





Microsoft Azure HDInsight is an Apache Hadoop distribution powered by the cloud. Internally HDInsight leverages the Hortonworks data platform. HDInsight supports a large set of Apache big data projects like Spark, Hive, HBase, Storm, Tez, Sqoop, Oozie and many more. The suite of HDInsight projects can be administered via Apache Ambari.
 This post lists out the steps involved in spinning up an HDInsight cluster, setting up SnapLogic’s Hadooplex on HDInsight, and building and executing a Spark data flow pipeline on HDInsight. We start with spinning up a HDInsight cluster from the MS Azure Portal.
This post lists out the steps involved in spinning up an HDInsight cluster, setting up SnapLogic’s Hadooplex on HDInsight, and building and executing a Spark data flow pipeline on HDInsight. We start with spinning up a HDInsight cluster from the MS Azure Portal.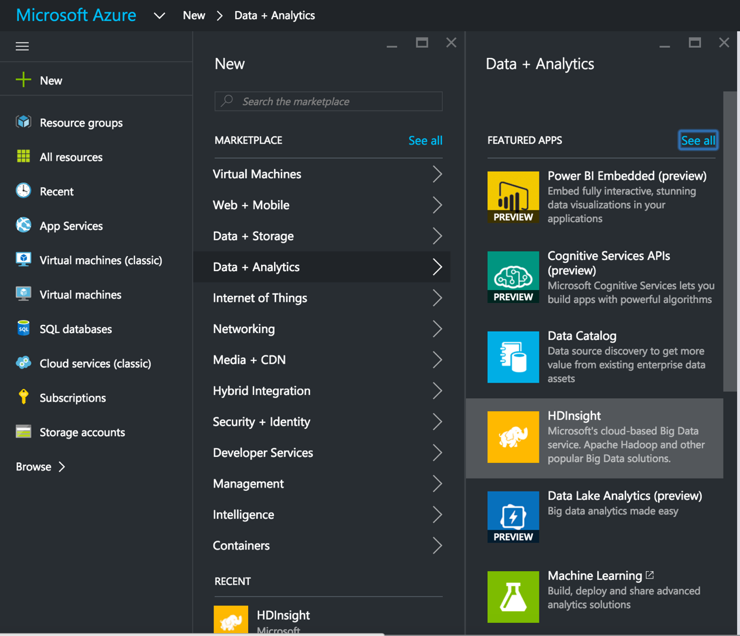
After selecting HDInsight, we add in the cluster name, cluster type and other required details to spin up the HDInsight cluster. For executing Spark pipelines, select Cluster Type as Spark, Operating System as Linux and version as Spark 1.6.1 (HDI 3.4).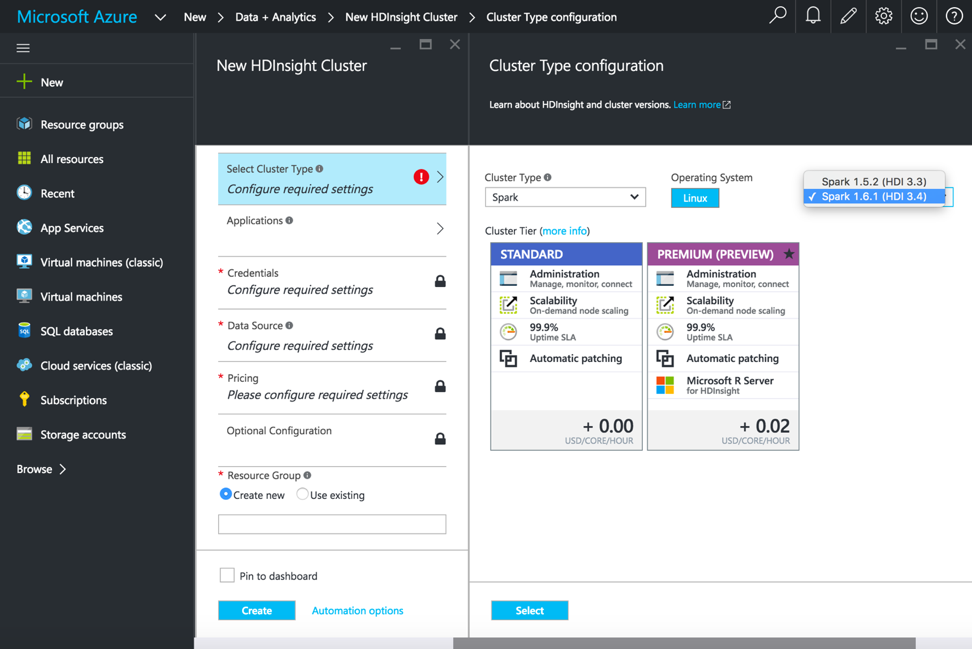
Once the HDInsight cluster is up and running, login to the console to create and configure a SnapLogic Hadoooplex.
From the dashboard ensure that the Hadooplex Master and the node have registered to the SnapLogic’s Control plane.
At this point, we are ready to create and execute a Spark pipeline on HDInsight. Here I will create a very basic Spark pipeline to demonstrate reading a file and landing it back to the Azure storage blob with some simple transformation.
From the SnapLogic Designer pane I create a new Spark pipeline.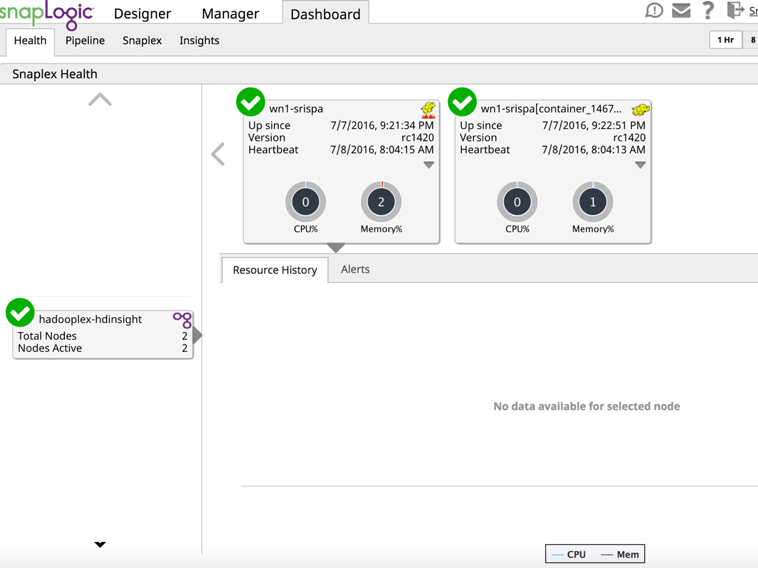
At this point, we are ready to create and execute a Spark pipeline on HDInsight. Here I will create a very basic Spark pipeline to demonstrate reading a file and landing it back to the Azure storage blob with some simple transformation.
From the SnapLogic Designer pane I create a new Spark pipeline.
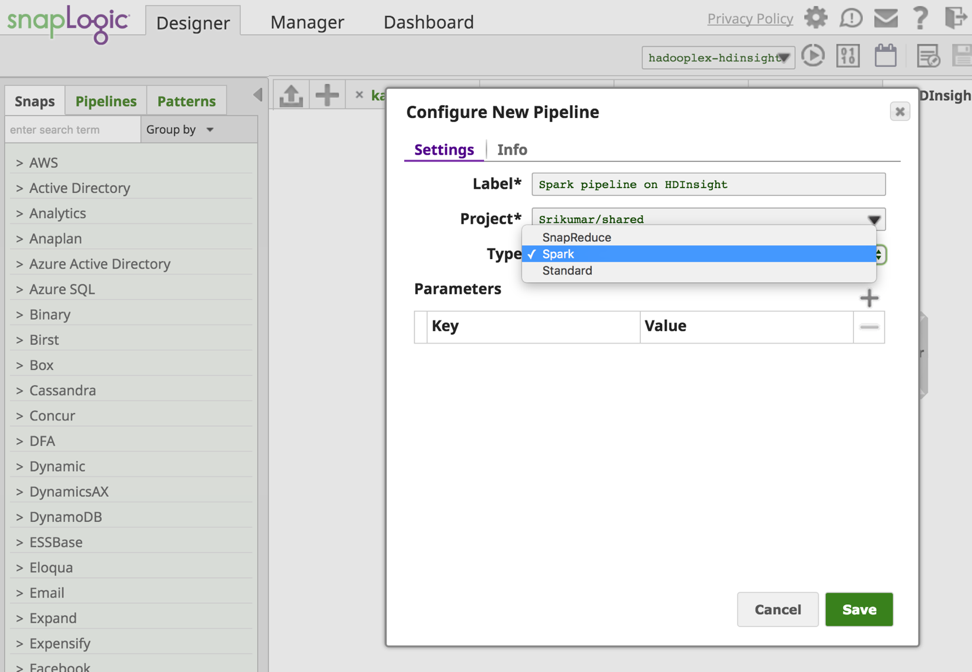
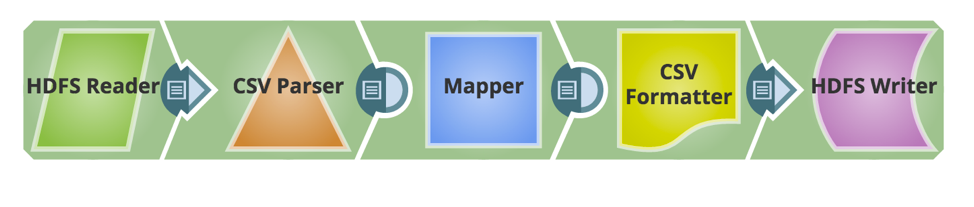
Now required Snaps are added to build the pipeline. Below is the snapshot of the pipeline.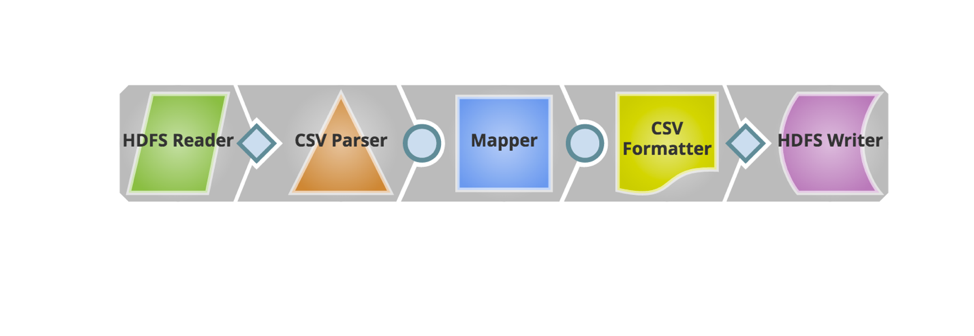
HDInsight uses Azure Blob storage as the big data store for HDFS. SnapLogic supports Windows Azure Storage Blob (WASB) protocol, which is an extension built on top of HDFS API.
The next step is to setup an Azure Storage Account and read/write data from the Azure Storage Blob using the HDFS Reader & Writer.
From the “Accounts” tab on HDFS Reader (or HDFS Writer) we will click on the “Add Account” button to configure the account details. On the “Create Account Options” choose the location to save the account setup and select the account type as “Azure Storage” and click the “OK” button. 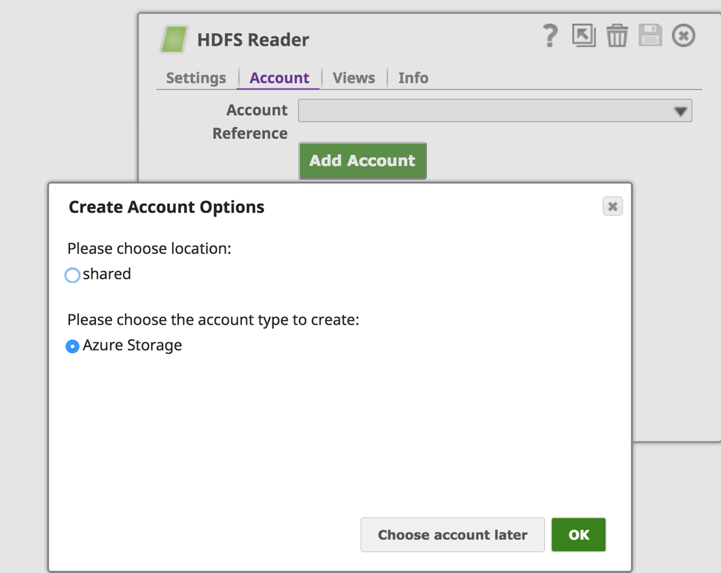
On the “Create Account” Dialogue, enter the Azure Account name and the Primary Access Key. These details can be found from the Azure portal -> Storage Account -> Settings -> Access Keys
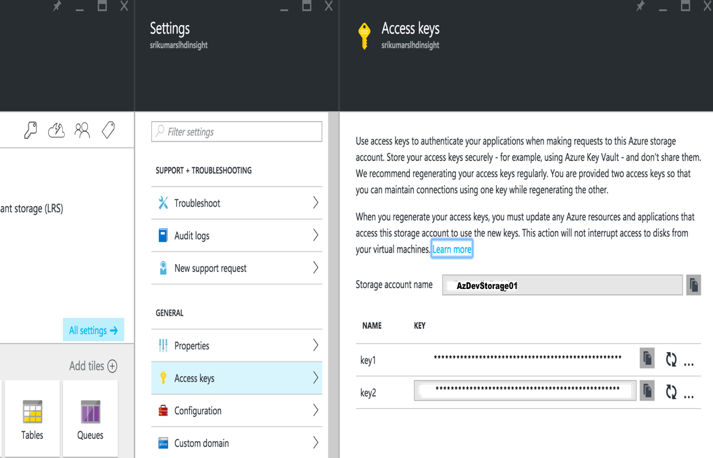
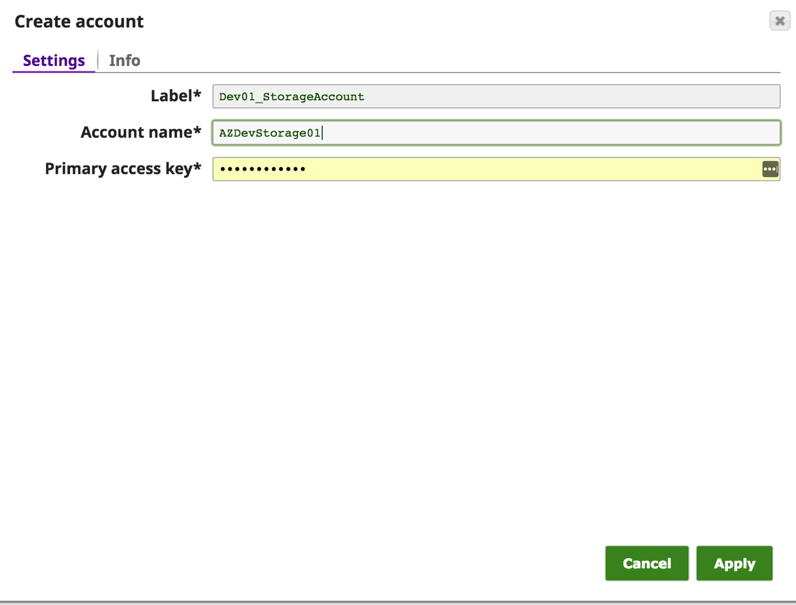
Save the Account and now you can access data from the Azure blob using the wasb:///containername/path_to_file
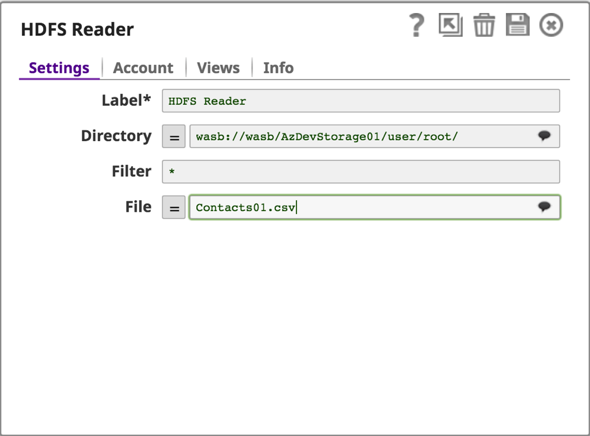
Configure the rest of the pipeline to transform and land the data back to an output folder on the Azure Storage Blob.
Now let’s validate and run the pipeline. The screenshot below shows successful validation and execution of the Spark pipeline.
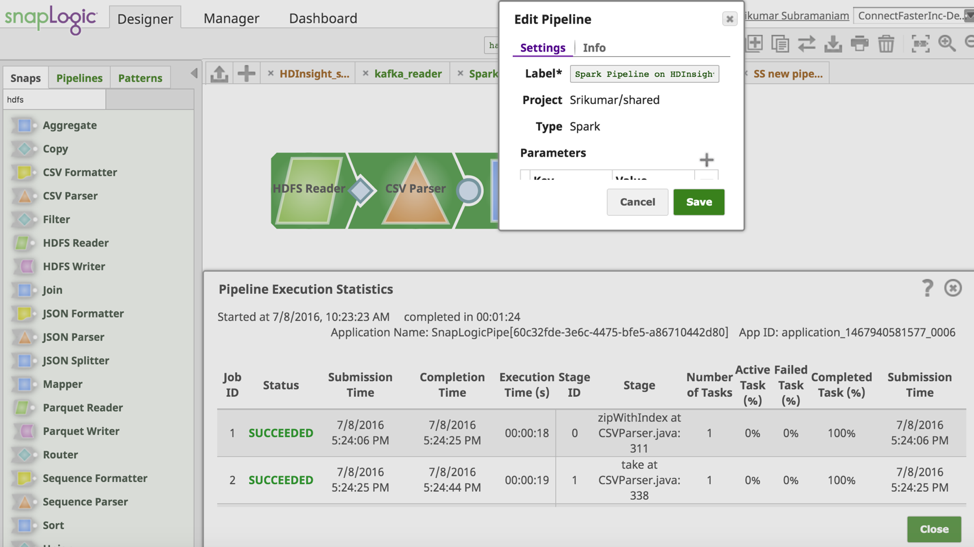
Support for HDInsight allows you to leverage the power of the SnapLogic Elastic Integration Platform to accelerate your integrations on the Microsoft Azure platform. Learn more about SnapLogic for Microsoft Azure here.





