In un precedente blogho parlato delle principali tendenze nel settore dell'integrazione dei dati e del passaggio dei clienti da on-premise a cloud. Vorrei concentrarmi su una tendenza che riguarda lo spostamento dei dati da piattaforme di analisi dei dati on-premise o cloud a una tecnologia Data Lake come Azure Data Lake.
Che cos'è un Data Lake?
Il Data Lake è un termine coniato per archiviare grandi quantità di dati nella loro forma grezza e nativa, compresi i dati strutturati e non strutturati in un'unica posizione. Questi dati possono provenire da diverse fonti e il Data Lake può fungere da unica fonte di verità per qualsiasi organizzazione. Dal punto di vista dell'architettura, i dati vengono prima archiviati in una palude/acquisizione di dati, poi puliti/trasformati nell'ambito della trasformazione dei dati e successivamente pubblicati per ottenere informazioni di business.
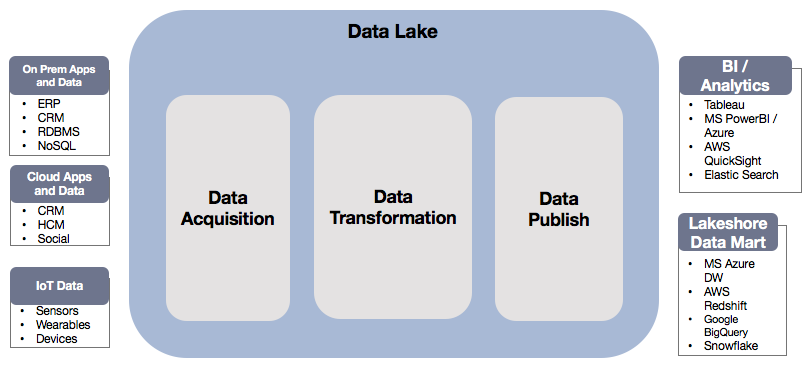
Come si vede nel diagramma precedente, le aziende dispongono di più sistemi come ERP, CRM, RDBMS, NoSQL, sensori IoT, ecc. I dati disparati, archiviati in sistemi diversi, rendono difficile l'estrazione dei dati. Un Data Lake riunisce tutti i dati sotto un unico tetto (acquisizione dei dati) utilizzando uno dei seguenti servizi:
- Azure Blob
- Azure Data Lake Store
- Amazon S3
- HDFS
- Altri
I dati memorizzati in uno di questi servizi possono essere trasformati nei seguenti modi:
- Aggregato
- Ordinamento
- Unirsi
- Unire
- Altro
I dati trasformati vengono poi trasferiti nella sezione di pubblicazione/accesso ai dati (potrebbe essere la stessa dei servizi di acquisizione dati), dove gli utenti possono utilizzare i seguenti strumenti per interrogare i dati:
- U-SQL di Microsoft
- Amazon Athena
- Alveare
- Presto
- Altri, ecc.
In definitiva, un Data Lake può servire come piattaforma per l'esecuzione di analisi al fine di fornire una migliore esperienza ai clienti, raccomandazioni e altro ancora.
Dove vengono archiviati i dati in Azure?
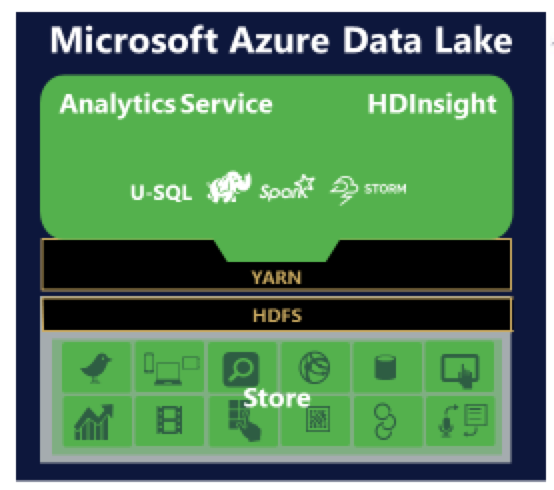
Azure Data Lake è uno di questi Data Lake di Microsoft e il repository utilizzato per archiviare tutti i dati è Azure Data Lake Store. Gli utenti possono eseguire Analytics Service, HDInsight o utilizzare U-SQL, un linguaggio di query per big data, su questo archivio di dati per ottenere migliori informazioni aziendali.
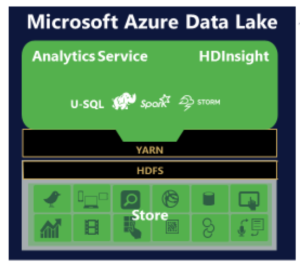
Azure Data Lake Store (ADLS) può memorizzare qualsiasi dato nel suo formato nativo. Uno degli obiettivi di questo data store è quello di riunire i dati provenienti da fonti diverse. Snaplogic Enterprise Integration Cloud , con i suoi connettori precostituiti chiamati Snaps, aiuta a spostare i dati da diversi sistemi al data store in modo rapido.
ADLS fornisce una complessa API che le applicazioni utilizzano per archiviare i dati in ADLS. Snaplogic ha astratto tutte queste complessità tramite Snaps, in modo che gli utenti sappiano dove sono archiviati i dati in Azure e possano ora spostare facilmente i dati da vari sistemi ad ADLS senza dover conoscere le complessità di queste API.
Caso d'uso
Un'azienda ha bisogno di tracciare e analizzare i contenuti per consigliare meglio i prodotti o i servizi ai propri clienti. I dati, provenienti da varie fonti come Oracle, file, Twitter, ecc. - devono essere archiviati in un repository centrale come ADLS, in modo che gli utenti aziendali possano eseguire analisi per misurare il comportamento di acquisto dei clienti, i loro interessi e i prodotti acquistati.
Ecco un esempio di pipeline che può risolvere questo caso d'uso utilizzando Snaps:
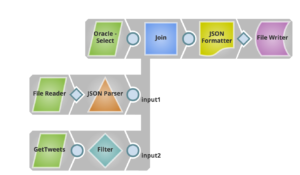
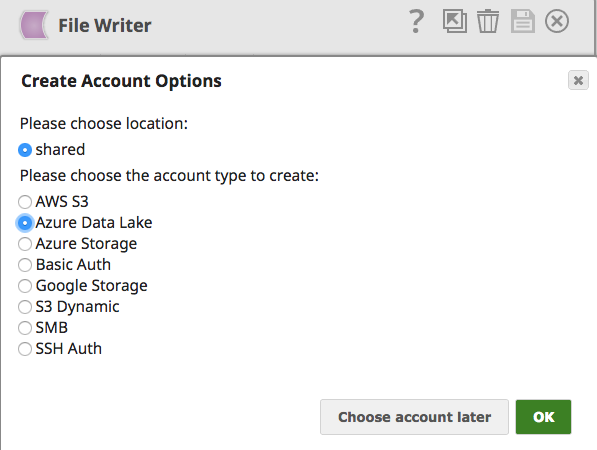
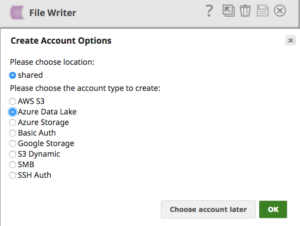
Utilizzando File Writer Snap e scegliendo l'account Azure Data Lake come mostrato di seguito, è possibile archiviare i dati uniti da vari sistemi in Azure Data Lake con facilità.
Nel complesso, il Data Lake può essere uno sportello unico per l'archiviazione di qualsiasi dato, offrendo agli utenti più modi per ricavare approfondimenti da più fonti di dati. E SnapLogic è pronto a facilitare agli utenti lo spostamento dei dati nel Data Lake (in questo caso, un Azure Data Lake Store) in modo rapido e semplice.
Pavan Venkatesh è Senior Product Manager di SnapLogic. Seguitelo su Twitter @pavankv.