






Questo blog analizza i concetti di data warehouse, data lake e data lakehouse e illustra il loro confronto e i vantaggi di ciascun approccio. Lo scopo di questo blog è quello di fornire una visione sintetica dell'architettura di alto livello.
Magazzini dati classici
Il concetto di data warehouse classico, da sempre cavallo di battaglia del mondo della business intelligence e dell'analisi dei dati, esiste dagli anni '80 e la popolarità del data warehouse come strumento aziendale è in gran parte attribuita all'informatico americano Bill Inmon. Inmon, spesso considerato il "padre" del data warehouse, ha originariamente definito il data warehouse come "una raccolta di dati orientata al soggetto, non volatile, integrata e variabile nel tempo, a supporto delle decisioni del management".
I data warehouse sono diventati, e rimangono, strumenti popolari per le imprese di tutto il mondo, perché offrono alle aziende la possibilità di analizzare i dati e le loro variazioni nel tempo, di creare approfondimenti e di giungere a conclusioni che aiutano a prendere decisioni aziendali.
I data warehouse classici [Figura 1] operano tipicamente come depositi centrali dove le informazioni, cioè i dati, arrivano dalle unità aziendali interne, dai partner commerciali esterni, dalle operazioni di vendita, dalle operazioni di produzione e da un gran numero di altre fonti. L'obiettivo e il vantaggio del data warehouse è quello di raccogliere tutte queste informazioni, memorizzarle, aggregarle e avere una visione olistica dell'azienda per formare un'intelligence più completa e più esaustiva sull'azienda. Quanto più rapidamente un data warehouse è in grado di aiutare gli utenti e i dirigenti a creare o a fare report sull'intelligence, tanto meglio è.
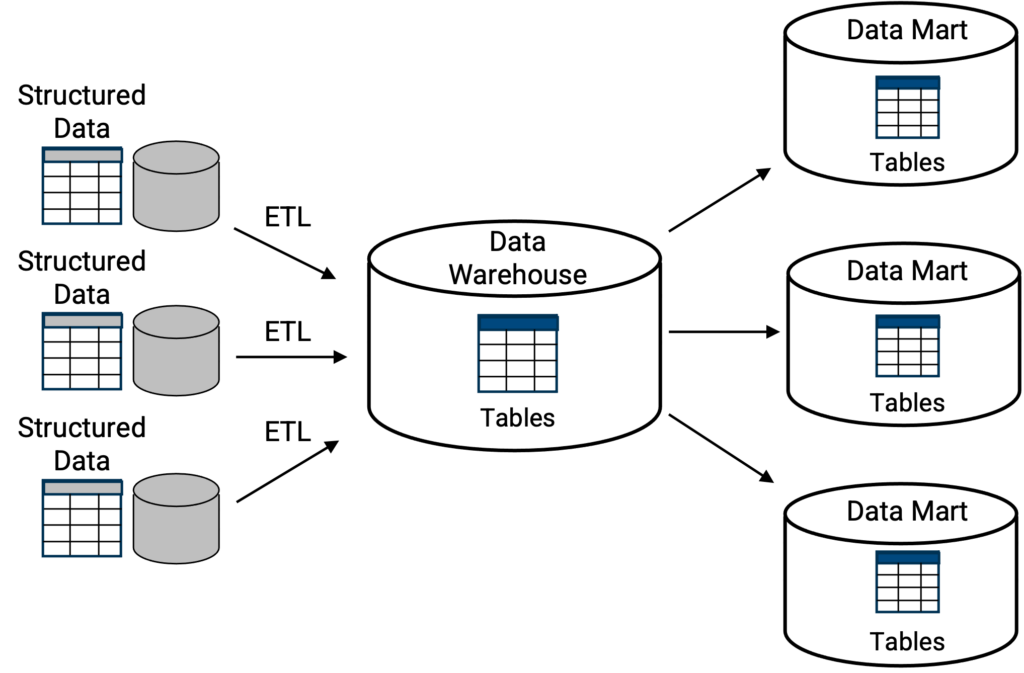
In alto, la classica topologia di data warehouse in cui una struttura di archiviazione primaria è una posizione centralizzata per una collezione di tabelle o database. Le funzionalità di interrogazione, solitamente SQL, sono integrate nel data warehouse. Come illustrato, i database o le tabelle possono essere replicati in data mart più piccoli, come sottoinsieme del data warehouse, dove ogni data mart ha una funzione specifica, come ad esempio un data mart finanziario, o un data mart produttivo, ecc.
Esempi di data warehouse classici sono Oracle, Teradata, Amazon Redshift, Azure Synapse - mentre l'implementazione può differire a seconda che il data warehouse classico sia distribuito on-premises o nel sito cloud.
Laghi di dati
Il vantaggio principale di un approccio architettonico di tipo data lake (nato nel 2010) è che si tratta di un'opzione più flessibile per fungere da repository centrale per più tipi di dati [Figura 2]. Tutti i tipi di dati, molti dei quali sono troppo ingombranti, troppo grandi in termini di volume totale o troppo variegati per essere gestiti efficacemente da un data warehouse classico.
Con i privilegi di accesso appropriati, tutte le comunità di professionisti dei dati (analisti aziendali, scienziati dei dati, ingegneri dei dati e così via) all'interno di un'azienda che devono lavorare con i dati e analizzarli devono utilizzare una varietà di metodi di interrogazione, a seconda del formato e della struttura dei dati da interrogare.
Tuttavia, questo ha un prezzo, che tradizionalmente è la complessità. Infatti, la sfida dei data lake consiste nel fatto che sono necessarie competenze specifiche, o un reparto IT completo, non solo per gestire tutti i diversi tipi di file di dati che finiscono in un data lake e per supportare i vari strumenti di interrogazione, ma anche per creare set di dati interrogabili, sotto forma di tabella, a partire dai file grezzi. Mentre l'accesso e la lettura o l'anteprima dei dati in un data lake possono essere relativamente semplici, il tentativo di interrogare un insieme di dati per ricavarne informazioni è un'altra questione e dipende dalla struttura dei dati.
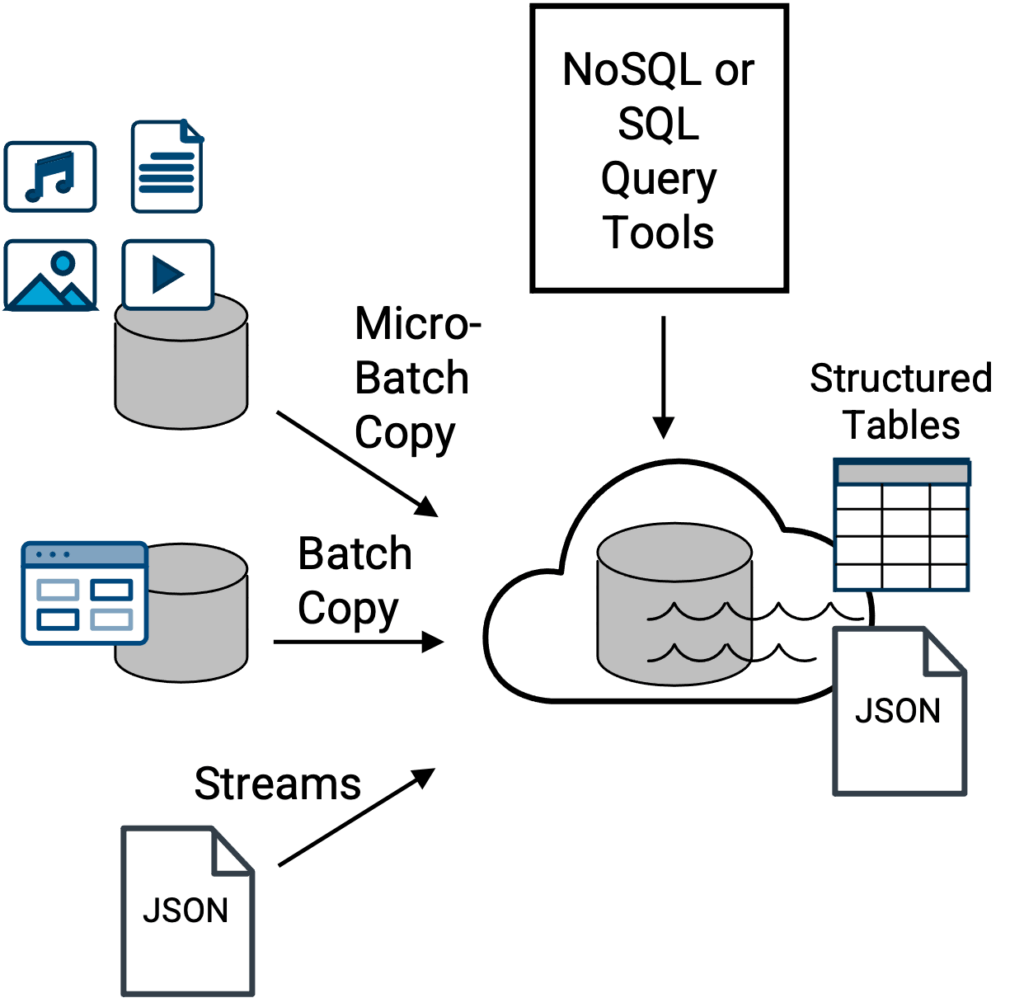
In alto, una topologia di data lake tradizionale in cui file e dati provenienti da una varietà di fonti vengono ingeriti nel data lake per essere archiviati, acceduti e potenzialmente interrogati in modo centralizzato tramite strumenti e motori di query SQL o NoSQL. Gli strumenti di interrogazione SQL lavorano con tabelle strutturate, mentre gli strumenti di interrogazione NoSQL lavorano con file di documenti JSON nativi. Esempi di data lake sono Amazon S3, Apache Iceberg, Azure Data Lake Storage (ADLS), Google Cloud Storagee Hadoop HDFS-basati sullo storage.
Ad esempio, dati completamente non strutturati come video, audio o immagini possono essere facilmente accessibili, visualizzabili in anteprima ed esplorabili come singoli file da un data lake, ma come si possono ottenere approfondimenti da 1.000 immagini, in modo semplice, e che tipo di strumento di interrogazione si potrebbe utilizzare?
Se siete in grado di rispondere rapidamente a questa domanda e di realizzarla, fate parte della piccola percentuale di persone che possono avere le competenze per farlo. [La risposta è che, nella maggior parte dei casi, vengono creati metadati sui dati non strutturati e questi diventano i dati che vengono analizzati alla ricerca di approfondimenti con strumenti SQL standard. I file non strutturati veri e propri possono essere convertiti o meno in una stringa di dati equivalente, a seconda del caso d'uso specifico dei dati non strutturati].
All'altro capo dello spettro ci sono i dati completamente strutturati, con righe e colonne, cioè una tabella. Qualsiasi analista di dati che disponga di uno strumento di interrogazione, in particolare di uno strumento di interrogazione SQL, può interrogare con una certa facilità 1.000 righe o colonne di dati e scoprire intuizioni. Al centro dello spettro ci sono i dati semi-strutturati o i file di documenti, come i file JSON. Al giorno d'oggi, i file JSON sono facili da esplorare e, sebbene non sia semplice e immediato come interrogare una tabella strutturata in modo completamente relazionale, i dati JSON possono essere interrogati con strumenti NoSQL, e ci sono molti strumenti popolari, che sono maturati enormemente dal 2010.
I professionisti dei dati, compresi i data scientist, possono affermare di apprezzare la flessibilità di esplorare, o visualizzare in anteprima, singoli file o set di dati. Tuttavia, quando arriva il momento di interrogare i dati e scoprire intuizioni e relazioni tra i dati, la maggior parte dei professionisti dei dati preferisce lavorare con database e tabelle strutturate (per un'esperienza simile a quella di un classico data warehouse) piuttosto che tentare di costruire una query su singoli file grezzi.
Per questo motivo, la creazione di un set di dati da file grezzi dovrà essere affidata a un tecnico dell'IT in grado di svolgere tale compito. Questo crea ritardi nella realizzazione del valore dei dati e crea oneri (e colli di bottiglia) per l'IT. Inoltre, senza un'adeguata governance e catalogazione, i data lake possono diventare una discarica di dati, la proverbiale palude dei dati. Nel corso degli anni, in assenza di strumenti adeguati, l'approccio dei data lake si è guadagnato la fama di essere eccessivamente complesso da implementare e gestire.
Un data warehouse classico su un data lake
Per la maggior parte delle aziende, i data lake tradizionali e i data warehouse classici di solito non esistono completamente separati l'uno dall'altro. I dati di un data lake possono essere caricati o trasferiti in un data warehouse (Figura 3). Non si tratta di un concetto nuovo, vista la sovrapposizione di data warehousing e data lake dal 2010.
Tuttavia, i requisiti e i casi d'uso dei dati aziendali, nonché le caratteristiche e le capacità specifiche del data warehouse classico, determineranno il grado di trasferimento. Ciò include se i dati devono essere strutturati o semi-strutturati, come i dati JSON in streaming, per i quali il data warehouse dovrà disporre di una funzione interna per trasformare, o appiattire, il file JSON dal suo formato nativo e talvolta gerarchico in un formato tabellare strutturato, come previsto dal data warehouse classico. Se il data warehouse non dispone di questa capacità, saranno necessari strumenti o processi esterni.
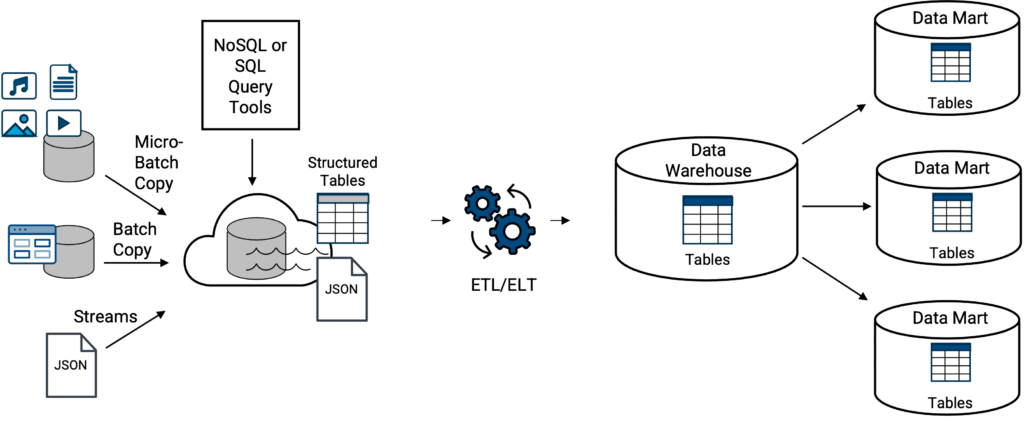
Sopra, gli esempi di data warehouse classico su un data lake includono uno qualsiasi dei tipi di data warehouse classico sopra citati accoppiato (integrato) con uno qualsiasi dei data lake sopra citati, Amazon Redshift su S3 (alias, Amazon Spectrum), Azure Synapse su ADLS, Google Big Query su Google Cloud Storage e Snowflake su S3 esterno (continuate a leggere).
Considerato lo spettro tra dati non strutturati e dati strutturati, i professionisti dei dati, compresi i data scientist, dichiareranno di apprezzare la flessibilità di esplorare singoli file o set di dati. Tuttavia, quando arriva il momento di interrogare i dati e scoprire intuizioni e relazioni tra i dati, la maggior parte dei professionisti dei dati preferisce lavorare con database e dati strutturati (come quelli di un classico data warehouse) piuttosto che tentare di costruire una query su singoli file grezzi.
Per questo motivo, la creazione di un set di dati da file grezzi e il trasferimento di dati da un data lake a un data warehouse classico dovranno essere affidati a una persona tecnica all'interno dell'IT con le competenze necessarie per svolgere questo compito. Poiché parte dell'attrattiva di un data lake è la possibilità di interrogare i dati direttamente nel lago, si ha l'impressione errata che non sia necessario creare set di dati interrogabili, che non sia necessario duplicare i dati e che si tratti solo di una questione di data warehouse. I set di dati strutturati e interrogabili sono altrettanto importanti in un data lake.
In generale, questo crea ritardi nella realizzazione del valore dei dati e crea oneri (e colli di bottiglia) per l'IT.
Data warehouse di nuova generazione cloud : data lakehouse
In soccorso ci sono i data warehouse cloud di nuova generazione, presenti sulla scena dal 2015. Oltre a supportare i comuni file CSV e altri formati, i data warehouse di nuova generazione cloud sono in grado di accettare e caricare file JSON (semi-strutturati) nel loro formato nativo (Figura 4). Da qui un data warehouse di nuova generazione può disporre di strumenti integrati per analizzare automaticamente i dati JSON, appiattire qualsiasi struttura di array e presentare una versione tabellare orientata alle colonne dei dati JSON, pronta per essere interrogata in modo relazionale con SQL standard, risolvendo una sfida critica con i data lake e i data warehouse classici su un approccio data lake. Le opzioni di piattaforma (di un fornitore) migliori e più ricche di funzionalità, oltre che scalabili e agili, per questo concetto saranno le soluzioni basate su cloud.
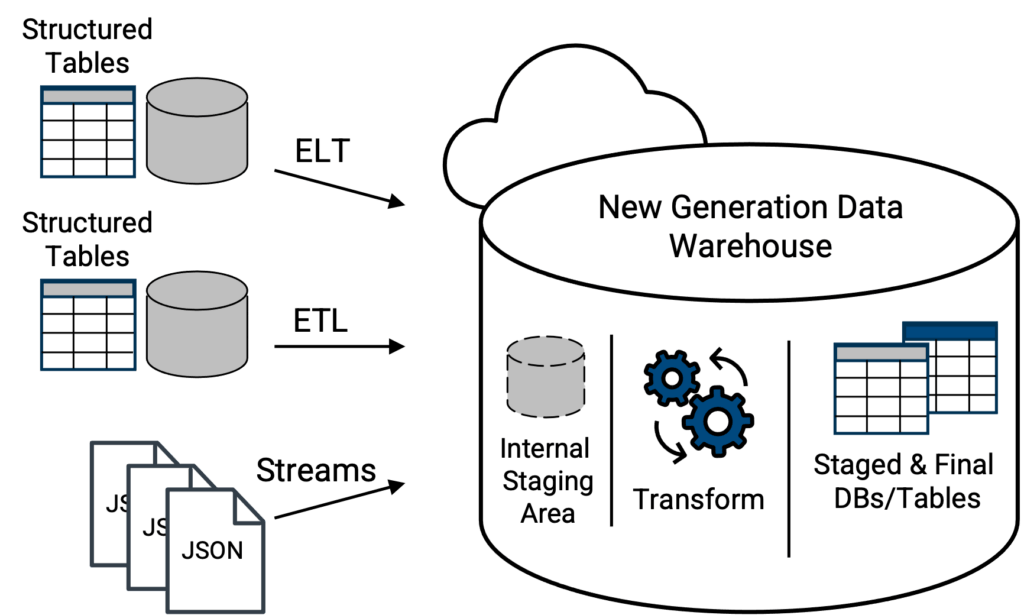
Sopra, topologia moderna in cui le tabelle di dati e i file JSON nativi vengono caricati direttamente in un data warehouse di nuova generazione. Le capacità dello strumento di integrazione dei dati per mobilitare i dati nel data warehouse determineranno se le tabelle di dati devono essere trasformate prima per corrispondere alla struttura dello schema della tabella di destinazione all'interno del data warehouse. Un data warehouse veramente moderno e di nuova generazione sarà in grado di analizzare il file JSON nativo al momento del caricamento e di trasformarlo in una tabella interrogabile. In questo modo, il file JSON non è più nel suo formato nativo letterale, ma i suoi dati saranno in una forma che può essere interrogata dal data warehouse di nuova generazione con SQL standard.
Poiché il livello di storage è spesso separato dal livello di calcolo, le nuove generazioni di data warehouse cloud (o piattaforme di dati, come vengono talvolta chiamate) possono essenzialmente offrire un'esperienza integrata di data lake e data warehouse all-in-one, creando il concetto di data lakehouse. Questo design elimina parte della complessità degli approcci tipici ai data lake. Ne sono un esempio Snowflake e Databricks Delta.
Inoltre, la separazione dei livelli di calcolo e di archiviazione consente a questi due gruppi di risorse di scalare in modo indipendente e di utilizzare elementi di archiviazione a basso costo, riducendo il costo per terabyte dell'archiviazione rispetto agli approcci classici dei data warehouse che bloccano i dati e le risorse di calcolo durante la scalata.
Con la tecnologia di data warehousing di nuova generazione che esegue tutto il lavoro pesante per trasformare i file di dati non relazionali in una struttura relazionale, gli analisti di business, i data scientist e i data engineer possono estrarre valore da quei dati molto più velocemente, in modalità self-service. Inoltre, le tabelle formattate con colonne per i dati JSON consentono in genere di ottenere analisi più rapide quando sono necessarie query relazionali complesse, rispetto all'utilizzo di strumenti di query NoSQL con JSON in forma di documento nativo.
Inoltre, alcuni data warehouse di nuova generazione, o data lakehouse, offrono un'area interna di stoccaggio (holding), dove i file JSON possono essere trasferiti e rimanere nella loro forma nativa. Ad esempio, Snowflake dispone di un'area di staging S3 interna, separata dall'infrastruttura di archiviazione degli oggetti per i suoi data warehouse virtuali. Tuttavia, i dati JSON non saranno interrogabili fino a quando non saranno caricati nel lakehouse e trasformati. Attenzione, non tutti i lakehouse offrono questa capacità di staging all'interno della stessa struttura fisica.
Nel complesso, l'approccio di progettazione della lakehouse elimina gran parte della complessità degli approcci tipici dei data lake, ma presenta anche degli svantaggi.
Uno: più grande è l'azienda e più numerosi sono i professionisti dei dati, più è probabile che i singoli gruppi non preferiscano operare tutti con la stessa soluzione di data warehouse o data lakehouse. In secondo luogo, i principali fornitori di data lakehouse tendono a utilizzare una tariffazione basata sul consumo, il che significa che il contatore è sempre in funzione con l'utilizzo del data lakehouse.
Se tutti sono ammassati in una lakehouse o in un data warehouse di nuova generazione con prezzi a consumo, è necessario monitorare le risorse e assicurarsi che siano spente quando non vengono utilizzate. Inoltre, è necessario disporre di avvisi per notificare l'attivazione di soglie di utilizzo o di costo.
Di conseguenza, le aziende stanno scoprendo che la soluzione più flessibile consiste nel far coesistere un data lake basato su cloud e un data warehouse di nuova generazione cloud , lakehouse, piuttosto che un data warehouse classico affiancato. Questo approccio consente al data lake di essere il contenitore principale per tutti i dati, servendo tutte le comunità e massimizzando la flessibilità.
Cosa cercare in uno strumento di integrazione dei dati
I moderni strumenti di integrazione dei dati possono rendere più semplice e automatica la mobilitazione di grandi quantità di dati in entrata o in uscita da uno dei concetti di data warehouse, data lake o data lakehouse. Questi strumenti consentono di ottenere dati da un'ampia varietà di fonti. Ciò consente di risparmiare tempo e fatica nel preparare i dati per l'analisi, accelerando così i progetti di analisi.
I moderni strumenti di integrazione dei dati assicurano anche che i dati siano nel formato e nella struttura corretti, il che rende più semplice l'interrogazione e l'analisi. Inoltre, questi strumenti sono spesso dotati di funzioni che aiutano a mantenere i dati sicuri e conformi alle normative.
Quando si configura per la prima volta una piattaforma di dati aziendali, si deve optare per uno strumento di integrazione dei dati che sia facile e intuitivo da usare. L'ideale è optare per uno strumento con funzionalità drag-and-drop e la possibilità di trasformare visivamente i dati all'interno della piattaforma, in modo da facilitare il lavoro con i dati a diversi livelli di competenza. Per saperne di più su come integrare e automatizzare i dati in tutta l'azienda.








