall'uso di Generic JDBC Execute Snap per connettersi ad Amazon Athena.
Vantaggi
La soluzione realizzata con SnapLogic e i servizi AWS è stata in grado di ridurre notevolmente l'impegno per la progettazione, lo sviluppo, il collaudo e la manutenzione delle pipeline di integrazione e di ingestione dei dati. Gli analisti di business hanno ora una visibilità senza precedenti sulla propria attività e sui dati che ne sono alla base. Tutti questi dati esistevano già ed erano già stati raccolti, con un notevole sforzo, da dipendenti, partner e persino clienti. Ma era troppo difficile accedervi in modo tempestivo e continuo. Con questa soluzione, i diversi stakeholder del cliente hanno potuto sfruttare le funzionalità avanzate di Iceberg, come le query temporali, che consentono agli utenti di eseguire analisi basate sullo stato dei dati in una data specifica. Il cliente dispone ora di un moderno data base transazionale come unica fonte di verità per tutte le sue organizzazioni.
Sfruttando il supporto nativo per ciascuna delle piattaforme tecnologiche esistenti, siamo stati in grado di ridurre fino al 70% il tempo necessario per sviluppare e mantenere le integrazioni, liberando l'equivalente di oltre 17 dipendenti per nuovi progetti e una più rapida innovazione.
Conclusione
La piattaforma low-code/no-code di SnapLogic, abilitata all'AI, è la chiave per sbloccare il massimo valore dagli investimenti passati e futuri nei dati. La stretta integrazione con i servizi AWS garantisce un rapido time-to-market, assicurando che i benefici previsti non rimangano teorici ma vengano rapidamente dimostrati nella pratica.
Grazie a SnapLogic e AWS, questa azienda agroalimentare dispone ora di una piattaforma dati moderna e sostenibile, adatta allo scopo, che abbraccia sia i sistemi legacy on-premises sia i sistemi cloud su cui sta costruendo il proprio futuro.
Ecco alcune risorse per saperne di più su SnapLogic e le sue funzionalità:
- Registratevi per il prossimo webinar congiunto di AWS e SnapLogic
- Visitate il sito web di SnapLogic e prenotate una demo
- Scoprite i prossimi eventi e webinar su SnapLogic
- Registrazione ai seminari di formazione su SnapLogic
- Abbonatevi a una prova gratuita di 30 giorni di SnapLogic