





I task di Ultra Pipeline sono utilizzati per implementare integrazioni di servizi web in tempo reale che richiedono tempi di risposta previsti prossimi a pochi secondi. Nella prima serie di post illustrerò alcuni degli aspetti chiave della progettazione di Ultra Pipeline. Nella seconda serie di post mi concentrerò sul monitoraggio di questi task a bassa latenza.

Poiché gli strumenti di Ultra Pipelines sono analoghi all'architettura di richiesta/risposta dei servizi Web, nella progettazione di Ultra Pipelines in SnapLogic occorre considerare i seguenti aspetti.
Numero di visualizzazioni:
Ultra Pipelines può supportare una combinazione di viste di ingresso e di uscita:
- Nessuna vista di input non collegata, nessuna vista di output non collegata – Sebbene si tratti di una combinazione rara, questo modello potrebbe essere utilizzato in un contesto listener-consumer. Con 0 viste di input e 0 viste di output, è possibile utilizzare una Ultra Pipeline sempre attiva per interrogare e consumare i documenti da un endpoint, senza richiedere l'invio di documenti da parte del feed-master.
Caso d'uso: Progettare un meccanismo di polling per l'acquisizione delle modifiche utilizzando lo snap Idoc Listener e aggiornare la tabella dei dati master con la modifica. Poiché i documenti non vengono ricevuti dal feed-master, la vista di output della pipeline può essere chiusa.
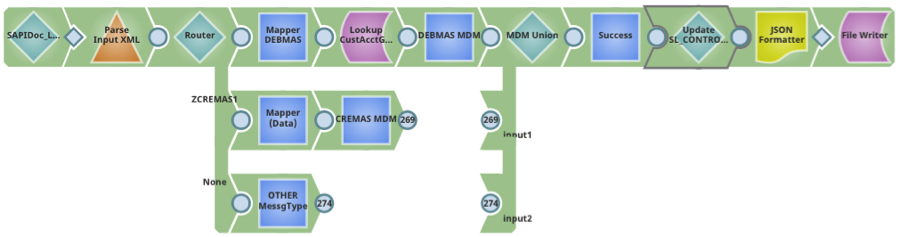
- Una vista di input non collegata, una o più viste di output non collegate – Il modello di Ultra Pipeline più diffuso è una semplice struttura richiesta-risposta che può essere utilizzata come livello di accesso ai dati per servizi web in tempo reale. Questo modello trasforma una pipeline in un’attività sempre in esecuzione; i documenti vengono forniti alla pipeline tramite un feed-master che gestisce una coda di documenti, analizzati dalla pipeline, mentre le risposte vengono restituite al chiamante attraverso il feed-master.
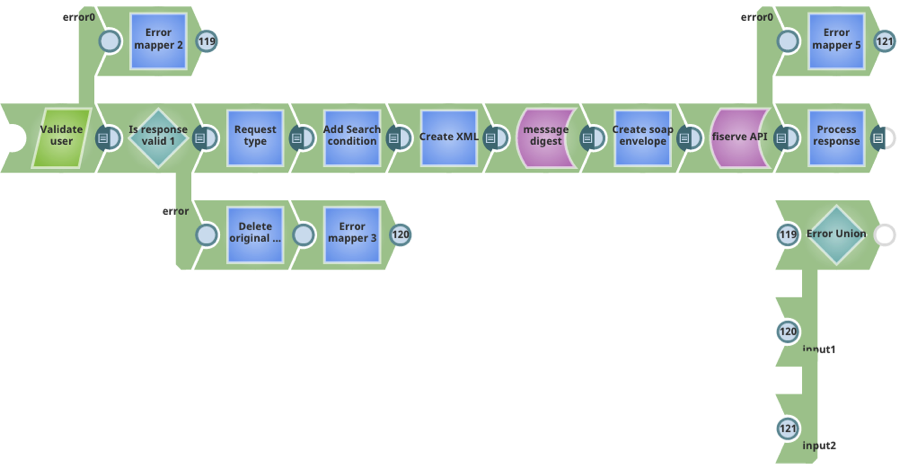
Caso d'uso 1: Progettare un'API in tempo reale per servizi web on-premise da utilizzare nel cloud. La pipeline riportata di seguito utilizza le informazioni contenute nel documento in entrata per convalidare l'utente, analizzare la richiesta, chiamare un server applicativo on-premise e restituire la risposta. Per garantire un'elaborazione robusta, al design della pipeline sono state aggiunte funzionalità di gestione degli errori e una vista di output aggiuntiva per restituire gli errori in caso di errore.
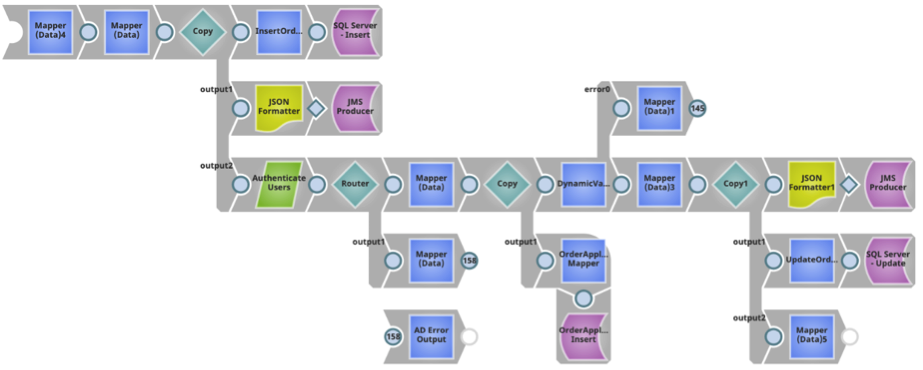
Caso d'uso 2: È possibile definire un endpoint consumatore utilizzando lo snap JMS Producer per consumare i documenti dal feed di dati, creando una Ultra Pipeline con 1 vista di ingresso. Poiché la funzionalità del feed-master si basa su un framework di richiesta-risposta, per ogni documento di richiesta inviato a un'istanza del task Ultra Pipeline, il feed-master deve ricevere una risposta, il che implica la presenza di almeno una vista di output. La pipeline Ultra mostrata di seguito legge i dati da un documento di input, li analizza e li scrive sulla coda JMS; una copia della risposta viene restituita al chiamante.
Nel prossimo post di questa serie, passerò in rassegna i tipi di viste disponibili per Ultra Pipelines. Tratterò poi la gestione degli errori e delle eccezioni e la gestione e il monitoraggio delle prestazioni.
Prossimi passi: Date un'occhiata alle nostre risorse video per vedere alcune interessanti demo di SnapLogic e contattateci se siete interessati a saperne di più su SnapLogic Elastic Integration Platform.



