






Nell'odierno panorama basato sui dati, la capacità di creare una piattaforma di analisi scalabile ed efficiente non è solo vantaggiosa, ma essenziale. In SnapLogic, con un volume enorme di dati generati da miliardi di esecuzioni di pipeline ogni mese, abbiamo affrontato questa sfida in prima persona. La necessità andava oltre la semplice visualizzazione: avevamo bisogno di analisi approfondite e informazioni utili. Questo post del blog approfondirà il nostro approccio innovativo, che sfrutta l'architettura Medallion, per progettare e implementare una piattaforma di analisi scalabile che consenta agli utenti di estrarre informazioni preziose e prendere decisioni informate.
Descrizione del problema
La precedente analisi dei dati di SnapLogic, basata principalmente su MongoDB, aveva difficoltà a gestire l'enorme mole di dati generati da miliardi di esecuzioni mensili della pipeline, causando problemi di scalabilità e costi. I limiti di MongoDB ostacolavano le query analitiche complesse, la trasformazione dei dati, la governance e la modellazione efficiente dei dati. Queste sfide hanno reso necessario il passaggio a una soluzione più scalabile ed economica come l'architettura Medallion con S3 e Trino per gestire il volume e la complessità crescenti dei dati e ottenere migliori approfondimenti analitici e processi decisionali.
L'architettura
La nostra architettura integra l'approccio medaglione con una combinazione di tecnologie volte a migliorare l'elaborazione e l'analisi dei dati.
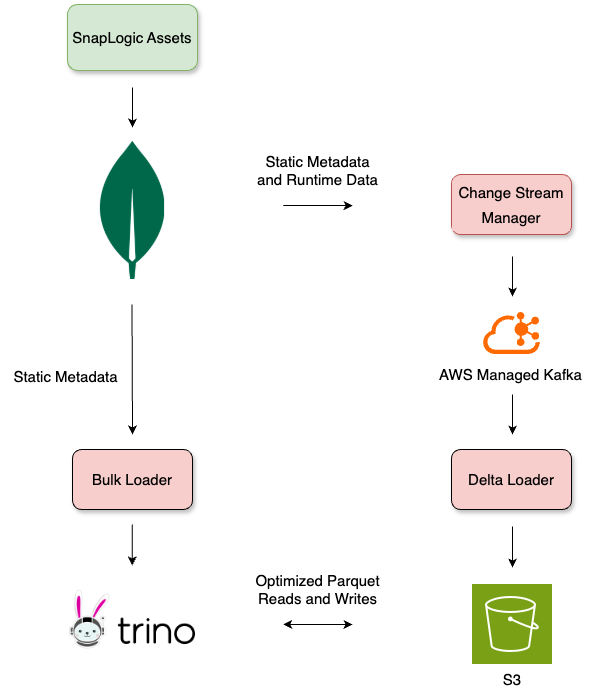
Fonti dei dati e acquisizione
MongoDB funge da nostra fonte di dati primaria e utilizziamo due metodi per l'estrazione dei dati, archiviandoli in S3 in formato parquet. Il caricamento in blocco comporta l'acquisizione di un'istantanea di MongoDB in un dato momento e la sua importazione nel livello bronzo dell'architettura medaglione utilizzando Trino. SnapLogic supporta oltre 1000 organizzazioni, gestendo circa 64 milioni di aggiornamenti di dati in tempo reale ogni giorno tramite MongoDB Change Streams. Per garantire un throughput elevato e la tolleranza ai guasti, questi flussi di modifiche vengono elaborati da delta loader e trasmessi tramite Apache Kafka (MSK). I dati estratti vengono partizionati e archiviati in S3 per uno storage economico e scalabile, e successivamente accessibili utilizzando Trino.
Architettura dei medaglioni / Trasformazioni
L'architettura Medallion è un modello di progettazione dei dati che organizza i dati in modo logico per migliorarne progressivamente la struttura e la qualità. L'architettura organizza i dati in diversi livelli (Bronzo, Argento, Oro) per soddisfare le esigenze dei vari stakeholder. Le architetture Medallion sono talvolta denominate anche architetture multi-hop. Ciò fornisce una visione completa e ben governata dei dati, dall'acquisizione dei dati grezzi ai formati pronti per l'uso per l'analisi e la reportistica.
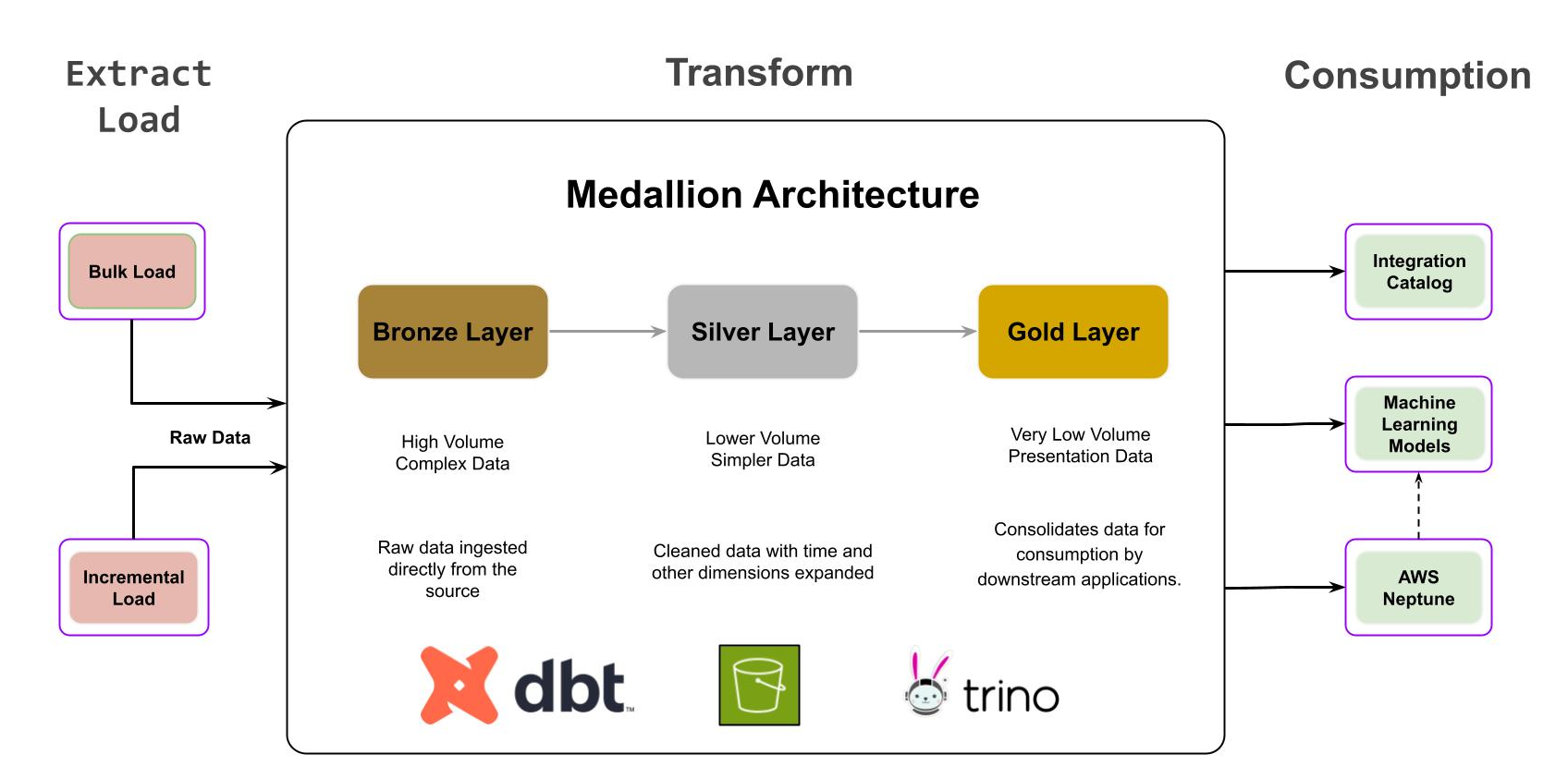
I dati di runtime generati dalle esecuzioni della pipeline e i flussi di modifica dei metadati statici vengono analizzati utilizzando Trino, un motore di query SQL distribuito che interroga in modo efficiente i dati archiviati in S3. Abbiamo ottimizzato lo schema dei dati in S3 per consentire a Trino di eseguire query in modo efficiente, tenendo conto di fattori quali la partizionatura e la compressione dei dati.
Per implementare l'approccio basato su medaglioni per le trasformazioni, utilizziamo pipeline SnapLogic basate su DBT che rappresentano vari livelli. Queste pipeline vengono eseguite su plex DBT Ground personalizzati per trasformare e perfezionare i dati, garantendone la qualità e preparandoli per l'utilizzo da parte di applicazioni a valle come Asset Catalog e grafici di conoscenza, al fine di arricchire i nostri modelli ML a valle.
L'architettura Medallion è composta da livelli distinti, ciascuno con funzioni specifiche. Il livello Bronze acquisisce i dati da S3 e li trasferisce al livello Silver, dove vengono sottoposti a pulizia e perfezionamento tramite normalizzazione. Successivamente, il livello Gold consolida i dati utilizzando i join eseguiti sul livello Silver, rendendoli prontamente accessibili per l'utilizzo da parte delle applicazioni a valle.
Consumo
Lo strato oro, che funge da strato di presentazione, contiene dati fattuali, operativi e dedotti utilizzati da due sistemi primari.
Il Catalogo delle risorse funge da Sistema di registrazione centrale (SoR) per tutte le pipeline SnapLogic, consentendo l'individuazione, la comprensione e la governance delle risorse di integrazione attraverso metadati esposti (attributi fattuali, dedotti e integrati relativi a attività, pipeline e account).
I dati contenuti nelle tabelle dello strato Gold vengono sincronizzati con un modello di dati basato su grafici in Amazon Neptune. Questo modello basato su grafici rappresenta le interrelazioni tra le risorse, inclusi pipeline, account, snapshot e file. Ogni tipo di risorsa è rappresentato da nodi, mentre i bordi indicano dipendenze e relazioni.
Considerazioni chiave durante l'implementazione
- Sovraccarico dell'estrazione dei dati
L'estrazione iniziale dei dati e l'acquisizione continua dei dati modificati richiedono un'attenta pianificazione e ottimizzazione.
e sulla coerenza dei dati È fondamentale mantenere la coerenza dei dati tra MongoDB e la nuova architettura.
e sulla complessità dell'architettura La gestione di un'architettura multicomponente richiede competenze specifiche e una manutenzione continua.
Vantaggi della nuova architettura
- Riduzione dei costi: S3 Data Lakehouse riduce al minimo le spese di archiviazione e query, con costi legati principalmente all'infrastruttura di Trino.
- Scalabilità e prestazioni: l'architettura Medallion con S3 e Trino consente un'elaborazione e un'analisi efficienti di grandi set di dati, superando le precedenti analisi basate su MongoDB.
- Gestione dei dati semplificata: l'architettura Medallion migliora l'organizzazione dei dati con livelli definiti (Bronzo, Argento, Oro) per garantire resilienza, riutilizzabilità e prestazioni ottimizzate per casi d'uso specifici.
- Analisi dei dati avanzata: il modello grafico di Neptune consente analisi complesse delle relazioni, migliorando la valutazione dell'impatto e il tracciamento della provenienza. Gli schemi S3 ottimizzati per Trino aumentano ulteriormente la velocità delle query.
- Miglioramento della governance dei dati e della conformità: l'approccio a più livelli offre una chiara visibilità della provenienza dei dati, facilitando gli sforzi di governance e conformità.
- Maggiore riutilizzabilità dei dati e velocità di sviluppo: i livelli Silver e Gold ben modellati possono essere riutilizzati in diversi progetti, riducendo la ridondanza e accelerando la creazione di entità aziendali.
Conclusione
In sintesi, abbiamo implementato una piattaforma di analisi robusta e scalabile utilizzando l'architettura Medallion, passando da un'analisi incentrata su MongoDB a un approccio più efficiente, economico e basato sui dati utilizzando S3 e Trino. Questa architettura ha migliorato la gestione dei dati, ottimizzato le prestazioni, consentito una modellazione dei dati più approfondita e rafforzato la governance dei dati. In prospettiva, miriamo a automatizzare ulteriormente le pipeline di trasformazione e a integrare più modelli di machine learning nei nostri livelli di elaborazione dei dati per promuovere l'analisi predittiva. Inoltre, stiamo esplorando miglioramenti nell'elaborazione dei dati in tempo reale e ampliando le nostre capacità di data lakehouse per supportare una gamma più ampia di fonti di dati e carichi di lavoro analitici, garantendo che la nostra piattaforma rimanga all'avanguardia nell'innovazione dei dati.








