






This blog breaks down data warehouse, data lake, and data lakehouse concepts and how they compare and contrast, as well as the benefits of each approach. The scope of this blog is to provide a high-level, architecture summary view.
Classic data warehouses
As the long-time workhorse of the business intelligence and data analytics world, the classic data warehouse concept has existed since the 1980s and the popularity of data warehouse as a business tool is largely credited to American computer scientist Bill Inmon. Inmon, often considered the “father” of data warehousing, originally defined the data warehouse as “a subject-oriented, nonvolatile, integrated, time-variant collection of data in support of management’s decisions.”
Data warehouses became, and remain, popular tools for enterprises everywhere because they provide companies with the ability to analyze data and changes over time, create insights, and arrive at conclusions that help shape business decisions.
Classic data warehouses [Figure 1] typically operate as central repositories where information, i.e., data, arrive from internal business units, external business partners, sales operations, manufacturing operations, and a wealth of other sources. The goal and benefit of data warehousing is to collect all this information, store it, aggregate it, and have a holistic view of a business to form more complete and more comprehensive intelligence about the business. The more rapidly a data warehouse can help users and executives create or report on intelligence the better.
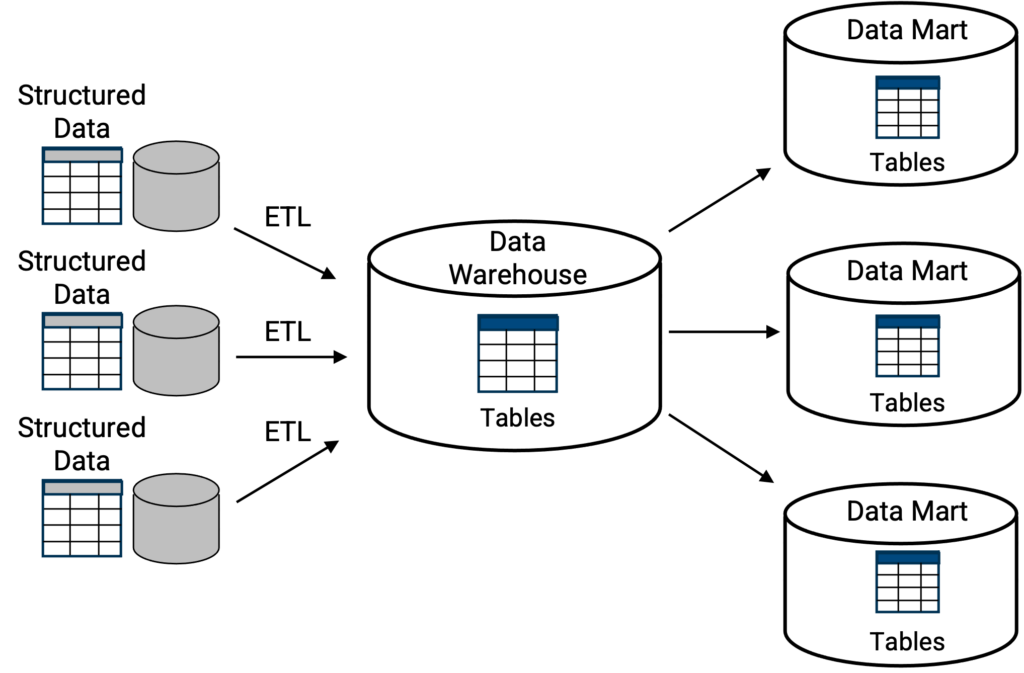
Above, the classic data warehouse topology where a primary storage structure is a centralized location for a collection of tables or databases. Query capabilities, usually SQL, are natively built into the data warehouse. As shown, databases or tables may be replicated into smaller data marts, as a subset of the data warehouse, where each data mart serves a specific function, such as a finance data mart, or a manufacturing data mart, etc.
Examples of classic data warehouses include Oracle, Teradata, Amazon Redshift, Azure Synapse ― while deployment implementation may differ as to whether the classic data warehouse is deployed on-premises or in the cloud.
Data lakes
The primary advantage of a data lake architecture approach (originated in 2010) is that it is a more flexible option to serve as a central repository for more types of data [Figure 2]. All kinds of data, much of which are too cumbersome, too large in terms of total volume, or too varied for a classic data warehouse to handle effectively, with handle effectively [if handled at all] being the key point.
With the appropriate access privileges, all communities of data professionals (business analysts, data scientists, data engineers, etc.) within a company that must work with and analyze the data must use a variety of query methods, dependent on the format and structure of the data being queried.
However, this comes at a price ― that price traditionally has been complexity. This is because the challenge with data lakes is that it takes special skill, or a complete IT department, to not only manage all the different types of data files that land in a data lake and support the various query tools, but also to create query-able datasets, in the form of a table, from raw files. While accessing and reading or previewing data in a data lake may be relatively straightforward, attempting to query a set of data to gain insights from it is another matter and depends on the structure of the data.
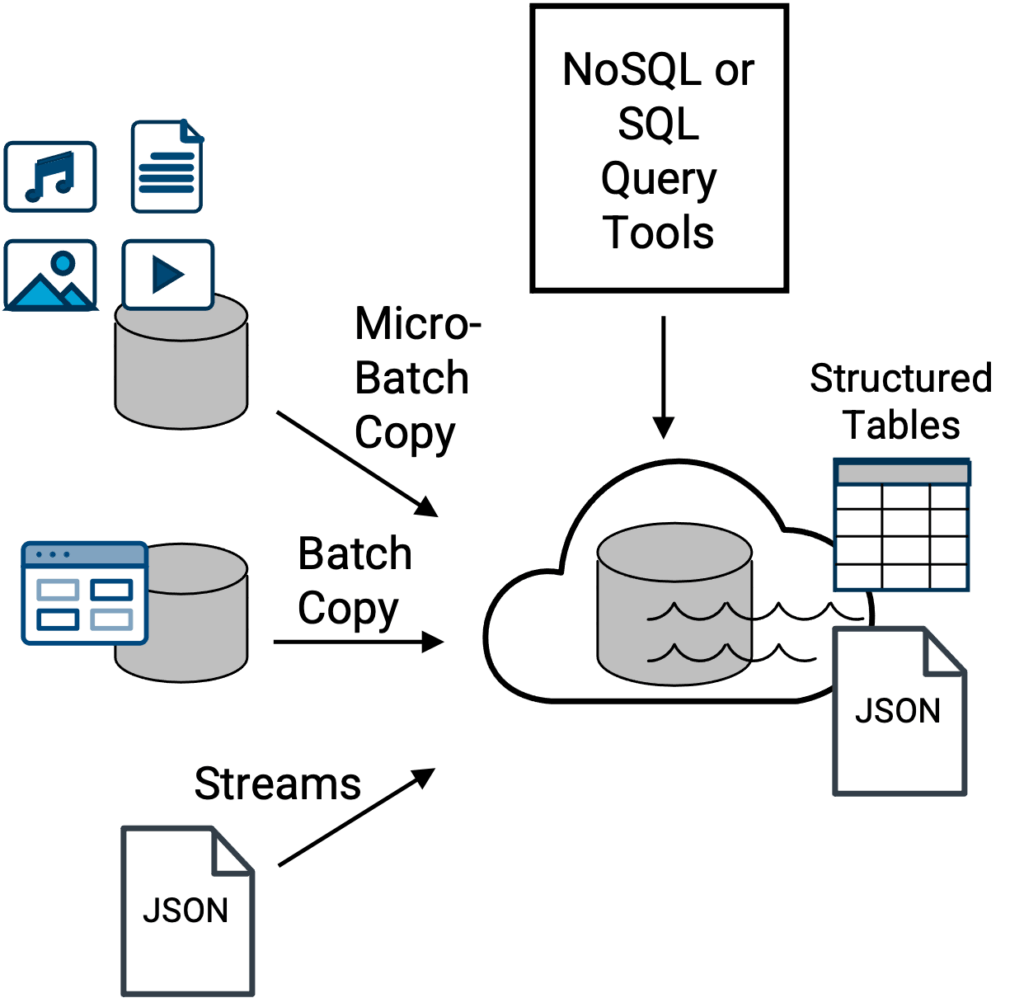
Above, traditional data lake topology where files and data from a variety of sources are ingested into the data lake for centralized storage, access, and potentially, subsequent querying via SQL or NoSQL query tools and engines. SQL query tools will work with structured tables, whereas NoSQL query tools will work with native JSON document files. Examples of a data lake include Amazon S3, Apache Iceberg, Azure Data Lake Storage (ADLS), Google Cloud Storage, and Hadoop HDFS-based storage.
For example, completely unstructured data such as video, audio, or images may be easy to access, preview, and explore as individual files from a data lake, but how would you gain insights from 1,000 images, easily, and what type of query tool would you use?
If you are able to answer this question quickly and make it happen, count yourself among the small percentage of individuals who may have the skills to do so. [The answer is, in most cases, metadata about the unstructured data is created and this becomes the data that is scanned for insights with standard SQL tools. The actual unstructured files may or may not be converted to a data string equivalent, dependent on the specific use case for the unstructured data.]
On the other end of the spectrum is completely structured data, with rows and columns, i.e. a table. Just about any data analyst with a query tool, specifically a SQL query tool, could fairly easily query 1,000 rows or columns of data and uncover insights. In the middle of the spectrum is semi-structured data or document files, such as JSON files. These days, JSON files are easy to explore, and while not as easy and straightforward as a structured table to query in a fully relational manner, JSON data can be queried with NoSQL tools, and there are many popular tools, of which have matured tremendously since 2010.
Data professionals, including data scientists, may indicate they enjoy the flexibility to explore, or preview, individual files or sets of data. However, when it comes time to query data and uncover insights and relationships amongst the data, most data professionals would prefer to work with databases and structured table data (for an experience similar to that of a classic data warehouse) rather than attempt to construct a query across individual raw files.
For this reason, creation of a dataset from raw files will have to be directed to a technical person within IT with the skill to do such a task. This creates time delays in realizing value from the data and it creates burdens on (and bottlenecks through) IT. In addition, without proper governance and cataloging, data lakes can become a dumping ground for data — the proverbial data swamp. Over the years, without proper tooling, the data lake approach has garnered a notorious reputation for being overly complex to implement and manage.
Classic data warehouse on a data lake
For most enterprises, traditional data lakes and classic data warehouses normally do not exist completely separate from each other. Data from a data lake may be loaded or transferred into a data warehouse, Figure 3. This is not a new concept, given the overlap of data warehousing and data lakes since 2010.
However, enterprise data requirements and use cases, as well as the specific features and capabilities of the classic data warehouse, will dictate how much transferring takes place. This includes whether the data must be structured data or semi-structured data, such as streamed JSON data, of which the data warehouse will have to have some internal function to transform, or flatten, the JSON file from its native and sometimes hierarchical document format into a structured data table format as expected by the classic data warehouse. If the data warehouse does not have this capability, external tooling or processes will be required.
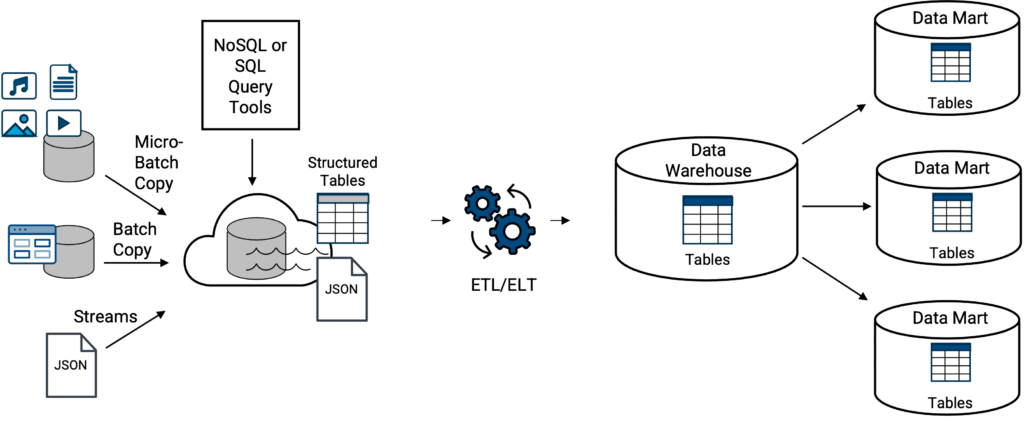
Above, examples of classic data warehouse on a data lake include any of the aforementioned classic data warehouse types loosely coupled (integrated) with any of the aforementioned data lakes, Amazon Redshift on S3 (aka, Amazon Spectrum), Azure Synapse on ADLS, Google Big Query on Google Cloud Storage, and Snowflake on external S3 (keep reading).
Given the spectrum between unstructured data and structured data, data professionals, including data scientists, will indicate they enjoy the flexibility to explore individual files or sets of data. However, when it comes time to query data and uncover insights and relationships amongst the data, most data professionals would prefer to work with databases and structured data (like that of a classic data warehouse experience) rather than attempt to construct a query across individual raw files.
For this reason, creation of a dataset from raw files, and transfers of data from a data lake to classic data warehouse, will have to be directed to a technical person within IT with the skill to do such a task. Because part of the appeal of a data lake is to query data directly in the lake, it is a misperception that creation of query-able data sets will not be required, that it won’t necessitate duplication of data, and that this is only a data warehouse thing. Structured, query-able data sets are just as important within a data lake.
Overall, this creates time delays in realizing value from the data and it creates burdens on (and bottlenecks through) IT.
New-generation cloud data warehouses: data lakehouses
To the rescue are new-generation cloud data warehouses, on the scene since 2015. In addition to supporting common CSV files and other formats, new-generation cloud data warehouses can accept and load JSON (semi-structured) files in their native format, Figure 4. From here a new generation data warehouse may have the built-in tooling to automatically parse the JSON data, to flatten any array structures, and present a column-oriented table version of the JSON data, ready to be queried in a relational manner with standard SQL, solving a critical challenge with data lakes and classic data warehouses on a data lake approaches. The best and most functionality rich, as well as scalable and nimble, platform options (from a vendor) for this concept will be cloud-based solutions.
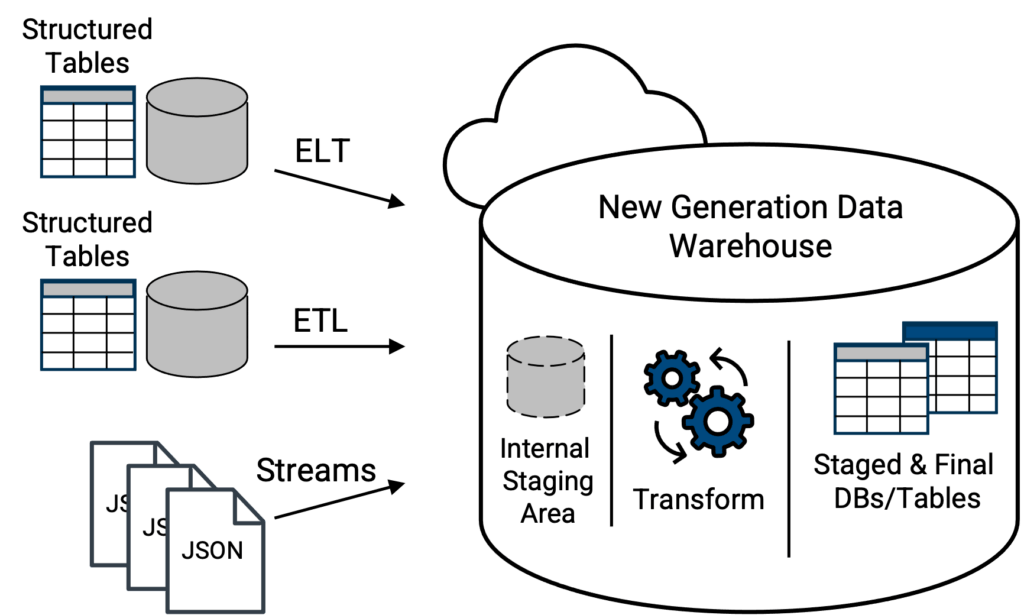
Above, modern topology where data tables and native JSON files are directly loaded in a new generation data warehouse. Capabilities of the data integration tool to mobilize data to the data warehouse will dictate whether data tables must be transformed first to match the schema structure of the target table within the data warehouse. A truly modern, new-generation data warehouse will have the ability to scan the native JSON file upon loading and transform it into a query-able table form. As such, the JSON file is no longer in its literal native format, but its data will be in a form that can be queried by the new generation data warehouse with standard SQL.
Because the storage layer is often separate from the compute layer, new generations of cloud data warehouses (or data platforms as they are sometimes called) can essentially offer an integrated data lake and data warehouse all-in-one package experience – creating the data lakehouse concept. This design removes some of the complexity of typical data lake approaches. Examples include Snowflake and Databricks Delta.
In addition, separate compute and storage layers enables these two resource groups to independently scale and use lower cost storage elements, lowering the per-terabyte cost of storage compared to classic data warehouses approaches that lock data and compute resources as they scale.
With the new-generation data warehousing technology performing all the heavy lifting to transform non-relational data files into a relational structure, business analysts, data scientists, and data engineers can extract value from that data much faster, with self-service. In addition, column-formatted tables for the JSON data will generally deliver faster analytics when complex relational querying is required, compared to using NoSQL query tools with JSON in native, document form.
Further, some new-generation data warehouses, or data lakehouses, offer an internal storage staging (holding) area, where JSON files can be transferred to and remain in their native form. For example Snowflake has an internal S3 staging area that is separate from object storage infrastructure for their virtual data warehouses. However, the JSON data will not be query-able until they are loaded into the lakehouse and transformed. Caution, not all lakehouses offer this staging capability within the same physical structure.
Overall, the lakehouse design approach removes a lot of the complexity of typical data lake approaches, but it too has disadvantages.
One, the larger the company and the more data professionals there are, the more likely individual groups may not all prefer to operate within the same data warehouse or data lakehouse solution. Two, leading lakehouse vendors tend to employ consumption based pricing, meaning the meter is always running with usage of the lakehouse.
If everyone is piled into a lakehouse/new-generation data warehouse with consumption pricing, care must be taken to monitor resources and ensure resources are turned off when not in use. Plus, have alerts in place to notify when usage or cost thresholds are triggered.
Consequently, companies are discovering that the most flexible arrangement is to have a cloud-based data lake and a new generation cloud data warehouse, lakehouse, co-existing side-by-side, rather than a classic data warehouse side-by-side. This approach enables the data lake to be the primary holding bin for all data while serving all communities and maximizing flexibility.
What to look for in a data integration tool
Modern data integration tools can make it easier and more automated to mobilize large amounts of data into or out of any of the concepts, data warehouse, data lake, or data lakehouse. These tools let you get data from a wide variety of sources. This saves time and effort when getting the data ready for analytics, so you can accelerate analytics projects.
Modern data integration tools also ensure that the data is in the right format and structure, which makes it simpler to query and analyze. Plus, these tools often have features that help keep data secure and compliant with regulations.
When setting up an enterprise data platform for the first time, opt for a data integration tool that’s easy and intuitive to use. Ideally, opt for a tool with drag-and-drop functionality and the ability to transform data visually inside the data platform, making it easy for a variety of skill levels to work with data. Learn more about how to integrate and automate data across your enterprise.








